
Есть хотим, Наташ

Показать полностью
1
Всем привет! В рамках работы над нашим ботом в телеге с мемами Fast Food Memes решили проанализировать все русскоязычные Мартовские мемы и понять, над чем орут в Необъятной. Делимся своим анализом с вами!
Как делаем?
Парсим паблики VK, каналы Telegram и сабреддиты Reddit, извлекаем текст с картинок с помощью методов машинного зрения, приступаем к анализу.
Данные
Мы анализировали 4763 русскоязычных мема из 230 источников мемов из Reddit, VK и Telegram, которые были опубликованы в Марте этого года. Концентрировались мы на картинках, хотя были еще гифки и видео...
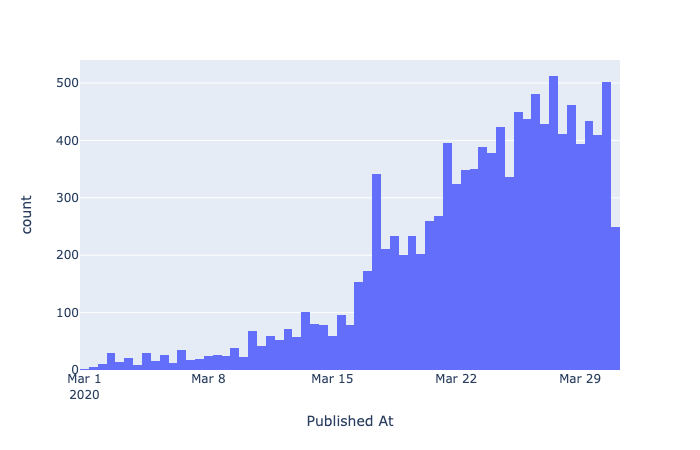
В конце марта мемов больше, чем в начале марта, потому что мы постепенно добавляли новые источники.
Готовим данные для анализа
Для анализа текста на мем-картинках, нужно его оттуда как-нибудь достать. Попробовав несколько open source решений, таких как Tesseract, поняли, что они не походят для мемов по двум причинам:
мы не знаем заранее, какой язык текста будет на меме, а на вход в открытые OCR решения нужно еще язык подавать
Текст на картинке может встретиться несколько раз в разных местах, бесплатные решения обычно детектировали только один фрагмент.
Обе проблемы отлично решаются платным Google OCR от Google Cloud Platform, при регистрации они выдают $300 кредитов, так что можно бесплатно затестить. Этот сервис не только находил текст в разных местах, но и детектировал его язык, что помогло нам также для этого анализа отфильтровать русские мемы от английских. Также он позволил задетектировать дубликаты (в случае мемов это совсем нетривиальная задача, заслуживающая отдельной статьи).
В итоге мы превратили мем картинку в текст, добавив к нему еще подпись под постом в паблике, если она была.
Подготовим данные
Следуя классике Natural Language Processing, из всех текстов мы удалили стоп-слова (местоимения, союзы, предлоги) и приведем слова к основе (иногда просто отрезав конец слова).
Так, слова дома, дому, домой превратятся в слово дом. Это нужно, потому что мы хотим считать статистику для слова "дом", а не для его различных словоформ.
Технология обрезания - Stemming и Lemmatization,
образец кода:
```python
from nltk.stem.snowball import SnowballStemmer
russianStemmer=SnowballStemmer("russian")
df['tokens'] = df['tokens'].apply(lambda tokens: [russianStemmer.stem(token) for token in tokens])
```
Анализ
Для начала посмотрим на частоту самых встречающихся слов.

