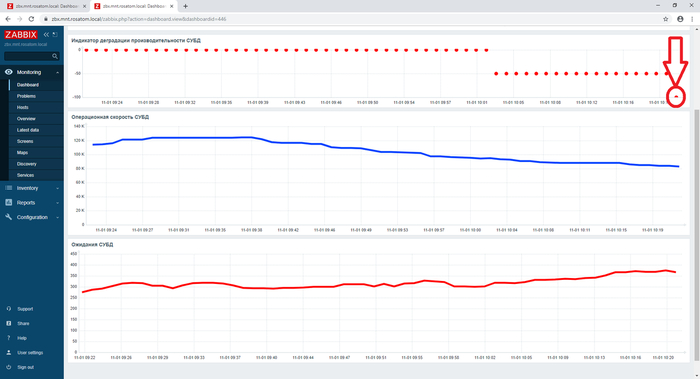
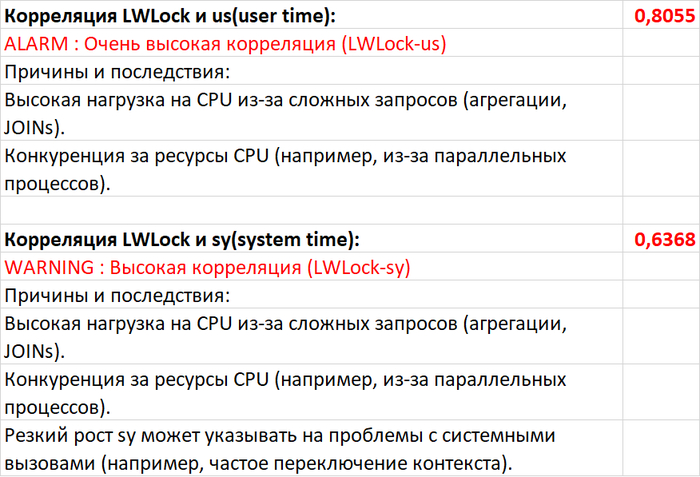
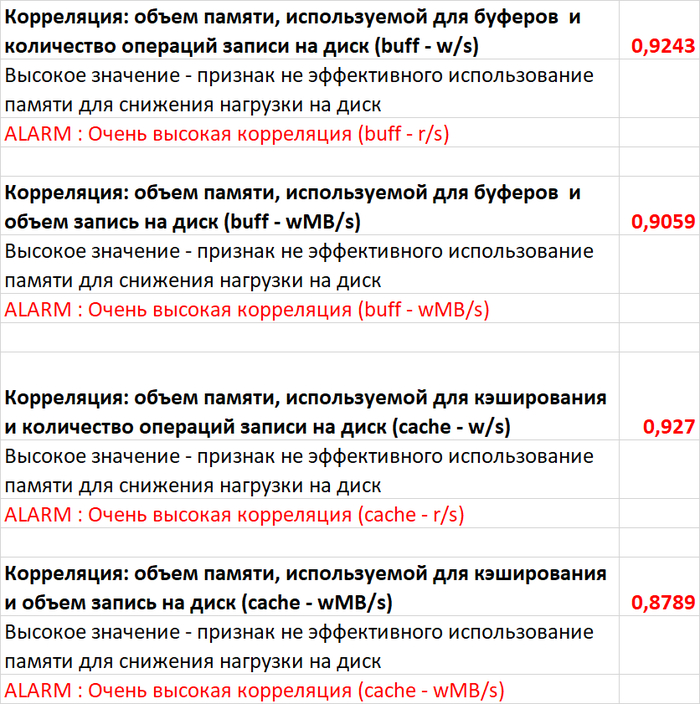
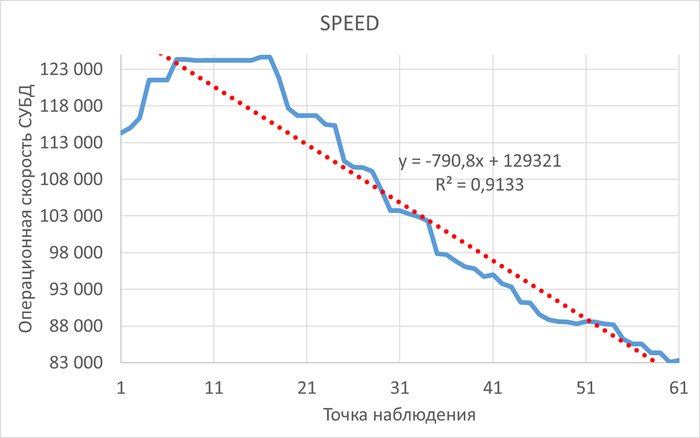
Являются ли ожидания типа IO необходимым и достаточным условием отсутствия индекса? Мнение нейросетей и эксперимент - нехватка индексов
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

В мире баз данных очевидное часто обманчиво, а простое объяснение — скорее исключение, чем правило.
Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Предисловие
В эпоху, когда нейросети становятся первым источником знаний для многих разработчиков, особенно важно проверять их утверждения на практике. Один из таких вопросов — прямая связь между типами ожиданий в PostgreSQL и отсутствием индексов. AI-помощники часто дают логичные, но упрощённые ответы, которые могут ввести в заблуждение при решении реальных задач оптимизации. В этой статье мы проверим экспериментально, насколько обоснованно распространённое мнение о том, что IO-ожидания однозначно указывают на проблемы с индексацией.
Вопрос
Является ли ожидания типа IO необходимым и достаточным условием отсутствия индекса для таблицы или материализованного представления в СУБД PostgreSQL ?
Ответ нейросети GigaChat
Как и любая языковая модель, GigaChat не обладает собственным мнением и не транслирует мнение своих разработчиков. Ответ сгенерирован нейросетевой моделью на основе открытых данных, в которые могла попасть некорректная информация, способная повлиять на результат. Во избежание недоразумений, разговоры на некоторые темы временно ограничены
Ответ нейросети Aлиса
Ожидания типа IO не являются ни необходимым, ни достаточным условием для отсутствия индекса в таблице или материализованном представлении в PostgreSQL.
Это подтверждается следующими фактами:
* При наличии индекса также могут наблюдаться ожидания IO, но их количество и корреляция будут существенно ниже
* Основные признаки необходимости создания индекса при массовых операциях SELECT+UPDATE:
* Сильная корреляция ожиданий с типами IO/IPC
* Превышение количества ожиданий типа IPC над IO
* Использование Seq Scan или Parallel Seq Scan в плане выполнения запросов
* Отсутствие индекса приводит к последовательному сканированию таблицы (Seq Scan), что вызывает:
* Массовое чтение данных с диска (DataFileRead)
* Повышенные ожидания IO
* Низкую производительность запросов
Таким образом, хотя ожидания IO часто сопровождают работу с неиндексированными таблицами, их наличие/отсутствие само по себе не может служить единственным индикатором необходимости создания индекса. Требуется комплексный анализ планов запросов и корреляции различных типов ожиданий.
━━━━━━━━━━━━━━━━━━
На основе: dzen.ru postgrespro.ru tantorlabs.ru
Ответ нейросети Ask Postgres
В PostgreSQL ожидание типа IO (ввод-вывод) не является ни необходимым, ни достаточным условием для отсутствия индекса на таблице или материализованном представлении.
Пояснение:
1. Что такое ожидание IO?
Ожидание IO — это состояние, при котором процесс СУБД ожидает завершения операций чтения/записи на диске (например, чтение страницы данных с диска в буферный пул). Это метрика производительности, отражающая задержки, связанные с физическим доступом к данным, а не структурную особенность таблицы.
2. Связь с индексами
Наличие или отсутствие индекса — это логическая структура, определяемая при создании таблицы или явно через CREATE INDEX.
Ожидание IO возникает, когда PostgreSQL не может найти нужные данные в оперативной памяти (буферном пуле) и должен прочитать их с диска — независимо от наличия индекса.Без индекса: PostgreSQL может выполнять полное сканирование таблицы (Seq Scan), что приводит к большим IO-ожиданиям.
С индексом: PostgreSQL может выполнять индексный сканирование (Index Scan), но если индекс не покрывает запрос, он всё равно может обращаться к таблице (Index + Heap Scan), что также вызывает IO.
