Обучение модели OpenAI определять, является ли страница онлайн-магазином.
подготовка данных,
токенизация текста,
отправка данные для обучения
тест модели.
Зависимости
pip install openai
Шаг 1: Регистрация и настройка OpenAI API
Для начала работы с OpenAI API необходимо зарегистрироваться на платформе OpenAI и получить ключ API. Этот ключ будет использоваться для аутентификации при вызове методов API.
Шаг 2: Подготовка данных
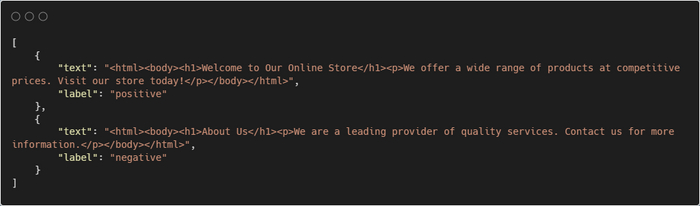
Для обучения модели нужно подготовить набор данных, который будет содержать примеры веб-страниц, как магазинов, так и не магазинов. Каждая запись должна включать текст страницы и соответствующую метку (positive для магазинов и negative для не магазинов).
Пример JSON-файла:
Шаг 3: Токенизация текста
Перед отправкой данных в модель OpenAI, текст необходимо токенизировать. Токенизация — это процесс разбиения текста на отдельные слова или токены. В Python можно использовать библиотеки, такие как NLTK, spaCy или tokenizers из библиотеки transformers.
Пример токенизации с использованием NLTK:
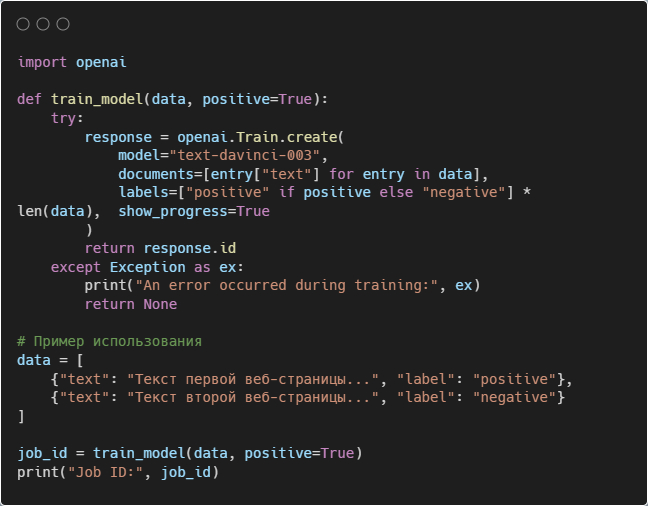
Шаг 4: Отправка данных для обучения
После токенизации текста можно отправить данные для обучения модели OpenAI. Вот пример кода для отправки данных:
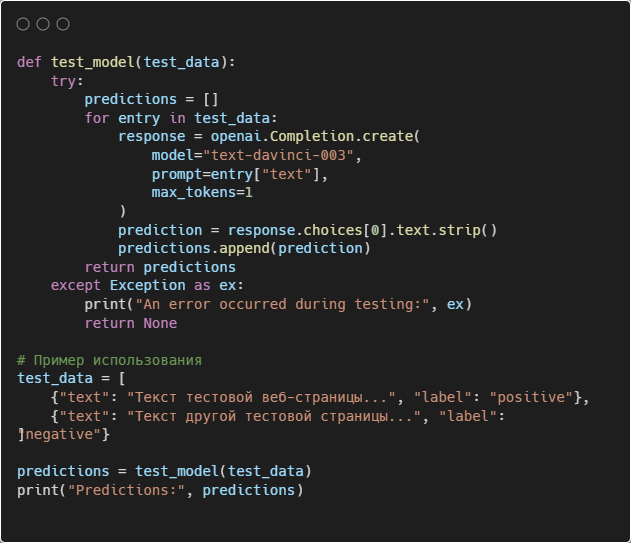
Шаг 5: Тестирование модели
После обучения модели необходимо протестировать её на тестовом наборе данных. Вот пример кода для тестирования:
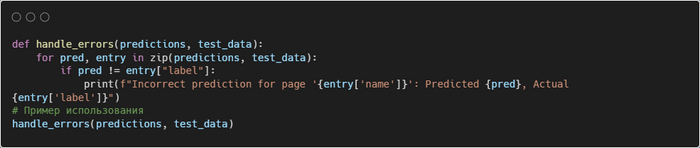
Шаг 6: Обработка ошибок и улучшение модели
Если модель даёт неверные предсказания, можно улучшить её, добавив больше данных или изменив параметры обучения. Также можно использовать обратную связь для анализа ошибок.
