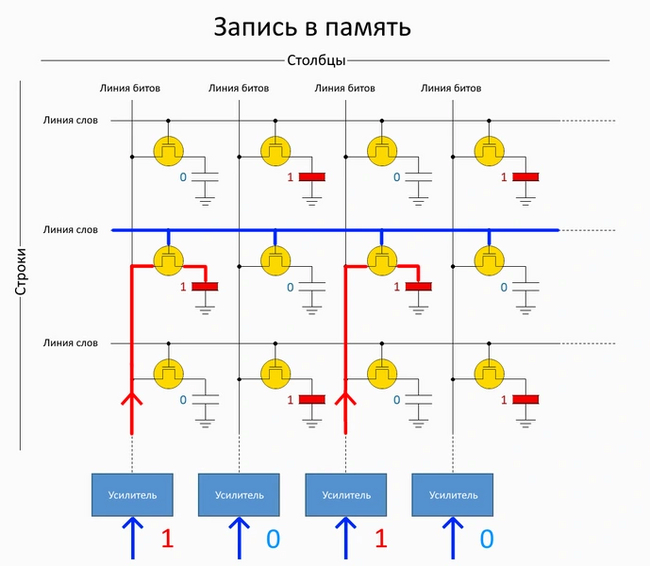
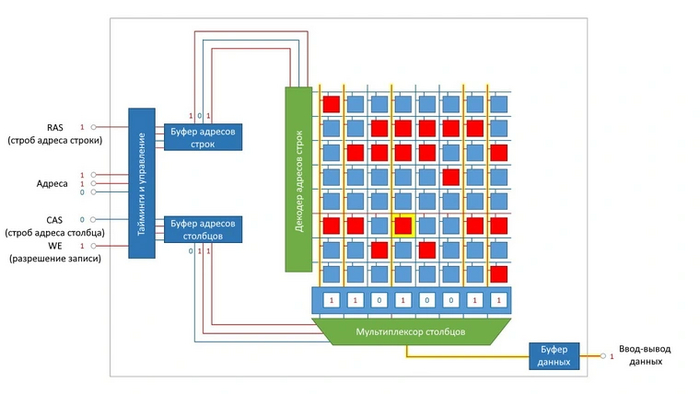
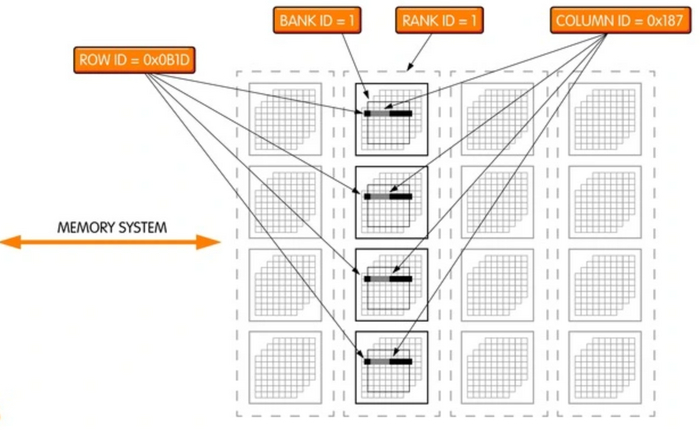
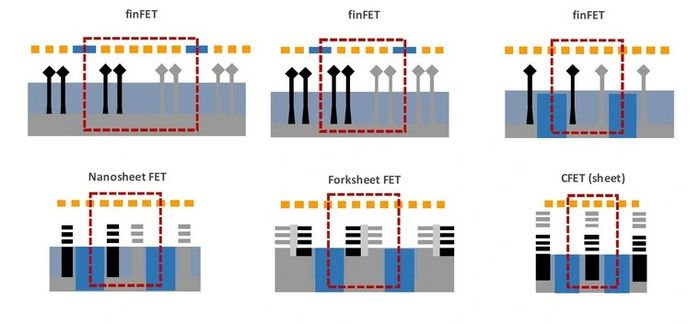
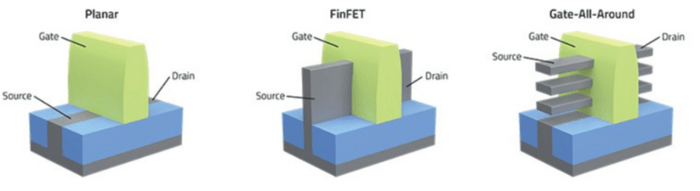
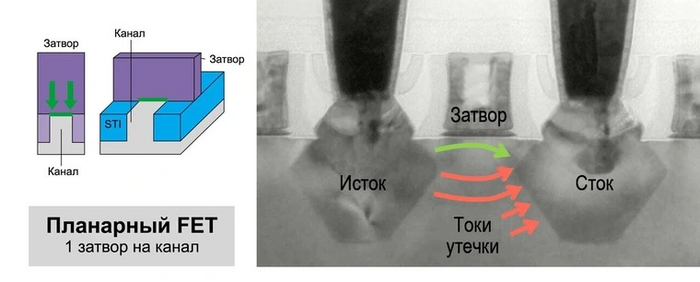
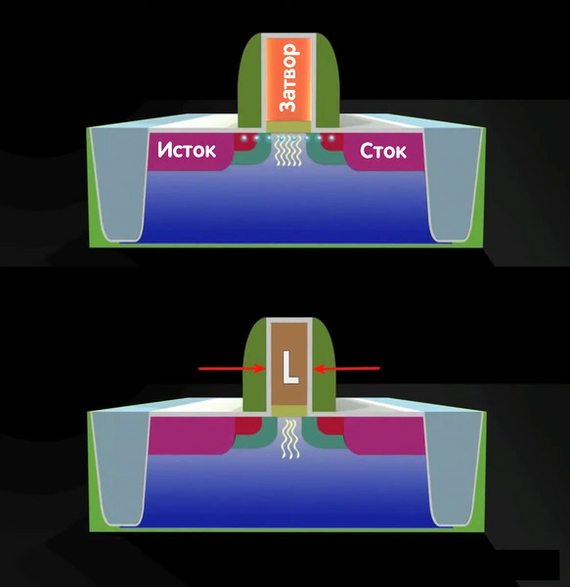
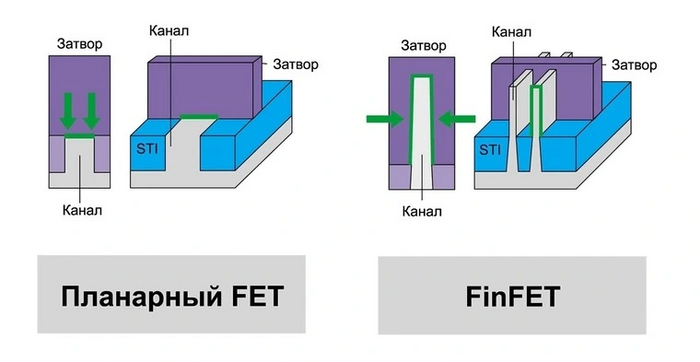
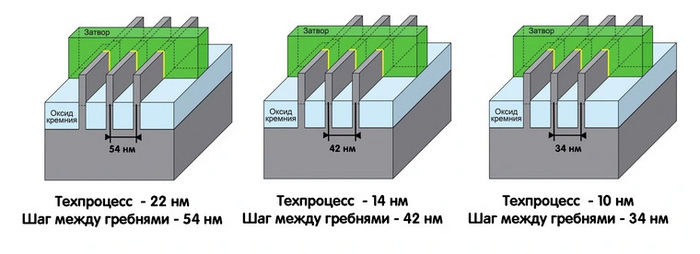
Технологии: Эволюция графики "AMD/ATI" путь развития Часть Вторая

От первых моделей с универсальными шейдерами до появления видеокарт с поддержкой современного DirectX 12.
Radeon HD2000: DirectX 10 и суперскалярная TeraScale
Компания AMD завершает сделку по приобретению ATI в конце 2006 года. Тогда же NVIDIA запускает первые карты новой линейки GeForce 8000 с поддержкой DirectX 10, которые бьют все рекорды производительности. Ответа пришлось ждать до мая 2007 года: именно тогда ATI выпускают первую карту, разработка которой частично протекала под крылом AMD — Radeon HD2900 XT.
