Медицина, IT и AI — как это должно работать? Часть 2
В первой части мы говорили о Big Medical Knowledge Graph
MedCora можно рассматривать как попытку построить Big Medical Knowledge Graph — структурированное медицинское ядро, где разные сущности нормализуются и связываются между собой.
Внутри такой системы медицинская сущность перестаёт быть просто названием. Заболевание получает связи. Симптом получает частоту и значимость. Лабораторный показатель получает интерпретацию. Препарат получает механизм действия, молекулярные свойства и клинические связи. Анатомия связывается с болезнями, методами диагностики, тканями и органными системами.
Это попытка сделать медицинскую карту знаний, где каждая сущность имеет место в общей структуре.
Основные блоки графа
1. Заболевания
Блок заболеваний строится вокруг классификаций, нозологий и связей между ними. Сюда входят ICD-10, ICD-11, ICD-10-CM / PCS, отдельные нозологические сущности, онкологические классификации и другие источники.
Главная задача здесь — не просто перечислить болезни, а показать их иерархию, связи, группы, пересечения, клинические формы и возможные переходы между уровнями описания.
Заболевание должно быть не строкой в справочнике, а узлом графа.
2. Симптомы и синдромы
Симптом в медицинском графе — должен быть связан с заболеваниями, частотой встречаемости, диагностической значимостью, контекстом, тяжестью, локализацией, механизмом возникновения и возможными синдромальными группами.
Один и тот же симптом может быть банальным, а может быть красным флагом. Всё зависит от контекста.
Именно поэтому симптом должен жить в связке:
симптом → синдром → заболевание → вероятность → опасность → уточняющие признаки → исключающие признаки.
3. Лекарственные средства
Лекарственный блок — один из самых сложных.
Препарат должен быть связан не только с названием и группой, но и с механизмом действия, показаниями, противопоказаниями, взаимодействиями, заболеваниями, симптомами, побочными реакциями, молекулярными свойствами и фармакологическими параметрами.
На уровне молекулы важны масса, липофильность, полярность, водородные связи, заряды, фракция sp3, стереоцентры, растворимость, проницаемость, ADME, BCS, биоэквивалентность, стабильность, деградация, CMC и производственные параметры.
То есть лекарственный блок должен быть полезен не только врачу, но и фарме, исследователям, CMC-командам, AI-моделям и системам клинической поддержки.
4. Лабораторные и инструментальные методы
Лабораторный показатель без контекста почти ничего не значит.
Один и тот же маркер может иметь разное значение в зависимости от пола, возраста, беременности, времени забора, метода измерения, сопутствующих заболеваний, терапии, остроты состояния и динамики.
Поэтому лабораторные и инструментальные методы должны быть нормализованы не только по названию, но и по единицам, референсам, методам, клинической интерпретации, связанным заболеваниям, органам, тканям и клиническим сценариям.
Это критический слой для любого медицинского AI.
5. Химиотерапевтические схемы
Онкология особенно хорошо показывает, почему простой текстовый справочник недостаточен.
Химиотерапевтическая схема — это не только список препаратов. Это дозы, циклы, интервалы, линии терапии, ограничения, токсичность, поддерживающая терапия, контроль осложнений, связь с диагнозом, морфологией, стадией, мутациями и клиническим состоянием пациента.
Для AI-системы это должен быть отдельный структурированный слой.
6. Хирургия и реанимация
Терапевтические профили относительно проще описывать через диагнозы, симптомы, анализы и препараты. Хирургия и реанимация сложнее.
Здесь важны процедуры, состояния, события, оборудование, вмешательства, временные окна, осложнения, интенсивность наблюдения, маршрутизация и командная логика.
Это пока одна из самых трудных областей для графовой нормализации, но без неё медицинский Knowledge Graph будет неполным.
7. Анатомия
Анатомия кажется простым блоком только на первый взгляд. На самом деле проблема не в том, чтобы перечислить органы. Проблема в том, чтобы правильно выстроить уровни:
система → область → орган → часть органа → ткань → клеточный тип → соседние структуры → сосуды → нервы → заболевания → симптомы → методы визуализации
Именно анатомия может стать пространственным слоем для связи клинических данных, визуализации, КТ/МРТ, хирургии, онкологии и морфологии.
8. Генетика, гистология и морфология
Современная медицина всё сильнее уходит в молекулярный и тканевой уровень.
Гены, мутации, белки, ткани, опухолевые ассоциации, морфологические варианты, иммуногистохимия, молекулярные маркеры — всё это должно быть связано с заболеваниями, препаратами, прогнозом, диагностикой и выбором терапии.
Без этого граф остаётся классическим справочником. С этим — он становится основой для современной персонализированной медицины.
Клинический движок как слой правил
Сам по себе граф ещё не решает всю задачу. Связи нужны, но нужны и правила. Клинический движок — это слой, который должен превращать данные в проверяемую логику:
если есть такие признаки → проверить такие состояния → исключить такие риски → запросить такие данные → применить такое правило → указать источник → показать уровень уверенности.
В MedCora такой подход реализуется через набор YAML-правил, онтологических файлов, НСИ-источников и нормализованных медицинских сущностей.
Особенно важна связка с организационными моделями здравоохранения: ОМС, ВМП, ДМС, Bismarck, Beveridge, модели покрытия и финансирования помощи. Потому что медицина существует не только как биология, но и как система оказания помощи.
Пациенту мало поставить диагноз. Его нужно провести через маршрут: куда направить, какой профиль, какой уровень помощи, какие документы, какие основания, какие ограничения, какая система оплаты.