Пример обработки ошибок:
Я активно развиваю обучающий репозиторий с примерами реализации классических игр прошлых лет на python. Я не просто портирую игры, я адаптирую для взаимодействия с моделями машинного обучения. Объяснения код я пишу в серию «101 игра на python»
В этой статье я покажу, как быстро настроить и запустить ИИ-агента, который сможет искать информацию в Google и анализировать веб-страницы.
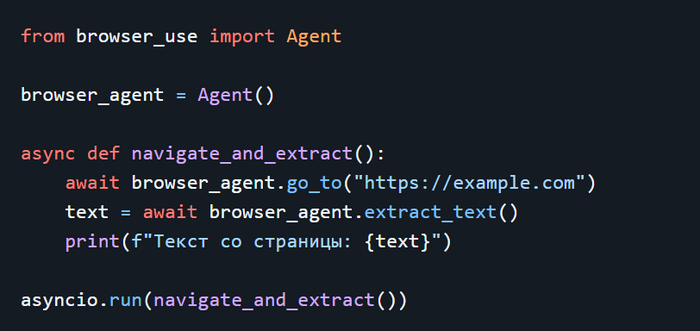
1. Что такое LangChain и Browser-Use?
LangChain — это фреймворк для работы с языковыми моделями (LLM), который позволяет создавать интеллектуальные агенты с инструментами для поиска информации, выполнения вычислений и взаимодействия с внешними сервисами.
Browser-Use — это Python-библиотека, позволяющая языковым моделям управлять веб-браузером: посещать сайты, кликать по ссылкам, заполнять формы и анализировать страницы.
Комбинируя эти две технологии, можно создать мощного интеллектуального агента для автоматизированного взаимодействия с интернетом.
2. Установка необходимых библиотек
Перед началом работы установите зависимости с помощью pip:
Для работы с OpenAI и SerpAPI необходимо получить API-ключи. Добавьте их в файл .env:
SERPAPI_API_KEY: Для чего нужен и как получить?
SERPAPI — это сервис, который предоставляет API для парсинга результатов поисковых систем (Google, Bing, Yahoo и других). Где получить ключ? Перейдите на сайт serpapi.com. Нажмите Sign Up и создайте аккаунт (доступна бесплатная пробная версия). После регистрации войдите в личный кабинет. На странице Dashboard ваш ключ будет указан в разделе API Key. Пример: abcd1234...5678xyz. Бесплатный план дает 100 запросов/месяц (достаточно для тестирования). Для коммерческих проектов выберите подходящий тариф (от $50/месяц).
Файн-тюнинг стоит делать не "как можно чаще", а когда это действительно необходимо и оправдано с точки зрения наличия новых данных, ожидаемого улучшения качества и затрат ресурсов (времени и денег). Вместо частого файн-тюнинга на малых объемах данных иногда эффективнее использовать другие подходы, например, Retrieval-Augmented Generation (RAG), где модель получает актуальную информацию в момент запроса из внешней базы знаний. Технически, нет строгих ограничений со стороны платформ (как Google Vertex AI, например) на то, как часто вы можете запускать процесс файн-тюнинга (fine-tuning), кроме общих квот на использование ресурсов и вашего бюджета. Вы можете запустить новый процесс файн-тюнинга хоть через час после предыдущего, если есть такая необходимость и ресурсы.
Однако, с практической точки зрения, частота файн-тюнинга определяется следующими факторами:
Наличие новых данных: Самая главная причина для повторного файн-тюнинга – появление значительного объема новых, качественных данных, которые могут улучшить производительность модели для вашей задачи. Файн-тюнинг на небольшом количестве новых данных может не дать заметного эффекта или даже ухудшить модель (переобучение на новых данных).
Стоимость: Каждый процесс файн-тюнинга требует вычислительных ресурсов (GPU/TPU) и, соответственно, стоит денег. Частый файн-тюнинг может быть весьма затратным.
Время: Процесс файн-тюнинга занимает время – от часов до дней, в зависимости от размера модели, объема данных и конфигурации. Плюс время на подготовку данных и оценку результата.
Необходимость: Действительно ли нужно обновлять модель?Изменилась ли задача, для которой вы используете модель? Ухудшилось ли качество ответов существующей дообученной модели со временем (например, из-за изменений во внешнем мире, которые отражены в новых данных)? Даст ли добавление новых данных ощутимый прирост качества, оправдывающий затраты?
Оценка (Evaluation): После каждого файн-тюнинга необходимо проводить тщательную оценку модели на тестовом наборе данных, чтобы убедиться, что новая версия действительно лучше предыдущей и не произошло "катастрофического забывания" (когда модель ухудшает свои способности в областях, на которых ее не дообучали в этот раз).
Когда обычно делают повторный файн-тюнинг:
При накоплении существенного блока новых релевантных данных (например, данные за последний квартал, месяц и т.д.).
При значительных изменениях в предметной области или требованиях к задаче.
Когда мониторинг производительности показывает заметное снижение качества текущей модели.
Периодически (например, раз в квартал или полгода), если данные поступают непрерывно и есть бюджет/ресурсы на поддержание модели в актуальном состоянии.