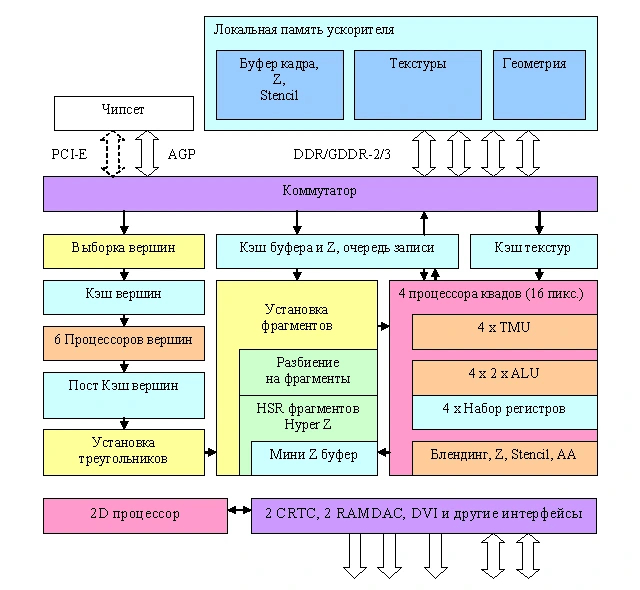
В основе модели чип R600 на новой графической архитектуре TeraScale. Она разработана с учетом API DirectX 10 и шейдеров версии 4.0. К тому же TeraScale поддерживает неграфические вычисления с помощью API под названием ATI Stream. ГП имеет 64 суперскалярных шейдерных кластера, в каждом из которых пять универсальных скалярных потоковых процессоров (SP). Четыре SP могут выполнять только простые инструкции, а пятый — более сложные. Управляет вычислительными блоками Ultra-Threaded Dispatch Processor второго поколения.
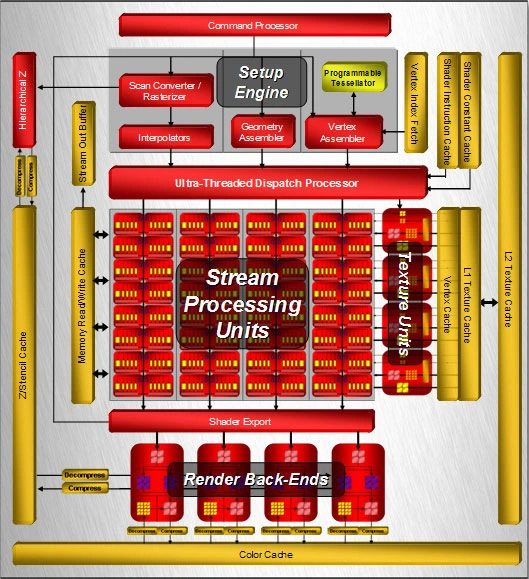
Таким образом, полный чип имеет 320 SP. Компанию им составляют 16 блоков ROP и столько же TMU, а также программируемый блок аппаратной тесселяции, который не входил в стандарт DirectX 10. Контроллер памяти имеет кольцевую шину, которую расширили до 1024 бит. Внешняя шина памяти достигла небывалых 512 бит. Чип производился по технологии 80 нм, достигнув частоты в 743 МГц. HD2900 XT могла оснащаться 512 МБ или 1 ГБ как GDDR3, так и более быстрой GDDR4, обладающей пропускной способностью в 128 ГБ/c.
R600 получил улучшения анизотропной фильтрации и режимов сглаживания: к последним добавились MSAA 8x и CFAA. Но, несмотря на 320 SP и 512-битную память, HD2900 XT не удалось догнать конкурентную GeForce 8800GTX, поэтому она позиционировалась как конкурент стоящей на ступеньку ниже 8800GTS. При этом потребление модели было очень высоким по меркам того времени — целых 215 Вт. Для организации питания карте впервые потребовалось два разъема: 6-pin и 8-pin.
Спустя месяц после старшей карты на сцену вышли средние и младшие представители линейки: модели серии HD2600 и HD2400. Карты оснащались 256 или 512 МБ памяти GDDR3 или DDR2, а старшая HD 2600 XT вдобавок получила вариант с GDDR4. Линейка HD2600 получила чип RV630 со 120 SP и 128-битной шиной памяти, а HD2400 — RV610 с 40 SP и 64-битной шиной. Производились оба ГП по технологии 65 нм. Весь ассортимент карт обеспечили три чипа: после десятка моделей ГП и трех десятков моделей видеокарт в прошлых поколениях наконец воцарился порядок.
Осенью 2007 года на базе R600 были выпущены еще две карты: HD2900 PRO и HD2900 GT. Pro-версия отличалась от флагмана сниженными частотами и выпускалась в двух версиях: с 512-битной и урезанной 256-битной шиной памяти. GT была ограничена существеннее: активными остались только 240 SP из 320, а память представляли 256 или 512 МБ 256-битной GDDR3.
