Автоматизировать первым самый дорогой процесс — почти всегда ошибка
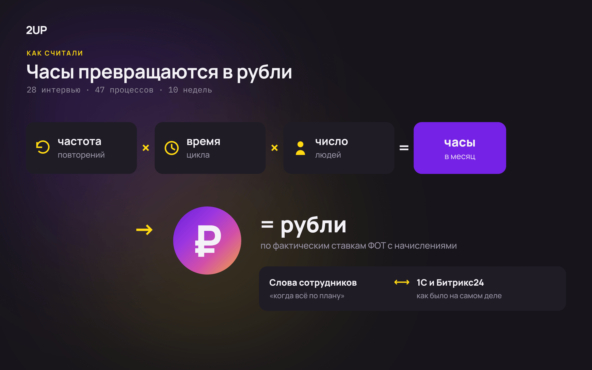
В прошлой статье я рассказал, как мы посчитали стоимость ручного труда в холдинге — перевели рутину в часы, а часы в деньги, и получили список процессов с ценой каждого. На этом диагностика заканчивается и начинается вопрос, который оказывается сложнее самого подсчёта: с чего начать.
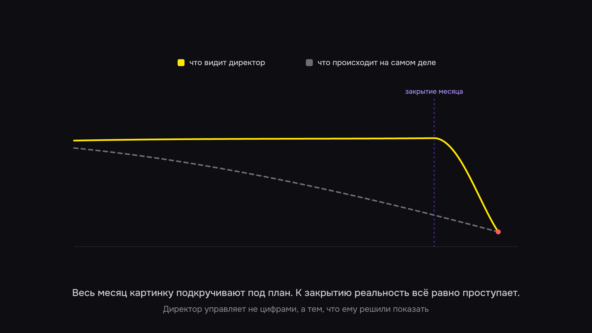
Когда мы приносим собственнику этот список, происходит предсказуемое. Палец упирается в строчку с самой большой суммой потерь: «вот с этого и начнём». Логика железная — где теряем больше всего, там и чиним в первую очередь. И почти всегда она ведёт проект в стену. Эта статья — о том, почему «самый дорогой» и «первый на автоматизацию» это разные процессы, и про инструмент из двух осей, которым мы разводим их на каждом проекте.
Почему дорогой процесс — плохой старт
Дорогой процесс почти всегда дорогой не случайно. Он большой, разветвлённый, завязан на много людей и систем — поэтому и потери на нём крупные. Но ровно эти же свойства делают его тяжёлым для автоматизации.
Получается ловушка. Берёшь в работу самое дорогое — значит берёшь самое сложное. Вкладываешь больше всего денег, ждёшь результат дольше всего, рискуешь сильнее всего. И если первый же проект буксует полгода, у руководства формируется вывод: автоматизация — это долго, дорого и непонятно. После такого старта второй попытки может и не быть.

Я видел, как компании убивали целое направление одним неудачным выбором первого процесса. Не потому что технология не работала — а потому что начали не с того.
Обиднее всего, что снаружи это выглядит как поражение технологии. Руководитель докладывает собственнику: «попробовали ИИ, не взлетело». Хотя не взлетел не ИИ, а решение начать с процесса, который при любом подрядчике и любой технологии дал бы результат не раньше, чем через год. Ярлык «не работает» при этом цепляется ко всей идее автоматизации, а не к ошибке планирования. И снять его потом гораздо труднее, чем повесить.
Поэтому первый процесс выбирают не по размеру потерь. На кону репутация всего проекта внутри компании — первый результат либо открывает дорогу остальным, либо закрывает её. Его задача — быстро доказать, что подход работает.
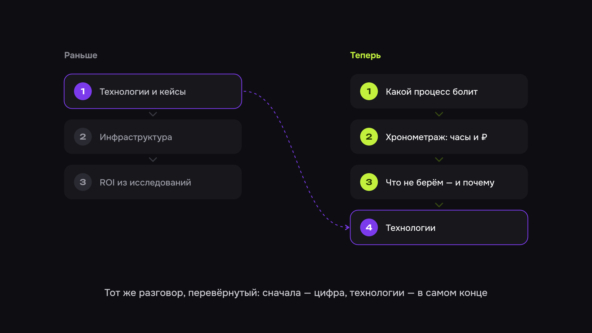
Стоимость — это только половина уравнения
Чтобы не попадать в эту ловушку, мы давно не оцениваем процессы по одной цифре потерь. Каждый проходит через две независимые шкалы, от 1 до 10.
Первая — влияние на бизнес. Сколько денег, времени и риска снимет автоматизация.
Вторая — сложность реализации. Насколько тяжело это технически сделать: однозначные ли правила, есть ли данные, нужно ли дообучать модель, сколько систем придётся связать.
Две оси не связаны между собой. Высокое влияние не означает высокую сложность, и наоборот. Бывает дорого и легко. Бывает дёшево и адски трудно. Оси независимы — и потому одной цифры потерь недостаточно: она показывает только влияние и молчит про сложность.
Баллы мы не берём с потолка. Влияние выводится из той самой диагностики, о которой шла речь в прошлый раз — часы, деньги, уровень риска, уже посчитанные по каждому процессу. Сложность оцениваем по конкретному чек-листу: есть ли готовые данные, однозначны ли правила, нужно ли дообучать модель, со сколькими системами предстоит интегрироваться. Две независимые оценки, каждая обоснована — поэтому карту потом и не получается оспорить «на ощущениях».
Хороший первый кандидат живёт в одном конкретном углу: высокое влияние при низкой сложности. Максимум отдачи за минимум вложений и риска. Дальше всё сводится к тому, чтобы честно разложить процессы по этим двум осям и посмотреть, кто куда попал.