Структура файла для файн-тюнинга (fine-tuning) зависит от платформы, которую вы используете (например, Google Vertex AI, OpenAI API, Hugging Face, etc.) и типа задачи, для которой вы дообучаете модель.
Однако, наиболее распространенным форматом является JSON Lines (JSONL). В этом формате каждая строка файла представляет собой отдельный, валидный JSON-объект, содержащий один пример для обучения.
Общая идея структуры для генеративных моделей (как Gemini):
Каждый JSON-объект (каждая строка в файле .jsonl) обычно содержит пары "вход" -> "ожидаемый выход".
Примеры форматов данных для файн-тюнинга:
1. Задачи инструктивного типа / чата / вопрос-ответ:
Вариант 1 (Простой):
Вариант 2 (Более структурированный, для чатов):
2. Задачи генерации текста (продолжение текста):
Вариант 1 (Объединенный):
Вариант 2 (Префикс/Продолжение):
3. Задачи классификации:
Важные моменты:
Обязательно смотрите документацию той платформы, где вы проводите файн-тюнинг! Названия полей (input_text, output_text, prompt, completion, text, label и т.д.) могут отличаться. Например, Google Vertex AI часто использует input_text и output_text для supervised tuning.
Формат Файла: Убедитесь, что это именно JSON Lines (.jsonl), а не обычный JSON-массив. Каждая строка - отдельный JSON.
Кодировка: Обычно требуется UTF-8.
Самое важное – это качество и релевантность ваших данных. Они должны быть чистыми, точными и соответствовать той задаче, которую вы хотите, чтобы модель решала.
Размер Данных: Количество примеров влияет на качество файн-тюнинга. Обычно требуются сотни или тысячи примеров, в зависимости от сложности задачи и модели.
Пример файла my_finetuning_data.jsonl для Google Vertex AI (инструктивный тюнинг):
ИИ навязывается нам практически во всех аспектах жизни: от телефонов и приложений до поисковых систем и даже автокасс . Тот факт, что теперь у нас есть веб-браузеры со встроенными помощниками на основе ИИ и чат-ботами, показывает, что способы, которыми некоторые люди используют интернет для поиска и потребления информации сегодня, сильно отличаются от того, что было даже несколько лет назад.
Однако инструменты искусственного интеллекта всё чаще требуют доступа к вашим персональным данным под предлогом необходимости их работы. Такой доступ не является нормой и не должен считаться нормой.
Не так давно вы могли бы задаться вопросом, почему, казалось бы, безобидное бесплатное приложение типа «фонарик» или «калькулятор» в App Store пытается запросить доступ к вашим контактам, фотографиям и даже данным о вашем местоположении в реальном времени. Возможно, этим приложениям эти данные не нужны для работы, но они запросят их, если решат, что смогут заработать на ваших данных пару долларов .
В наши дни искусственный интеллект ничем не отличается.
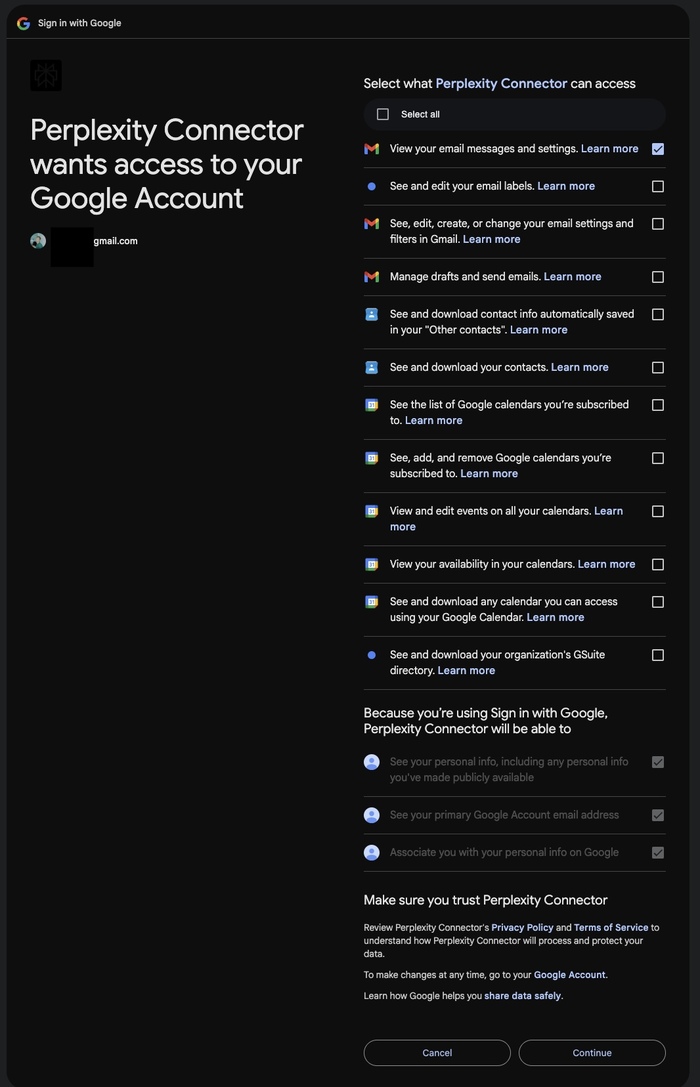
В ходе недавнего практического использования браузера TechCrunch обнаружил, что когда Perplexity запрашивает доступ к календарю Google пользователя, браузер запрашивает широкий спектр разрешений для учетной записи Google пользователя, включая возможность управлять черновиками и отправлять электронные письма, загружать контакты, просматривать и редактировать события во всех ваших календарях и даже возможность делать копию всего справочника сотрудников вашей компании.