Radeon HD3000: DirectX 10.1 и оптимизация
В ноябре 2007 года, спустя всего полгода после выхода первой карты серии HD2000, AMD выпускает старшие карты следующего поколения — HD3870 и HD3850.
Смекнув, что за топами NVIDIA в данный момент не угнаться, компания решила оптимизировать и перенести на 55 нм техпроцесс свои прошлые творения. Первым стал наследник чипа R600, получивший название RV670. Он обладает аналогичной конфигурацией блоков, но получил несколько нововведений. В их числе поддержка DirectX 10.1 и шейдерной модели 4.1, а также интерфейс PCI-E 2.0, который вдвое ускоряет скорость обмена данными между картой и системой.

Единственным минусом чипа стала более узкая шина памяти: теперь она стала 256-битной, а внутренняя кольцевая шина вернулась к 512-битной организации. Однако это позволило значительно упростить ГП при минимальном падении производительности, ведь 320 SP нагрузить 512-битную шину памяти в большинстве случаев были не в состоянии. За счет более тонкого техпроцесса размеры ГП удалось уменьшить вдвое, поэтому он стал обходиться намного дешевле. К тому же значительно упало энергопотребление: старшая модель потребляла всего 106 Вт.
Карты серии HD3800 показывали производительность уровня прошлой линейки HD2900, но отставали от конкурентной серии GeForce 8800 на чипе G92. Тем не менее, они стали намного популярнее предшественников благодаря более низкой цене и сниженному энергопотреблению. Последний факт позволил AMD создать свою первую двухчиповую карту — HD3870 X2. Она была запущена через два месяца после первых карт линейки и представляла собой две платы с чипами RV670, объединенные в одном корпусе. Несмотря на это, TDP карты достигало всего 165 Вт. Спустя несколько месяцев была выпущенная еще одна двухчиповая модель — HD3850 X2. Благодаря CrossFire стало возможным объединить две таких платы, тем самым получив в одной системе четыре ГП.

В январе 2008 года было представлено еще два 55 нм чипа: RV635 и RV620. Первый повторял конфигурацию RV630 из прошлой линейки и лег в основу Radeon HD3650. Карта, как и предшественник, могла оснащаться одним из трех типов памяти: GDDR4, GDDR3 или DDR2. К концу года на базе RV630 появились еще две карты — HD3730 и HD3750, отличающиеся от первой модели частотами. Младший RV620 был аналогичен RV610, и стал основой бюджетных карт серий HD3400 и HD3500.
Radeon HD4000: больше — лучше
В июне 2008 года NVIDIA представляет «тяжелую артиллерию»: карты GTX280 и GTX260 на чипе GT200. Спустя неделю AMD отвечает двумя картами новой серии — HD4870 и HD4850 на чипе RV770.
В основе RV770 все та же архитектура TeraScale, но баланс блоков изменен. ГП имеет 160 шейдерных кластеров, объединенных в 10 крупных массивов, называемых SIMD-блоками. Таким образом, полный чип содержит 800 SP — в целых 2,5 раза больше, чем в прошлом поколении. Вдобавок к этому ускорена работа с геометрическими шейдерами. Кратно возросло и количество TMU, слабое место прошлого чипа — с 16 до 40. А вот блоков ROP все также 16, хотя они подверглись улучшениям и стали работать эффективнее предшественников.
Много изменений в подсистеме обмена данными: переработана система кэширования, кольцевую шину сменила схема с центральным хабом, а контроллер памяти получил поддержку быстрой GDDR5. Несмотря на 256-битную шину, это позволяет достичь пропускной способности в 115 ГБ/c — лишь немногим меньше, чем 512-битная шина вместе с GDDR4. Памятью GDDR5 оснащалась топовая HD4870, а младшая 4850 получила привычную GDDR3 и пониженную частоту ядра. При всех улучшениях, карты вышли довольно экономичными — TDP старшей модели не превышал 160 Вт.

Как и в прошлой линейке, AMD придерживалась правила «дешево и сердито». HD4850 была на уровне конкурентной 9800GTX, а HD4870 приближалась к GTX260, намного более дорогой и сложной карте — и все это при более низкой цене. Для конкуренции с топовой GTX280 в августе была выпущена двухчиповая HD4870 X2. Она не давала и шанса топовой GeForce в играх, оптимизированных под CrossFire, но потребляла прилично — до 286 Вт. В ноябре появилась и ее двухголовая «сестра» — HD4850 X2.