Шесть процессов, на которых видно, как это работает
Покажу на реальных оценках из нашего проекта. Я взял шесть процессов, которые легли в разные зоны карты — и каждый иллюстрирует своё правило отбора.

Распознавание паспортов и сканов. Влияние 10, сложность 3. Специалисты вручную считывают данные из паспортов и ИНН и вносят в 1С. Объём большой, ошибки дорогие, риск с персональными данными прямой. А технически — это зрелая задача: распознавание документов, однозначные поля, минимум интерпретации. Высокое влияние, низкая сложность. Эталонный первый кандидат: пользы много, подводных камней почти нет.
Контроль исполнения поручений. Влияние 6, сложность 2. Задачи и так ведутся в Битрикс24, проблема в прозрачности — нужен реестр, аналитика по просрочкам, часть поручений теряется в офлайне. Влияние среднее: прямых денег процесс почти не приносит, его ценность — в управляемости. Зато сложность — одна из самых низких во всём списке: данные уже в системе, нужен только умный слой аналитики поверх. Пользы меньше, чем у паспортов, но и усилий почти ноль. Это то, что я называю «быстрая победа» — процесс, который не изменит экономику, но за пару недель покажет руководству, что автоматизация даёт осязаемый результат.
Согласование договоров. Влияние 8, сложность 2. Бухгалтерия проверяет каждый договор, поток 3–8 в день, а каналы разные: часть приходит в 1С:Документооборот, часть по почте, часть в Битрикс24. Из-за этой разнородности договоры теряются и проверяются вручную на налоговые риски. Влияние высокое — это деньги и юридические риски.
И при этом сложность низкая: задача сводится к единому каналу данных и ИИ-помощнику с чек-листом рисков. Дорогой и лёгкий одновременно — редкое и потому ценное сочетание. Такие берут в работу не раздумывая.
Финансовое планирование, БДДС. Влияние 10, сложность 3. Бюджет движения денежных средств ведётся в Excel вручную, план платежей пересобирается дважды в неделю, фактически платежи постоянно выбиваются из графика. Влияние максимальное — речь о живых деньгах и кассовых разрывах. Сложность умеренная: данные о платежах структурированы, нужен планировщик сценариев. Ещё один сильный кандидат верхнего угла — и показатель того, что «дорого и сложно» вовсе не обязаны идти в паре.
Контроль закупок на злоупотребления. Влияние 8, сложность 6. Здесь и прячется главная ловушка списка. Риск реальный и дорогой: закупки «срочно» в обход тендера, завышение цен, подмена номенклатуры. По влиянию — твёрдая восьмёрка.
Но сложность шесть, и она обманчива. Прежде чем алгоритм начнёт ловить отклонения, кто-то должен определить, что вообще считать нормальной ценой — рыночный коридор по каждой позиции. А это не формализуемое правило, а экспертное суждение, которое плывёт по регионам и сезонам. Сам поиск отклонений — простая задача, установка нормы — нет. Это классический процесс-ловушка: большая сумма потерь манит начать с него, а скрытая сложность гарантирует долгий и мучительный старт.
Речевая аналитика звонков. Влияние 5, сложность 8. Контроль скриптов в отеле и продажах: вручную все звонки не прослушать, качество проседает. Польза есть, но средняя — пятёрка. А сложность почти на потолке: распознавание речи в реальном времени, отраслевой сленг, интеграция с телефонией, онлайн-подсказки оператору. Средняя отдача за максимальные усилия. Процесс не плохой — просто категорически не для старта.
Шесть процессов — шесть разных решений. И ни одно из них не выводится из одной только суммы потерь.
Паспорта и БДДС дорогие и лёгкие — вперёд. Договоры дорогие и лёгкие — тоже вперёд. Закупки дорогие, но коварные — подождут. Речевая аналитика средняя и тяжёлая — в хвост. Поручения дешёвые, но почти бесплатные в реализации — идеальны для разогрева.