Comet запросил доступ к аккаунту Google пользователя. Источник изображений: TechCrunch
Perplexity утверждает, что значительная часть этих данных хранится локально на вашем устройстве, но вы все равно предоставляете компании права доступа и использования вашей личной информации, в том числе для улучшения ее моделей ИИ для всех остальных.
Perplexity — не единственная компания, которая запрашивает доступ к вашим данным. Существует тенденция к появлению приложений на основе ИИ, которые обещают сэкономить ваше время, например, расшифровывая ваши звонки или рабочие встречи, но требуют, чтобы ИИ-помощник предоставлял доступ к вашим личным перепискам в режиме реального времени, календарям, контактам и другим данным. Meta также тестирует пределы того, к чему могут запросить доступ её приложения на основе ИИ, включая доступ к фотографиям, хранящимся в фотоплёнке пользователя , которые ещё не были загружены.
Президент Signal Мередит Уиттакер недавно сравнила использование агентов и помощников ИИ с тем, чтобы «поместить ваш мозг в банку». Уиттакер объяснила, как некоторые продукты ИИ могут обещать выполнение самых разных рутинных задач, например, бронирование столика в ресторане или билета на концерт. Но для этого ИИ потребует вашего разрешения на открытие браузера для загрузки веб-сайта (что может предоставить ИИ доступ к вашим сохранённым паролям, закладкам и истории просмотров), кредитной карты для бронирования, вашего календаря для отметки даты, а также может попросить открыть ваши контакты, чтобы поделиться бронированием с другом.
Использование помощников на основе искусственного интеллекта, работающих с вашими данными, сопряжено с серьёзными рисками для безопасности и конфиденциальности. Предоставляя доступ, вы мгновенно и безвозвратно передаёте права на полный набор самых личных данных на данный момент времени, включая входящие, сообщения, записи в календаре за прошлые годы и многое другое. Всё это ради выполнения задачи, которая якобы экономит ваше время — или, по словам Уиттакера, избавляет вас от необходимости активно думать об этом.
Вы также предоставляете ИИ-агенту разрешение действовать автономно от вашего имени, требуя от вас огромного доверия к технологии, которая и без того склонна к ошибкам или откровенному фальсифицированию . Использование ИИ также требует от вас доверия компаниям, разрабатывающим эти продукты на основе ИИ и ориентированным на получение прибыли, которые используют ваши данные для повышения эффективности своих ИИ-моделей . Когда что - то идёт не так (а такое случается часто), сотрудники ИИ-компаний обычно просматривают ваши личные подсказки, чтобы понять, почему что-то не работает.
С точки зрения безопасности и конфиденциальности, простой анализ затрат и выгод подключения ИИ к вашим самым личным данным просто не оправдывает отказа от доступа к самой конфиденциальной информации. Любое приложение с ИИ, запрашивающее такие разрешения, должно насторожить вас, как и приложение-фонарик, которое хочет знать ваше местоположение в любой момент времени.
Учитывая огромные объемы данных, которые вы передаете компаниям, работающим в сфере ИИ, спросите себя, действительно ли то, что вы получаете, того стоит.
Четыре кота, на которых держится машинное обучение
Первая часть.
Чем машинное обучение отличается от традиционного программирования с его «работает, пока не трогаешь»? Где заканчиваются четкие алгоритмы — и где начинается магия «черного ящика», как в случае с ChatGPT?
Это первая статья в научно-популярной серии, где мы разберем основы ИИ — без пустых слов, без клише, без академического тумана и, в идеале, без уравнений (как однажды написал Стивен Хокинг: каждая формула в научно-популярной книге сокращает ее продажи вдвое).
Сегодня мы поговорим о самом фундаменте: какие типы обучения используют модели ИИ, зачем они вообще нужны и как они определяют, на что способна модель.
Да, будут котики. И немного сарказма. Но исключительно в благородных целях — для создания сильных и запоминающихся ассоциаций.
Эта статья для всех, кто начинает знакомиться с ИИ: для технических и нетехнических читателей, архитекторов решений, основателей стартапов, опытных разработчиков и всех, кто хочет наконец-то составить ясное мысленное представление о том, что такое машинное обучение и с чего все начинается.