Сентябрь 2008 года принес младшие серии Radeon HD4600, HD4500 и HD4300. Эти карты стали последними моделями, у которых имелась разновидность с AGP-интерфейсом. Старшая серия базируется на чипе RV730. Он получил 320SP и 128-битную шину, с которой могли использоваться три типа памяти: GDDR4, GDDR3 и DDR2. Две младшие серии получили RV710 — чип с 120 SP и 64-битной шиной памяти, оснащавшейся DDR2 или DDR3. В этом поколении только у младших карт остались версии с 256 МБ памяти. Средние и старшие модели выпускались в двух вариантах: с 512 МБ или 1 ГБ.
В октябре появляется первая видеокарта на базе урезанного RV770 — HD4830. Карта обладает 640 SP и 256-битной памятью GDDR3. В 2009 году к ней добавятся еще две модели с таким же чипом, но 128-битной памятью GDDR5 — HD4810 и HD4730.

В апреле 2009 года серия Radeon HD4700 пополнится еще одной моделью — HD4770. Она обладает новым чипом RV740, который изначально имеет 640 SP и 128-битную шину GDDR5, и производится по техпроцессу 40 нм. Так компания решила «обкатать» техпроцесс перед запуском новой линейки видеокарт. Одновременно был выпущен обновленный топ HD4890 на чипе RV790. Он представляет собой RV770, оптимизированный для достижения более высоких частот — 850 МГц и выше. Новая модель составила достойную конкуренцию GTX275.
Сентябрь 2009 года принес неожиданное расширение серии Radeon HD4000. HD4750 стала второй картой на основе RV740, а HD4860 — второй моделью на RV790. При этом последний чип был урезан до 640 SP, чего хватило для борьбы на равных с главным «врагом» GTS250.
Radeon HD5000: первые с DirectX 11
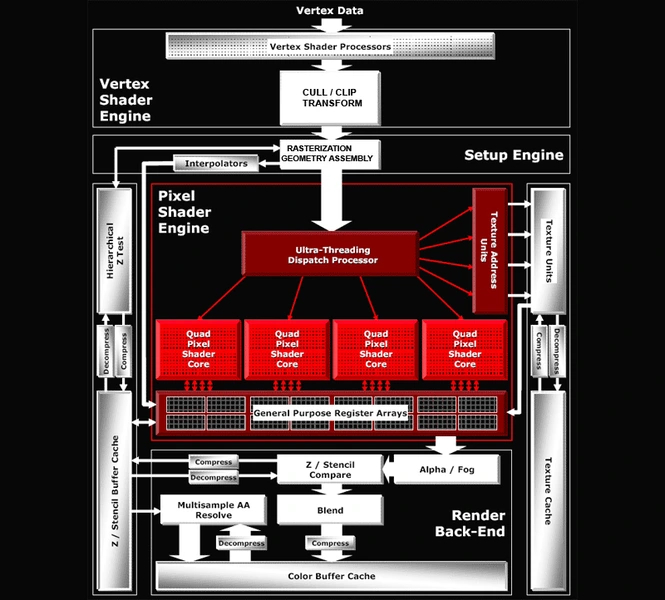
В конце сентября 2009 года AMD запускает новую линейку видеокарт Radeon HD5000. Ее первые представители: HD5870 и HD5850. В отличие от прошлых линеек, это топовые решения, предназначенные для борьбы с флагманами конкурента. Карты получили поддержку DirectX 11, принесшего шейдеры версии 5.0, аппаратную тесселяцию и вычисления DirectCompute. Это заслуга обновленной архитектуры TeraScale 2.
Чип, используемый в картах серии, получил кодовое имя Cypress. Он производился по техпроцессу 40 нм. Внутреннее строение довольно схоже с RV770, но всех блоков стало вдвое больше: 20 SIMD, 320 шейдерных кластеров, 1600 SP, 32 ROP и 80 TMU.