(сорри за качество картинки)
Как мы видим, три самых популярных слова нас не удивляют - дом (stay home!), коронавирус и карантин.
Забавно, что собака входит в двадцатку, тогда как кот находится только на 33 месте.
Теперь посмотрим на темы - алгоритм собирает в группы слова, которые чаще всего встречаются вместе. Для этого придется вручную подбирать количество
тем, на которые мы надеемся поделить наши слова. Так же придется добавить еще много стоп-слов - например, токены "ответ", "прост", "человек" сами по себе несут смысловую нагрузку, но не помогут нам понять, что же у нас перед глазами за тема.
Тем получилось 4:
1. Коронавирус. Ключевые слова: коронавирус, карантин, дом, вирус, мыш, летуч.
2. Путин. Ключевые слова: дум, крут, московск, путин, российск, недел, март, работа.
3. Рубль. Ключевые слова: курс, рубль, российск, цен.
4. Домашнее. Много слов: мам, дет, куп, гречк, жизн, мир, сказа, кот, собак...
Вывод
Очень интересно наблюдать за трендовыми темами, которые доминируют в мемах. Отсюда можно сделать вывод, что развлекательный контент - это лакмусовая бумажка, которая может определять, какие темы действительно волнуют интернет сообщество. Из многочисленных трендов именно те, которые мы указали выше, доминировали в мем-пространстве. Почему именно они? Оставляйте ваши предположения в комментариях. И зайдите посмотреть бота - Fast Food Memes.

Анализ сакральных элементов культурного обихода, преисполненных зарядом чувственной энергии масс и поколений, неминуемо влечёт резкое социальное порицание. Однако сей факт не может служить препоной для фундаментальных научных изысканий, чья цель дознаться истины любыми средствами, не противоречащими идеалам гуманизма.
Итак, собственно, к предмету исследования:
А&Б сидели на трубе:
А упала, Б пропала, -
Кто остался на трубе?
Перво-наперво, поскольку задача сразу предстаёт расчленённой на составные части, необходимо опреде́лить условие, чтобы толкование не вызывало разночтений. Так поводом для банальных спекуляций здесь являются глаголы совершенного вида прошедшего времени упала и пропала, которые могут быть злонамеренно превратно интерпретированы в переносном смысле (ср. выражения с образованными от них прилагательными: падший (пропащий) человек). Из-за чего возникает обоснованная потребность в соглашении, строго предписывающем воспринимать изложенные в высказываниях понятия контекстуально, а не казуально: упала - свалилась наземь, потеряв равновесие; пропала - исчезла из виду, сменив локацию; кто - вопросительное местоимение, адекватное по отношению к перечисленным... Вместе с тем краеугольным фактором выступает уточнение, что изначально и впоследствии на трубе отсутствовали посторонние сущности, за исключением прямо обозначенных.
Теперь надлежит разобраться с субъектами, то есть по сути основным источником дилеммы, содержащей, как вскоре выяснится, неразрешимые противоречия. Действительно, если в идентификации А и Б нужды нисколько не наблюдается, то что собой представляет & - загадка: союз, имя собственное, логическую операцию?.. Наиболее очевидным способом устранения парадокса кажется явное указание свойства & посредством записи: А и Б; А, И, Б; А⋀Б, - но казус заключается в том, что речь идёт о фольклорном артефакте иррациональной природы, не поддающемся структуризации и конкретизации семантического поля.
Отсюда следует, что рассматриваемый мем погружает носителя в область дихотомического хаоса информационной неопределённости, что эквивалентно делению на Ø. Любые аргументы или доказательства в пользу того или иного варианта встретят равносильные контрпримеры или опровержения. Эти симптомы, всесторонне подтверждающие тщетность получения однозначного вывода не прибегая к подмене тезиса, безапелляционно констатируют, что феномен А&Б до́лжно признать эталонным образцом латентной антиномии¹, завуалированно таящим в своём ядре проблему тождественно верных взаимоисключающих суждений.
В итоге после элиминации А и Б, на трубе остался только лишь вездесущий призрак энтропии² гениального Шеннона.
_____________________
¹Латентная антиномия - исходно скрытая, обнаруживаемая сугубо в процессе детального изучения вопроса антиномия.
²Призрак Шеннона - антипод демону Максвелла. Олицетворение хаоса, стихийно привносящее неразбериху и препятствующее упорядочиванию системы.
(Терминология моя.)
P. S.
Оригинал размещён на моём Telegram-канале: @slithyrave