Почему это важно для AI
Big Medical Knowledge Graph может стать тем слоем, которого сейчас не хватает медицинским AI-системам.
LLM хорошо работает с языком. Но медицине нужно больше:
нормализация → связь → проверка → источник → правило → неопределённость → объяснение → действие.
Граф может дать AI-системе не просто текст, а опорную структуру. Тогда модель не должна “вспоминать” медицину из вероятностного пространства. Она может обращаться к ядру, где уже есть сущности, связи, ограничения, источники и правила.
Это особенно важно для:
дифференциальной диагностики;
клинического поиска;
поддержки врача;
нормализации данных из МИС;
разметки медицинских датасетов;
построения AI-контуров;
фармакологических исследований;
онкологических решений;
маршрутизации пациента;
анализа качества медицинской помощи;
связи клинических и экономических моделей.
Текущие ограничения
Важно не делать вид, что такая система уже полностью решена.
Проблем много.
Клиническое качество может сильно отличаться по сущностям. Где-то данные выглядят хорошо, где-то требуют ручной проверки. Переводы остаются отдельной болью. Источники могут содержать ошибки. Связи неполные. Некоторые области медицины структурированы лучше, некоторые хуже. Отображение пока может выглядеть скорее как первичная онтологическая структура, чем как законченный клинический продукт.
Отдельная проблема — использование LLM внутри такого ядра. С одной стороны, LLM может ускорить перевод, нормализацию и проверку. С другой — она легко внесёт хаос, если использовать её без строгого контроля, источников и правил валидации.
Поэтому медицинский граф нельзя строить только генерацией. Его нужно строить как инженерную систему: с источниками, проверками, версиями, правилами, ручной ревизией и клинической ответственностью.
Главная идея
Если всё сжать — получается простая штука:
Медицинскому AI сейчас не нужна ещё одна красивая модель. Ему не хватает нормального основания под ногами: чтоб можно было проверить, откуда взялось, как связано, какая версия, где заканчивается уверенность.
Нужен не один «умный» инструмент, а оркестр. Каждый играет своё — но по одной партитуре.
LLM — интерфейс, язык, объяснение. Не хранилище истины.
RAG — доступ к текстам и документам. Не замена структуры.
Knowledge Graph — сущности, связи, контекст. То, что нельзя потерять, когда текст сжимают в ответ.
Rule-based engine — проверяемая логика, клинические правила, отказ от вывода, когда данных мало.
Клинические рекомендации и НСИ — источники, на которые можно сослаться, а не «модель так решила».
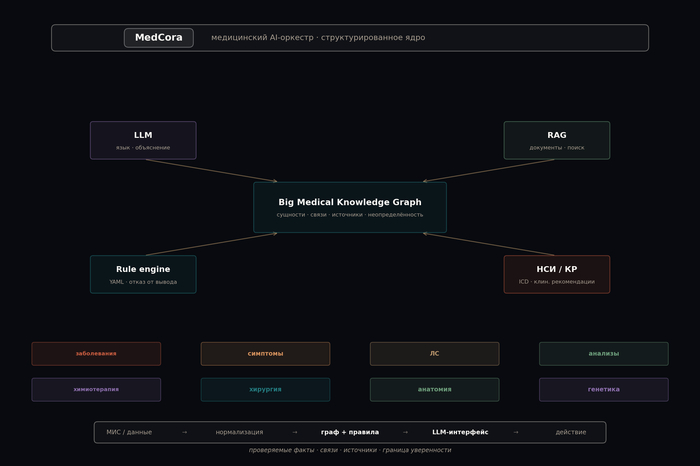
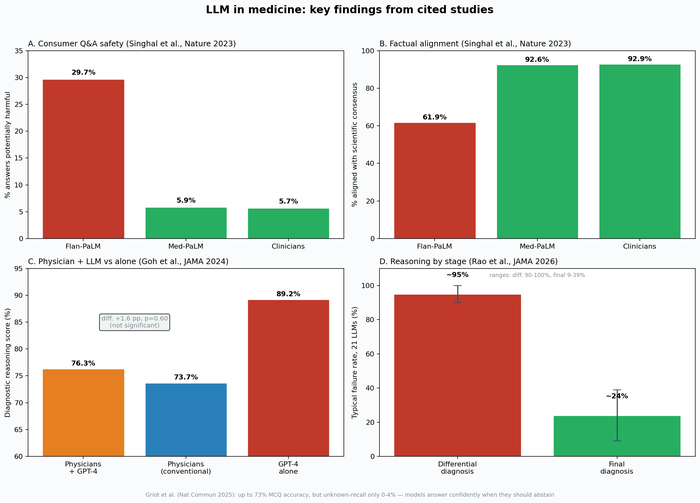
Рис. 2. Архитектура MedCora: структурированное ядро (граф + правила + НСИ), вокруг — LLM и RAG как инструменты, не хранилище истины.
И это не набор разрозненных фич, которые можно докинуть поверх chatbot. Это одна архитектура: справочники связаны, правила прописаны, источники указаны, система знает, где граница уверенности и когда лучше замолчать, чем выдать красивую, но опасную догадку.
Именно поэтому Big Medical Knowledge Graph — на наш взгляд, не «ещё один справочник». Это попытка сделать то самое основание, на котором можно собрать оркестр инструментов для нормальных медицинских AI-систем. Что это за оркестр и как он должен работать — разберём в следующей статье.