В этой части мы рассмотрим основы: Что такое МО, чем оно кардинально отличается от традиционного программирования, и четыре ключевые парадигмы обучения, которые лежат в основе всего современного ландшафта ИИ.
Классическое программирование против машинного обучения
Если вы уже уверены в своем понимании того, чем машинное обучение отличается от традиционного программирования, смело пропускайте этот раздел. Но если вы хотите прояснить это различие — это может помочь.
Начнем с простой аналогии.
Калькулятор выполняет одну арифметическую операцию за раз — и только по прямой команде. Компьютер с традиционным кодом идет на шаг дальше: он выполняет заранее определенные программы, принимает решения с помощью управляющих структур, хранит промежуточные значения и обрабатывает несколько входов. Это отлично работает, когда входные данные предсказуемы, а поведение можно описать жесткой, детерминированной логикой.
Но этот подход дает сбой в запутанных, неоднозначных или неопределенных ситуациях.
Например, попробуйте написать полный набор правил if/else, чтобы:
отличить Луну от круглого потолочного светильника,
разобрать небрежный почерк,
или обнаружить сарказм в твите.
Это не масштабируется. Вы быстро сталкиваетесь с комбинаторным взрывом частных случаев
Именно здесь классическое программирование упирается в свой потолок, и начинается машинное обучение.
Можно думать о МО как о следующем уровне абстракции: если калькуляторы работают с арифметикой, а код — со структурированной логикой, то МО справляется с неструктурированной неопределенностью. Даже нечеткая логика — с ее градиентами и порогами — часто не справляется со сложностью реального мира. МО вообще не полагается на заранее написанные правила; вместо этого оно учится поведению на основе данных.
Вместо того чтобы говорить машине, что делать, вы показываете ей, что хотите получить, и она статистически выясняет, как это сделать. Обучение происходит не через жестко закодированные инструкции, а через паттерны, вероятности и обобщение.
Распознавание рукописного текста и изображений — это лишь два примера задач, где невозможно предсказать все сценарии.
В зависимости от своего обучения, модель МО может увидеть букву, которую никогда раньше не встречала, и все равно распознать ее — основываясь на тысячах похожих образцов рукописного текста. Она может определить, что пользователь нарисовал динозавра, даже если именно такого силуэта не было в обучающих данных, — потому что она понимает формы, пропорции и текстуру не как правила, а как распределения. Вместо того чтобы жестко следовать заранее написанному сценарию, — она угадывает.
Парадигмы машинного обучения
То, что может делать модель ИИ, сильно зависит от того, как ее обучали.
В первую очередь, модели ИИ классифицируются по их парадигмам обучения. Парадигма определяет сильные и слабые стороны модели.
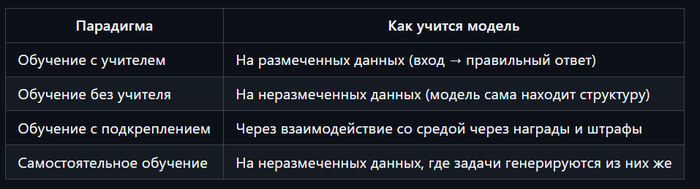
Большинство методов машинного обучения относятся к одной из четырех основных парадигм:
Обучение с учителем
Обучение без учителя
Обучение с подкреплением
Самостоятельное обучение (иногда также называемое «самообучением»)
Обучение с учителем (Supervised Learning)
Как обучить модель отличать кошек от собак на фотографиях? Вы показываете ей десятки тысяч изображений — каждое с правильной меткой: «Это кошка» или «Это собака». Модель начинает искать закономерности: «Ага, у кошек есть треугольные уши, а у собак — длинные морды». Она не знает, что такое кошка или собака, но она видит, что некоторые изображения похожи друг на друга, а другие — нет. И с каждым новым примером она становится все лучше в распознавании этих паттернов. После тысяч итераций модель начинает замечать кое-что сама: у кошек треугольные уши, подозрительный взгляд и склонность основательно усаживаться на клавиатуру. Это и есть обучение с учителем — тренировка на размеченных примерах, где «правильный» ответ известен заранее.
По сути, вы говорите: «Вот входные данные — а вот ожидаемый результат». Задача модели — обнаружить закономерности и обобщить их на новые, невиданные данные.
После тысячи фотографий кошек модель уловила суть: треугольные уши — это важно. Теперь она использует это, чтобы отличать кошек от собак
Типичные примеры использования:
Классификация (например, спам vs. не спам)
Регрессия (например, прогнозирование цены)
Оценка вероятности (например, вероятность оттока клиентов)
Обучение с учителем в реальном мире:
Анализ тональности:Вход: текст отзыва → Выход: позитивный / негативный
Фильтрация спама:Вход: текст письма → Выход: спам / не спам
Медицинская диагностика:Вход: результаты анализов → Выход: здоров / болен
Модерация контента:Вход: текст или изображение → Выход: допустимо / нарушает правила
Категоризация товаров:Вход: описание товара → Выход: категория каталога
OCR (Оптическое распознавание):Вход: фото документа → Выход: извлеченный текст
Обучение без учителя (Unsupervised Learning)
Иногда кажется, что динозавры — это просто очень самоуверенные лягушки.