Спор, который всё расставил по местам
Этот метод не раз снимал споры на старте проектов — сработал он и здесь.
Руководитель направления настаивал на речевой аналитике. Боль реальная: вручную все звонки не прослушать, качество продаж проседает, хочется контроля. По его ощущению — это надо делать первым, потому что болит прямо сейчас.
Я не стал спорить аргументами. Открыл карту и показал две точки. Речевая аналитика: влияние 5, сложность 8 — средняя польза, максимальная трудоёмкость. Рядом — согласование договоров: влияние 8, сложность 2. Один процесс даёт меньше пользы и требует больше всего работы. Другой даёт больше пользы почти даром.
Спор закончился за минуту. Не потому что я лучше убеждаю, а потому что цифры лежали на столе и говорили сами. Речевая аналитика не исчезла из плана — она просто встала не первой, а в свою очередь. Когда критерий прозрачен, разговор перестаёт быть состязанием мнений и становится чтением одной таблицы.
И это, пожалуй, главная ценность двух осей — даже не точность приоритезации, а то, что они снимают конфликт. У каждого руководителя свой процесс болит сильнее всего, и каждый искренне считает его первоочередным. Карта переводит спор из плоскости «чья боль важнее» в плоскость «что объективно выгоднее автоматизировать раньше». С таблицей не спорят так, как спорят с человеком.
Почему очередь важнее скорости
Когда люди слышат «фазы внедрения», думают про логистику — что физически нельзя делать всё сразу. Это верно, но второстепенно. За фазами стоит причина важнее — психологическая. Первые процессы в проекте автоматизации работают прежде всего на доверие, а уже потом на экономику. Руководству нужно увидеть, что эта штука вообще приносит результат — быстро, осязаемо, в цифрах, которые можно показать на совещании. Несколько быстрых побед в первые месяцы создают кредит доверия, под который потом можно браться за сложное и долгое.

Если же начать с тяжёлого процесса, который даёт эффект через год, доверие закончится раньше эффекта. Формально ты делаешь самое ценное. Фактически — рубишь сук, на котором держится весь проект.
Поэтому очередь строится не по убыванию потерь. Сначала идёт то, что докажет состоятельность подхода — высокое влияние при низкой сложности, как паспорта или договоры. Потом — то, что даёт основную экономию. В самый конец — стратегическое, для чего ещё нужно накопить данные.
И это не отказ от дорогого процесса. Это отложенный заход на него — но уже с позиции заработанного доверия, когда у руководства нет вопроса «а оно вообще работает». Тот же контроль закупок гораздо проще запускать пятым, когда четыре предыдущих процесса уже принесли измеримый результат и спорить о состоятельности подхода никто не станет.
Что из этого стоит забрать
Найти, что автоматизировать, — несложно. Список кандидатов в любом холдинге набирается за пару недель.
Сложно — определить очередь. И главная ошибка здесь не техническая, а арифметическая: люди ранжируют процессы по одной цифре потерь, хотя решение требует двух осей. Влияние без учёта сложности приводит ровно туда, куда тянет интуиция, — к самому дорогому и самому неподъёмному процессу. А оттуда — к буксующему старту и ярлыку «ИИ у нас не работает».
Правильный первый шаг — не там, где больше всего теряешь. А там, где большая отдача встречается с низкой сложностью и быстрым результатом. Две оси вместо одной цифры, честные баллы вместо ощущений, очередь вместо «давайте всё сразу». Посчитайте обе оси, прежде чем тыкать пальцем в самую большую сумму. Палец почти всегда показывает не туда.
А про тот самый процесс, от которого мы осознанно отказались на старте — контроль закупок с его обманчивой сложностью, — расскажу отдельно в следующий раз. Это история про то, как правильно сказать клиенту «нет» и почему отказ иногда ценнее согласия.