3. Необходимость и достаточность
Не является необходимым: Таблица без индекса может не вызывать IO-ожиданий, если все данные уже в буферном пуле (например, после нескольких повторных запросов).
Не является достаточным: Наличие IO-ожиданий не означает отсутствие индекса — индексированные запросы тоже могут вызывать IO, если индекс или данные не кэшированы.
4. Вывод
Ожидание IO — это результат выполнения запроса, а не причина или признак отсутствия индекса.
Отсутствие индекса может способствовать увеличению IO-ожиданий, но не является единственной причиной, и наличие IO-ожиданий не доказывает отсутствие индекса.
Итог: Ожидание типа IO — независимый параметр производительности, не связанный логически с наличием индекса как с необходимым или достаточным условием.
См. документацию: [PostgreSQL Performance Monitoring] — раздел о pg_stat_activity и pg_stat_statements.
Ответ нейросети DeepSeek
Отличный и очень точный вопрос. Короткий ответ: нет, ожидания типа IO не являются ни необходимым, ни достаточным условием отсутствия индекса.
Давайте разберем это подробно, так как понимание этого различия — ключ к грамотному анализу производительности PostgreSQL.
1. Почему это не необходимое условие?
Необходимое условие означает: "Если индекса нет, то мы обязательно увидим IO ожидания".
Это неверно. Отсутствие индекса может проявляться другими типами ожиданий, или вообще не проявляться в мониторинге ожиданий в конкретный момент времени.
Пример:
Допустим, у вас есть таблица users без индекса в столбце email. Вы выполняете запрос:
SELECT * FROM users WHERE email = 'test@example.com';
Планировщик будет вынужден выполнить Sequential Scan (Seq Scan). Что при этом происходит?
Данные уже в RAM (кеш): Если таблица небольшая и полностью находится в shared_buffers (кэш PostgreSQL) или в оперативной кэш-памяти ОС, то чтение будет происходить из памяти. В этом случае вы увидите ожидания типа CPU, а не IO (например, CPU или, более конкретно, BufferPin). Запрос будет быстрым, но он все равно загрузит CPU необходимостью просканировать всю таблицу.
Конкуренция за блокировки: Во время полного сканирования PostgreSQL должна получить доступ к каждому блоку данных. Если в этот момент с этими блоками работают другие процессы (например, на запись), ваш запрос может ждать освобождения легковесной блокировки (LWLock), а не самого ввода-вывода.
Вывод: Отсутствие индекса может приводить к высоким CPU ожиданиям или ожиданиям Lock, если данные уже кэшированы. Таким образом, IO-ожидания не являются необходимым признаком.
2. Почему это не достаточное условие?
Достаточное условие означает: "Если мы видим IO ожидания, то это гарантированно означает, что не хватает индекса".
Это тоже неверно. IO-ожидания — это очень общий симптом, который указывает на то, что СУБД много читает с диска. Причин для этого может быть множество, и отсутствие индекса — лишь одна из них.
Другие частые причины IO-ожиданий:
Недостаточный размер кэша (shared_buffers): Даже если по всем запросам есть идеальные индексы, если ваш рабочий набор данных не помещается в оперативной памяти, PostgreSQL будет вынуждена постоянно "подкачивать" нужные блоки с диска, вытесняя другие. Это вызовет Read ожидания (например, datafile read).
Неподходящий индекс или неоптимальный запрос:
Запрос использует индекс, но он недостаточно селективен, и PostgreSQL приходится читать много случайных страниц с диска (это часто видно как Bitmap Heap Scan после Bitmap Index Scan).
Запрос SELECT * FROM ... с индексом, но по условию отбирается много строк. PostgreSQL решает, что дешевле прочитать всю таблицу последовательно, чем делать много случайных обращений по индексу.Отсутствие индекса для части данных: У вас есть индекс, но он не покрывает все варианты использования. Например, вы ищете по WHERE status = 'pending', и индекс есть, но 99% строк имеют этот статус. Seq Scan будет эффективнее, и он вызовет IO.
Проблемы с вводом-выводом самой системы:
Медленный диск (HDD вместо SSD).
Высокая конкуренция за дисковый ресурс от других приложений.