В этой парадигме модель обучается на неразмеченных данных, то есть ей никогда не говорят, какой ответ «правильный». Вместо этого она пытается самостоятельно обнаружить скрытую структуру, закономерности или взаимосвязи. Думайте об этом как о попытке организовать хаос по категориям, когда никто никогда не говорил вам, какими эти категории должны быть.
Представьте, что вы показываете модели тысячи изображений — кошек, собак, лягушек и динозавров (предположим, для ясности, что мы каким-то образом получили четкие фотографии вымерших рептилий). Но мы не говорим модели, кто есть кто. На самом деле, модель даже не знает, сколько существует категорий: три? пять? пятьдесят? Она просто ищет визуальные закономерности. В конце концов, она начинает группировать пушистых существ в один кластер, а тех, у кого гладкая кожа, глаза по бокам и зловеще холодный взгляд, — в другой.
После тысяч примеров модель в конечном итоге решает: «Сложим все пушистое в коробку №1, а все с блестящей кожей и глазами по бокам — в коробку №2». Сами метки не имеют значения — важно то, что содержимое каждой коробки становится все более однородным.
Модели без учителя не пытаются предсказывать метки. Вместо этого они:
Группируют похожие объекты (кластеризация)
Обнаруживают выбросы или аномалии
Снижают размерность (упрощают сложные данные)
Эта парадигма особенно полезна, когда:
Разметка данных слишком дорога или непрактична
Вы еще не знаете, что ищете
Вы хотите обнаружить сегменты или поведенческие паттерны без предопределенных категорий
Обучение с подкреплением (Reinforcement Learning)
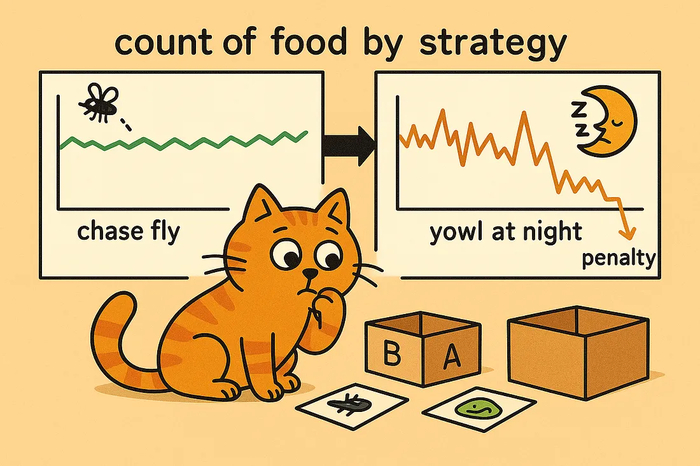
В этой парадигме модель — называемая агентом — учится, взаимодействуя со средой методом проб и ошибок. Агент пробует разные действия и наблюдает за реакцией среды. Действия, которые приближают к желаемому результату, приносят награды; неэффективные или вредные действия приводят к штрафам.
Попробуем дрессировать кошку. (Да, мы знаем, что в реальной жизни это почти невозможно, но мы уже взялись за кошачью тему, так что вот мы здесь.) Кошка — это агент. Квартира — это среда. Кошка пробует разные действия: Поймала муху → получила лакомство (награда) Скинула телевизор → осталась без ужина (штраф) Через многократный опыт кошка начинает вести себя полезным образом — не потому, что она понимает, чего вы хотите, а потому, что она выучила политику: набор действий, которые чаще всего приводят к еде. Ей не нужны правила — она учится на последствиях.
Как показывает график — криком ничего не добьешься.)
Обучение с подкреплением используется, когда:
Поведение должно улучшаться со временем
Нет предопределенных «правильных» ответов
Последствия отложены, а не мгновенны
Самостоятельное обучение (Self-Supervised Learning)
В этом подходе модель обучается на неразмеченных данных, но задача для обучения извлекается из самих данных — без участия человека в разметке. Модель учится предсказывать одну часть входных данных на основе другой.
Пример Исходное предложение: «Кот запрыгнул на клавиатуру и залил незаконченный код в продакшн».
Мы можем превратить это в задачу для обучения. Например:
Замаскировать слово:вход: «Кот запрыгнул на *** и развернул незаконченный код...», цель: предсказать слово клавиатура.
Для Тензорного Кота писать вверх ногами — это всего лишь вопрос выбора правильной системы координат.
Эти пары «вход + цель» генерируются автоматически, без ручной разметки. Та же идея применяется к разным типам данных, таким как изображения (предсказание отсутствующих фрагментов) или аудио.
