
0 просмотренных постов скрыто



Сторонние сервисы на страже вашего приложения. Делаем локальное приложение доступным публично
Разрабатывая шикарное приложение, которое позволит мне попасть на первые страницы журнала форбс (нет) я столкнулся с интересной ситуацией. Мне надо было, чтобы внешний сервис отправлял данные моему приложению, которое было запущенно на моем компьютере. И куда теперь этому стороннему сервису стучаться? На localhost?

Ну я же не осел, хотя…
Забурившись в гуиды я понял, что есть два решения данной проблемы, первый заключается в пробросе портов, а второй в использовании сторонних сервисов. Я решил не мучать себя и не разбираться в пробросе портов, поэтому второй вариант – мой выбор.
Так вот, углубившись по самое не могу в этот ваш интернет и языковые модельки я нашел сервис, который называется ngrok (ссылку не буду оставлять, без проблем самостоятельно найдете в интернете), который позволял для выбранного порта (3000, 8080, 8081 и т.д.) получить публичный url адрес. Ну и усе, теперь я могу этот публичный url адрес указывать где угодно и когда угодно, ведь я уже взрослый.

Е бой
Давайте приведу непосредственно примеры использования функционала ngrok. Если вы создаете телеграм мини-приложение, как это сделал я, встроив чат-рулетку в тг t.me/Socionyx_Bot/socionyx (это что, опять нативная интеграция? Затестите пацантре, норм получилось), вам для запуская приложения через бота, в настройках же бота, понадобится указать url адрес. Вы либо указываете url адрес, который приобрели у соответствующего провайдера за денежку (об этом я писал тутъ). Либо, как вы уже догадались, используете url от ngrok, для тестирования вашего приложения этого будет более чем достаточно. Еще один способ использования заключается в том, что кроме url ngrok позволяет сгенерировать вам ssh, который я использовал для удаленного доступа к своей raspberry pi (о чем я хочу рассказать в отдельном цикле статей).

Ну все понятно же, да?
Но, пришла беда, откуда не ждали. Сервис ngrok стал блокировать доступ с российских ip адресов, плак-плак.

А почему бы и да?
Благо, альтернатива нашлась достаточно быстро и неожиданно, я всего лишь стал использовать старый советский…Visual Studio Code. Оказалось, что эта среда разработки позволяет также получать внешний url адрес для необходимым вам портов. В терминале выберите вкладку port, затем нажмите на Forwar a Port, после чего укажите необходимый для внешнего доступа порт.
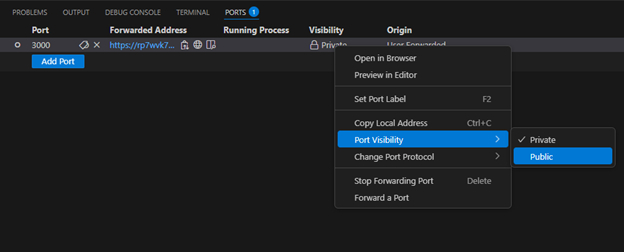
Необходимо обязательно в графе Visibility поменять видимость, с Private на Public
После всех манипуляций вы без проблем сможете использовать url адрес из графы Forwarded Address для ваших темных делишек, хе-хе-хе (нет).
А на этом все, пасаны и пасанята, не забываем, у меня есть telegram канал t.me/socionyxchannel, где я пишу про будни разработчика.
Показать полностью
4

MAX, через годик - два наберешь, пока до свидания
Показать полностью
1
Допустим заблокируют WhatsApp - в MAX выстроится очередь?

При этом блогер счел, что в России нет необходимости ограничивать Telegram. Он назвал мессенджер, разработанный компанией Павла Дуроваа, неплохой платформой, к которой россияне привыкли.
Показать полностью
1
Макс, давай до свидания

Показать полностью
1