Неправильная настройка ОС или файловой системы.Очень большие запросы: Запросы, которые сознательно читают гигантские объемы данных (аналитические отчеты, агрегации), всегда будут вызывать IO-ожидания, и это нормально. Создание индексов здесь может даже навредить, замедлив вставку данных.
Связь между отсутствием индекса и IO-ожиданиями
Несмотря на то что условие не является ни необходимым, ни достаточным, сильная корреляция между отсутствием индекса и IO-ожиданиями, безусловно, существует.
Когда данные не влезают в оперативную память, последовательное сканирование большой таблицы без индекса — это один из самых верных способов создать мощную нагрузку на подсистему ввода-вывода и, как следствие, высокие Read ожидания.
Как правильно анализировать?
Используйте EXPLAIN (ANALYZE, BUFFERS): Это ваш главный инструмент. Запустите этот запрос для медленного запроса. Он покажет:
Seq Scan — прямое указание на полное сканирование таблицы (верный признак возможного отсутствия нужного индекса).
Количество прочитанных блокков (shared hit vs shared read):
shared hit — данные были в кэше.
shared read — данные пришлось читать с диска (здесь и рождаются IO-ожидания).Используйте специализированные представления для анализа ожиданий:
Включите расширение pg_stat_statements и используйте такие представления, как pg_stat_database, pg_stat_all_tables, а также системные представления для анализа событий ожидания (например, pg_stat_activity с фильтром по wait_event_type).Алгоритм диагностики:
Шаг 1: Найдите запросы с самым большим временем выполнения или наибольшим количеством вызовов (pg_stat_statements).
Шаг 2: Проанализируйте план выполнения этих запросов через EXPLAIN (ANALYZE, BUFFERS).
