JPEG2000 на пальцах. Часть 2. Арифметическое кодирование
Доброй ночи, пикабушники!
Продолжаю серию статей про JPEG2000
Прошлый пост был про вейвлеты: http://pikabu.ru/story/jpeg2000_na_paltsakh_chast_1_veyvlety...
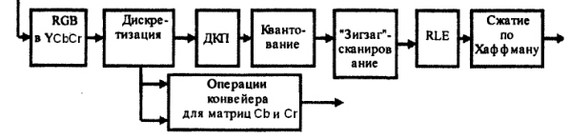
В этой статье будет описан алгоритм арифметического кодирования. В JPEG2000 вместо Хаффмана используется более эффективное арифметическое сжатие. Алгоритм Хаффмана хорошо сжимает, если частоты появления символов пропорциональны степени двойки. В реальности такая ситуация не всегда возможна — символы встречаются в различных пропорциях. Арифметическое кодирование решает эту проблему, так как коды присваиваются не символам, а их последовательностям.
Теперь немного о том, как это работает.
Есть строка: Пикабу—лучший_ресурс
(Пробел заменен на подчеркивание)
Подсчитаем количество букв и выделим частотные интервалы для них на промежутке [0;1].
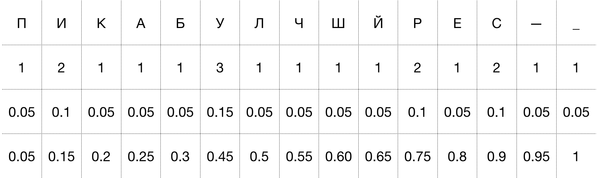
Пояснение: первая строка — буква, вторая — частота символа, третья — вероятность возникновения (частота / количество символов в строке), четвертая — граница интервала справа.
Попробуем закодировать слово “ПИКАБУ”. Возьмем первый символ “П” и принимаем его границы [0;0.05) за начало отсчета. Для кодирования следующего символа “И” нужно пересчитать границы по формулам:
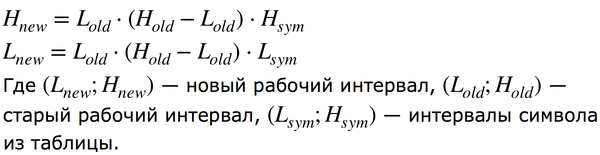
Для слова “ПИКАБУ” получаем следующие результаты:
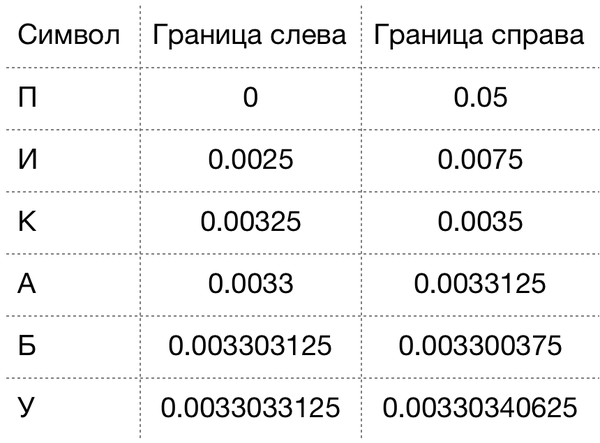
Теперь попробуем декодировать этот результат. Для этого будем использовать левую границу последнего символа — 0.0033033125. Обращаемся к исходной таблице и видим, что это число лежит в диапазоне [0;0.05), а значит это “П”.
Теперь попробуем получить следующий символ. Мы уже знаем, что первый символ — “П”, а значит знаем и его границы. Если подставить известные данные в формулу ниже, то будет известен новый интервал:

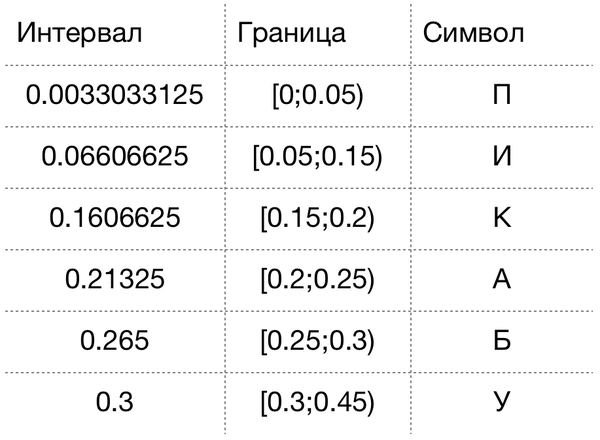
Новый интервал 0.06606625 лежит в пределах [0.05;0.15), что соответствует символу “И”. В таблице ниже результат для всего слова.
Теперь Вы владеете основами арифметического кодирования :)
За кадром, как всегда, осталась масса различных математических нюансов. Надеюсь, что Вам было интересно и Вы узнали что-то новое.