Реальные применения самостоятельного обучения:
Языковые модели (GPT, LLaMA, Claude)
Компьютерное зрение (CLIP, DINO)
Аудио и речь (Wav2Vec 2.0)
Мультимодальные модели (Gemini, CLIP)
Предобучение (фундаментальные модели)
Основная идея Модель обучается на автоматически сгенерированных задачах, где «правильный ответ» извлекается непосредственно из самих данных. Это дает нам масштабируемость, способность к обобщению и основу для большинства современных генеративных и языковых систем.
Сводка по парадигмам обучения
Что еще существует?
Помимо этих четырех, существуют и другие подходы (частично-контролируемое, активное, онлайн-обучение и т. д.). Они редко рассматриваются как самостоятельные парадигмы, потому что обычно являются гибридами или вариациями основных стратегий, которые мы уже рассмотрели. Для понимания сути машинного обучения — достаточно освоить эти четыре.
В следующей части мы погрузимся в то, что такое нейронная сеть на самом деле: нейроны, веса, связи. Как она «учится»? Зачем ей вообще нужны слои? И какое отношение куча чисел имеет к пониманию языка, изображений или... реальности?
Мы снимем слой за слоем — и попытаемся ответить на единственный вопрос, который имеет значение:
Так есть ли здесь хоть какая-то магия... или это просто замаскированная математика?
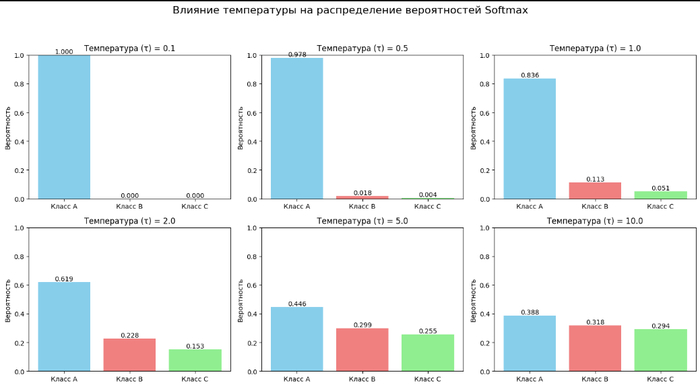
Шпаргалка демонстрирует работу формулы softmax с разной температурой (`τ`).
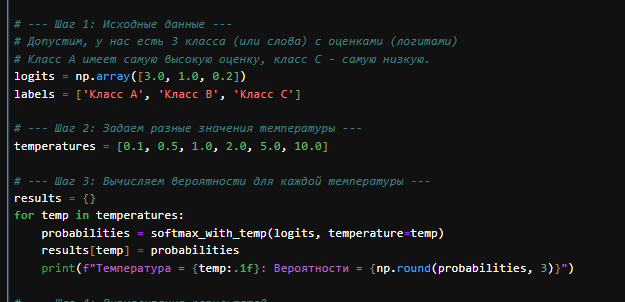
Возьмем простой набор "оценок" (логитов) для трех классов и посмотрим, как меняются вероятности при изменении температуры.
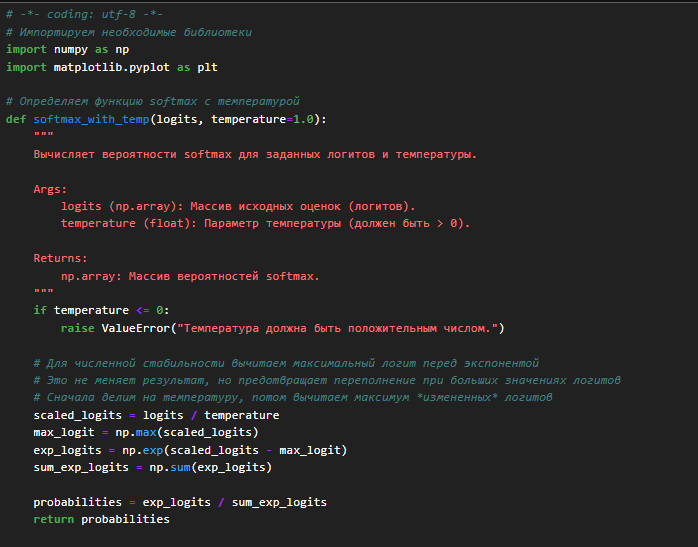
Функция softmax
Вычисления
Визуализация результатов
Пример наглядно показывает, как параметр температуры τ позволяет контролировать "уверенность" или "случайность" выбора в функции softmax.
argmax (сокращение от "arguments of the maximum", аргументы максимума) — это математическая операция, которая находит аргумент (то есть входное значение или индекс), при котором функция или набор значений достигает своего максимума.
Проще говоря:
max находит само максимальное значение.
argmax находит позицию (индекс) или входное значение, где это максимальное значение находится.