Шаг 3: Если в плане видите Seq Scan по большой таблице — это кандидат на создание индекса.
Шаг 4: Если при этом в плане много shared read — это подтверждает, что проблема усугубляется медленным диском (IO-ожидания).
Заключение
Ожидания типа IO — это важный симптом, который часто сопровождает проблему отсутствия индексов на больших таблицах, но он не является однозначным диагностическим критерием.
Правильный подход — это не гадание по типам ожиданий, а анализ планов выполнения конкретных медленных запросов, который однозначно покажет, использует ли PostgreSQL Seq Scan из-за отсутствия подходящего индекса.
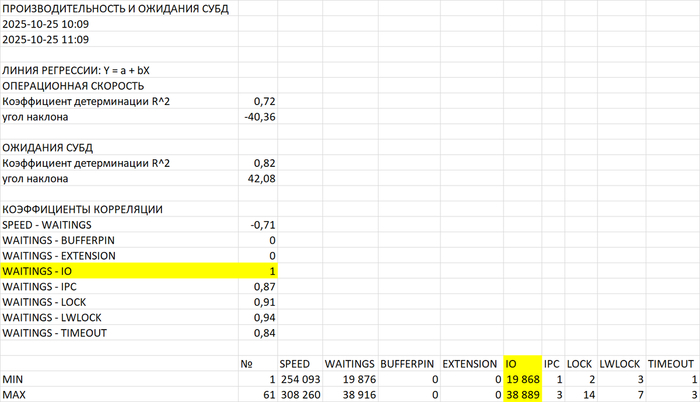
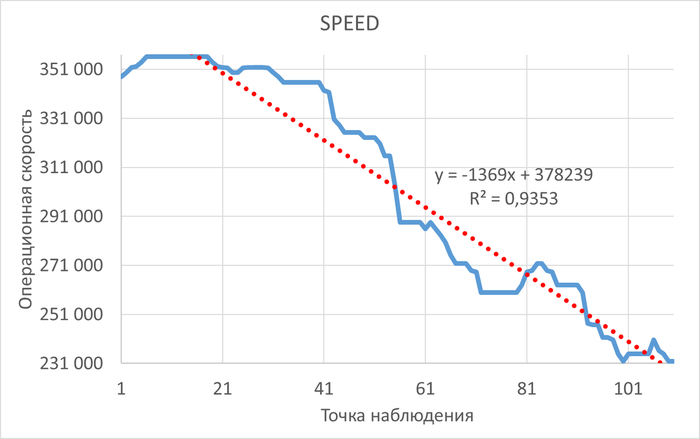
Экспериментальная проверка необходимого и достаточного условия отсутствия индекса
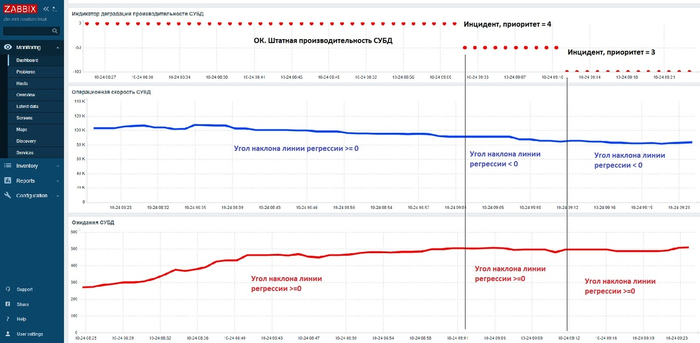
Исходные данные: анализ инцидент производительности СУБД
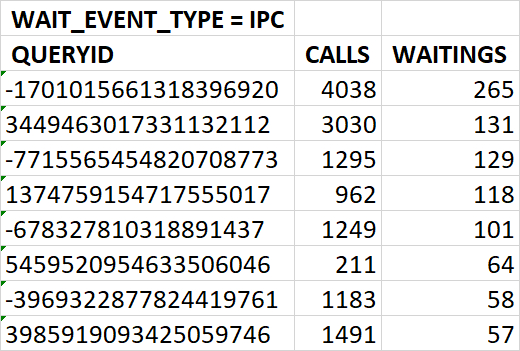
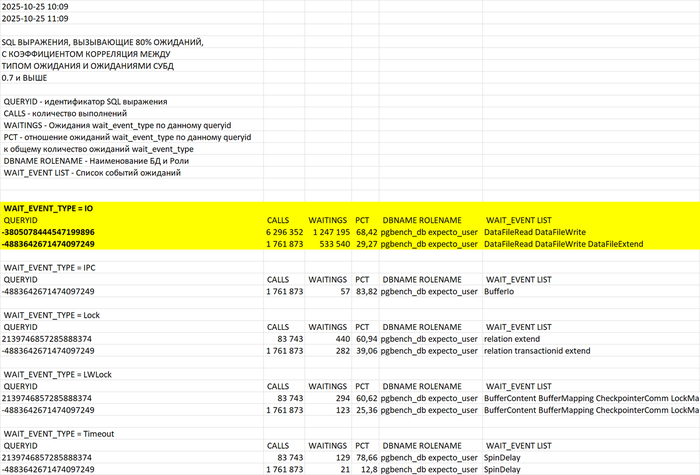
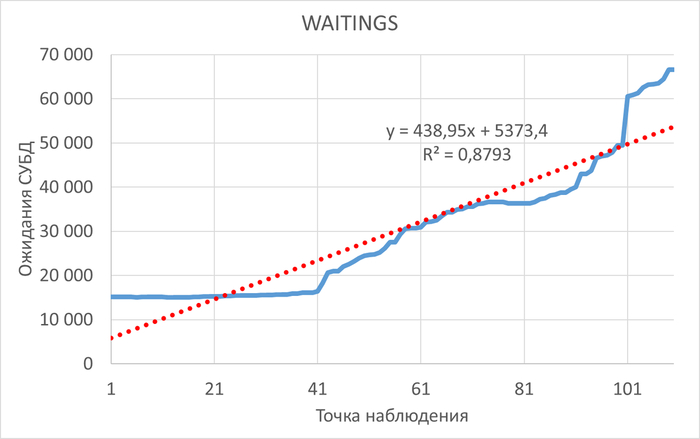
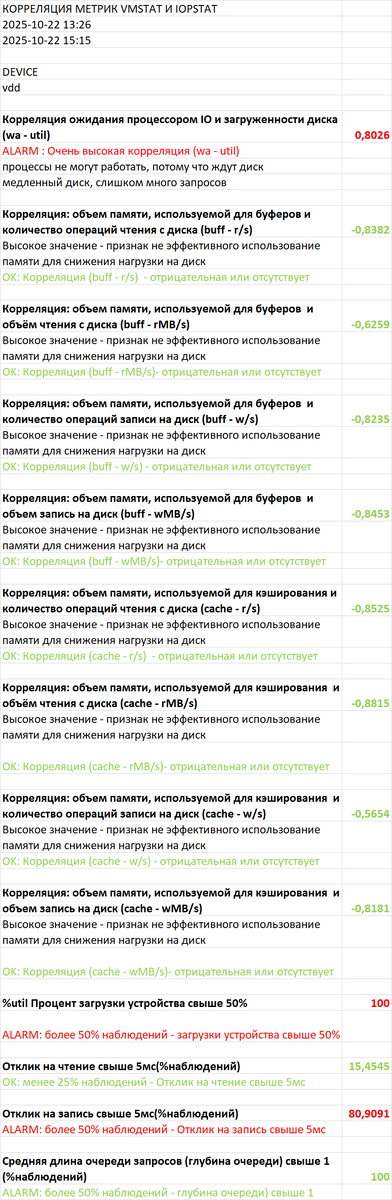
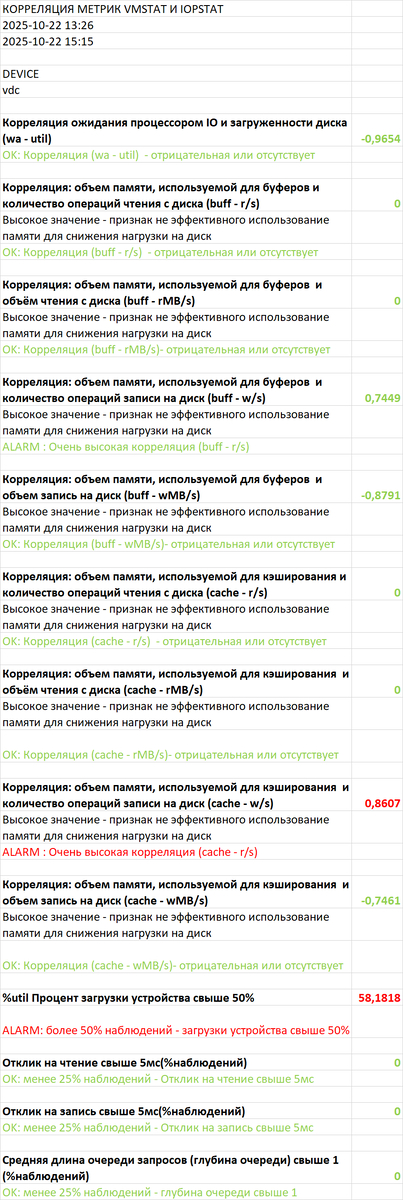
SQL запросы, вызывающие 80% ожиданий типа IO - 43 запроса
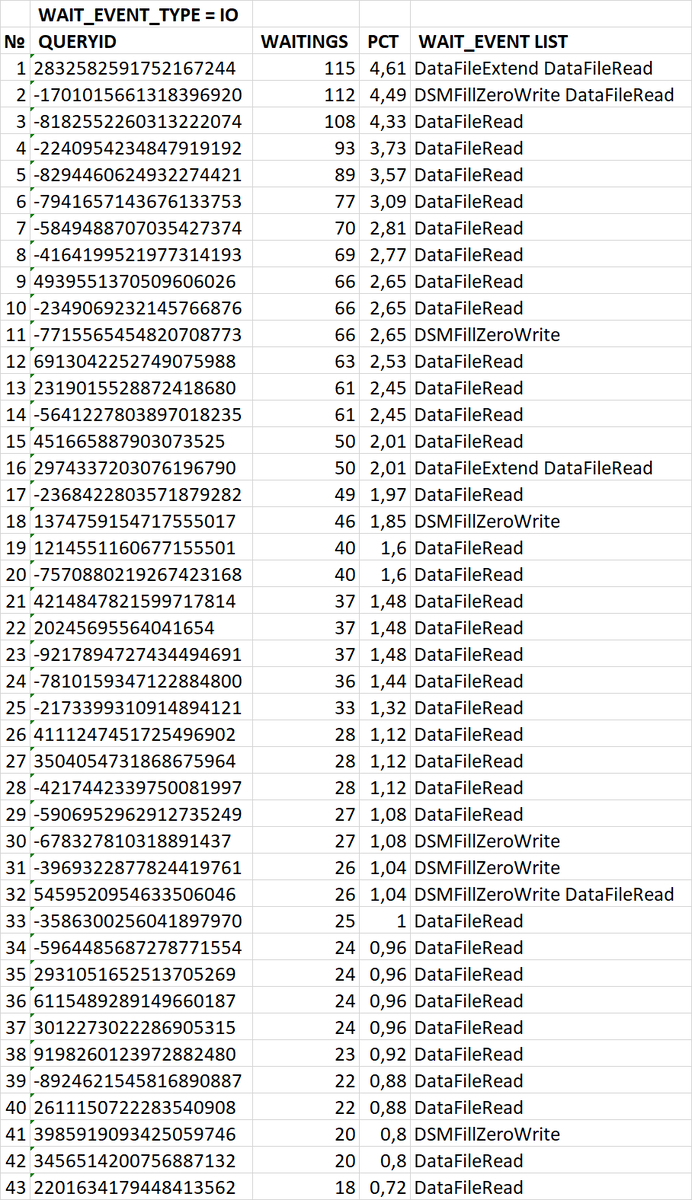
Вопрос по ожиданиям IO
Как среди списка SQL запросов - определить запросы для которых в таблицах не хватает индексов ?
Гипотеза
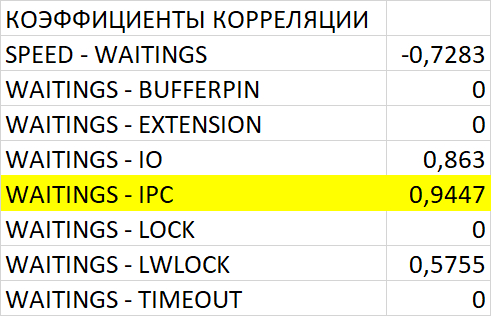
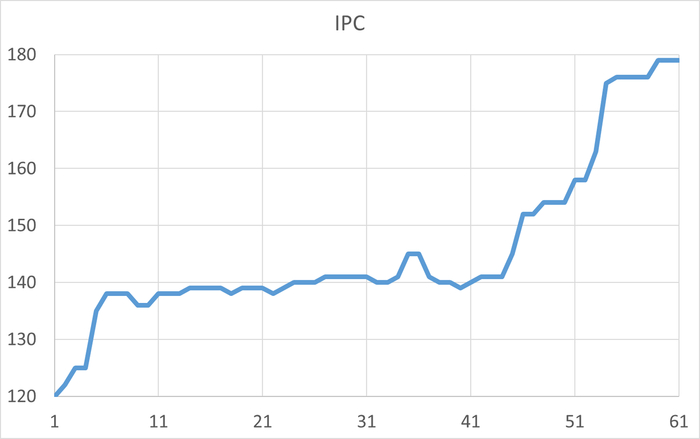
Используя результаты ранее сделанных экспериментов :
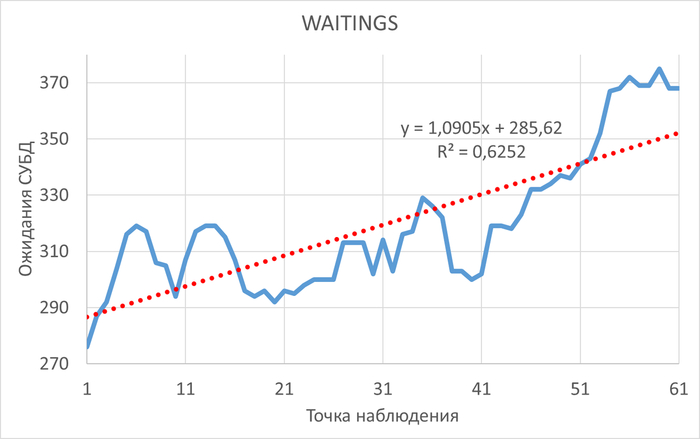
Использование метода доступа Seq Scan | Parallel Seq Scan совместно с использованием параллельных процессов( Workers Planned ,Workers Launched ) в плане выполнения запросов, обнаруженных в ходе корреляционного анализа.
...