Примеры:
Набор чисел: Пусть у нас есть массив чисел: A = [10, 50, 20, 40] max(A) вернет 50 (само максимальное значение). argmax(A) вернет 1 (индекс элемента 50, если считать с 0: 10 - индекс 0, 50 - индекс 1, 20 - индекс 2, 40 - индекс 3).
Функция: Пусть есть функция f(x) = -(x - 2)^2 + 10. Эта парабола имеет вершину в точке x=2, где значение функции равно 10. Максимальное значение функции max(f(x)) равно 10. argmax(f(x)) равен 2 (значение x, при котором функция f(x) максимальна).
В контексте классификации с помощью нейронных сетей и функции softmax:
Модель на выходе обычно выдает "логиты" (оценки) для каждого класса.
Функция softmax преобразует эти логиты в вероятности (числа от 0 до 1, сумма которых равна 1).
Чтобы принять окончательное решение о том, к какому классу относится входной объект, мы обычно выбираем класс с наибольшей вероятностью.
Операция argmax, примененная к массиву вероятностей softmax, вернет индекс класса, у которого самая высокая вероятность.
Пример с Softmax:
Логиты: [3.0, 1.0, 0.2]
Вероятности после softmax (при T=1): [0.839, 0.114, 0.047] (примерно)
Применяем argmax к вероятностям [0.839, 0.114, 0.047].
Результат argmax: 0 (потому что максимальное значение 0.839 находится на позиции с индексом 0). Это означает, что модель выбирает первый класс.
При очень низкой температуре (τ → 0) функция softmax приближается к argmax по исходным логитам, так как почти вся вероятность концентрируется на элементе с максимальным логитом.
Семействo функций и операций, связанных с поиском максимальных/минимальных значений
Max (Максимум): Находит и возвращает самое большое значение из набора чисел или значений функции. Пример: max([10, 50, 20, 40]) вернет 50. Назначение: Просто найти пиковое значение.
Min (Минимум): Находит и возвращает самое маленькое значение из набора чисел или значений функции. Пример: min([10, 50, 20, 40]) вернет 10. Назначение: Найти наименьшее значение, часто используется в функциях потерь (мы хотим минимизировать ошибку).
Argmax (Аргумент максимума): Находит и возвращает индекс (позицию) или входное значение (аргумент), при котором достигается максимальное значение. Не само значение, а его "адрес". Пример: argmax([10, 50, 20, 40]) вернет 1 (индекс элемента 50, если считать с 0). Назначение: Узнать, какой элемент является максимальным. В классификации — узнать индекс класса с наибольшей вероятностью/оценкой.
Argmin (Аргумент минимума): Находит и возвращает индекс (позицию) или входное значение (аргумент), при котором достигается минимальное значение. Пример: argmin([10, 50, 20, 40]) вернет 0 (индекс элемента 10). Назначение: Узнать, какой элемент является минимальным. Например, найти параметр, минимизирующий функцию потерь.
Softmax: Преобразует вектор действительных чисел (логитов) в вектор вероятностей. Каждое выходное значение находится в диапазоне (0, 1), и их сумма равна 1. Большие входные значения получают большие вероятности. Это "мягкая", дифференцируемая версия argmax. Пример: softmax([3.0, 1.0, 0.2]) вернет примерно [0.839, 0.114, 0.047]. Назначение: Получение вероятностного распределения по классам в задачах классификации, используется в механизмах внимания, при генерации текста для выбора следующего слова. Ключевое свойство — дифференцируемость, что позволяет использовать ее в градиентных методах обучения.
LogSoftmax: Применяет логарифм к результату softmax. То есть log(softmax(x)). Пример: log_softmax([3.0, 1.0, 0.2]) вернет примерно [-0.175, -2.175, -3.05]. Назначение: Часто используется в связке с функциями потерь, такими как NLLLoss (Negative Log Likelihood Loss). Вычисление log_softmax напрямую часто более численно стабильно, чем вычисление softmax, а затем взятие логарифма, особенно когда вероятности близки к 0. log(softmax(x)) = x - log(sum(exp(x))) — это позволяет избежать вычисления exp(x), которое может привести к очень большим или очень маленьким числам.
Hardmax: Неформальный термин для операции, которая строго преобразует вектор в "one-hot" вектор, где элемент, соответствующий максимальному значению исходного вектора, становится 1, а все остальные — 0. По сути, это представление результата argmax в виде вектора. Пример: "Hardmax" от [3.0, 1.0, 0.2] будет [1, 0, 0]. Назначение: Теоретическое сравнение с softmax. softmax — это гладкая аппроксимация "hardmax". "Hardmax" не дифференцируема в точках, где есть несколько одинаковых максимумов, и ее градиент равен нулю почти везде, что делает ее непригодной для обучения с помощью градиентного спуска.
max/min и argmax/argmin дают точные, но "жесткие" ответы, в то время как
softmax предоставляет "мягкую", вероятностную и дифференцируемую альтернативу argmax.