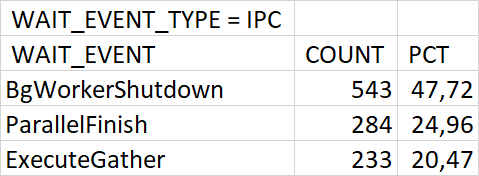
ℹ️При возникновении данных условий могут возникнуть массовые ожидания IPC/BgWorkerShutdown.
Можно сделать предположение:
Подтверждающим признаком, сужающим круг поиска SQL запросов, для оптимизации которых, необходимо создать индексы в таблицах - является ожидание BgWorkerShutdown.
Проверка гипотезы
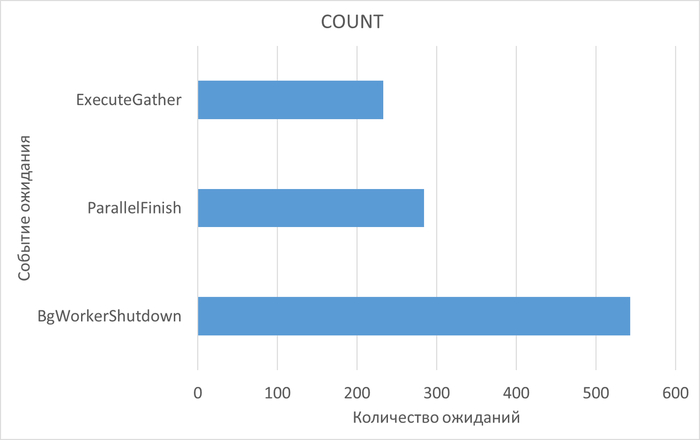
SQL запросы, вызывающие 80% ожиданий типа IPC

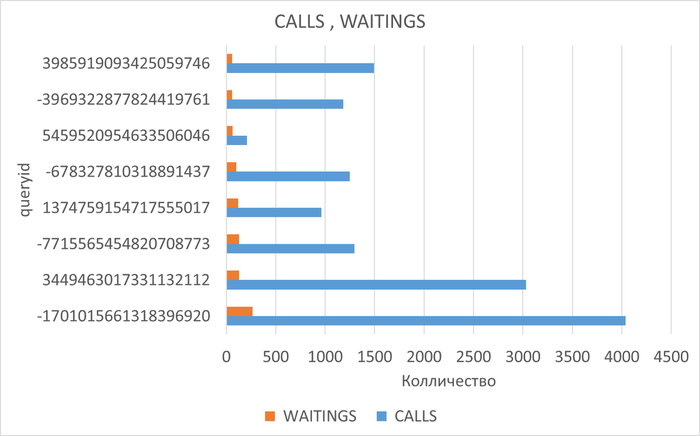
SQL запросы, вызывающие ожидания типа IO и IPС :
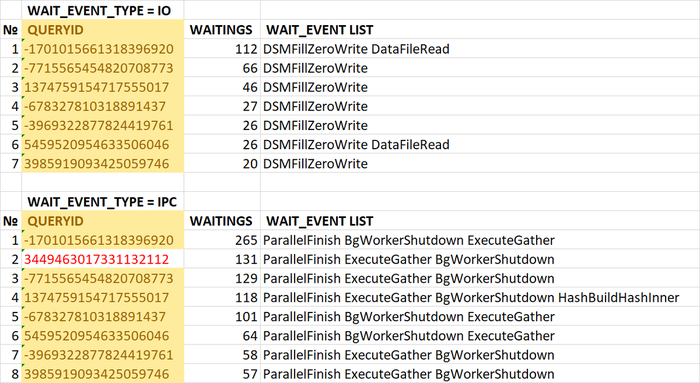
Проведенный анализ таблиц, участвующих в запросах, вызывающих ожидания BgWorkerShutdown и DSMFillZeroWrite показал отсутствие индексов по столбцам, используемым в условиях запросов.
ИТОГ
Одновременная корреляция ожидания IPC/BgWorkerShutdown и IO/DSMFillZeroWrite может служить надежным признаком необходимости добавления индексов для таблиц, участвующих в запросах, выявленных в ходе анализа инцидента производительности СУБД, значительно сужая область оптимизации по ожиданиям IO.