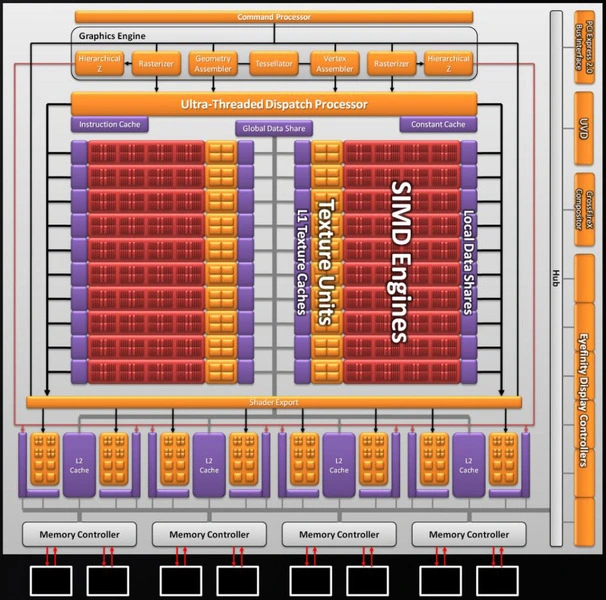
Блок тесселяции, присутствующий во всех чипах еще с R600, был доработан для поддержки стандартной тесселяции DirectX 11. Шейдерные процессоры получили поддержку новых видов инструкций, а кэши ГП ускорились. Шина осталась 256-битной, но контроллер получил поддержку более высокочастотной памяти, за счет чего полосу пропускания удалось увеличить до 153.6 ГБ/c.
Такие характеристики получила старшая HD5870. Младшая HD5850 отличалась сниженными частотами и урезанным до 1440 SP чипом. Тем не менее, обе модели обгоняли карты серии GTX200. Ответ от NVIDIA последовал лишь полгода спустя — топовые GTX480 и GTX470 опережали продукцию AMD при использовании тесселяции, но без нее были на одном уровне. К тому же HD5870 потребляла значительно меньше энергии, чем конкурентная GTX480 — 188 Вт против 250 Вт. Раннее появление на рынке и более скромное энергопотребление склонило чашу весов пользователей в сторону карт AMD.
Спустя месяц после старших карт были выпущены HD5770 и HD5750 на базе более скромного чипа Juniper, являющегося «половинкой» Cypress. ГП обладает 128-битным интерфейсом памяти, но использует такую же быструю память GDDR5, как и старшие карты. Карты стали популярными за счет производительности уровня HD4870 и HD4850 при гораздо меньшем энергопотреблении. GTS450 от конкурента выйдет годом позже и будет медленнее старшей HD5770.
Вслед за этими картами последовал новый двухчиповый король графики — HD5970. Карта представляет две HD5870 на одной плате и почти на полтора года станет самым быстрым двухчиповым ускорителем на рынке. При этом потребление по сравнению с 4870 X2 увеличилось несильно — до 294 Вт.

Февраль 2010 года принес еще одну вариацию Cypress — HD5830 с активными 1120 SP, а также новинки на двух бюджетных чипах. ГП Redwood имеет 400 SP и 128-битную шину, которая поддерживает память GDDR5, GDDR3 и DDR2. Он лег в основу моделей серий HD5600 и HD5500, среди которых только младшая HD5550 получила урезанный чип. Чип Cedar — самый младший в линейке. Имея всего 80 SP и 64-битную шину памяти, он нашел приют в единственной модели — HD5450.
Radeon HD6000: последние представители TeraScale
В октябре 2010 года AMD выпускает две видеокарты, относящиеся к новой линейке — HD6870 и HD6850. В них используется чип Barts на архитектуре TeraScale 2, который по сравнению с Cypress получил меньшее количество вычислительных блоков, но обзавелся ускоренным блоком тесселяции. В ГП 14 SIMD, 224 шейдерных кластера, 1120 SP, 32 ROP и 56 TMU. Шина памяти, как и у Cypress, 256-битная с поддержкой GDDR5.
HD6870 получила полный чип, HD6850 — урезанный до 960 SP. Карты предназначались для замены HD5870 и HD5850 и были немного медленнее своих предшественников, но и стоили при этом дешевле. В апреле 2011 года появилась еще одна карта на ГП Barts, HD6790. Она растеряла почти треть SP — активными остались только 800 штук.
В ноябре 2010 года NVIDIA выпускает первого представителя серии GTX500: топовую GTX580. Карта унаследовала от предшественницы архитектуру Fermi, но лишилась ее основных недостатков — урезанного чипа и пониженной частоты. В ответ на это спустя месяц AMD представляет топовые карты нового поколения: Radeon HD6970 и HD6950.
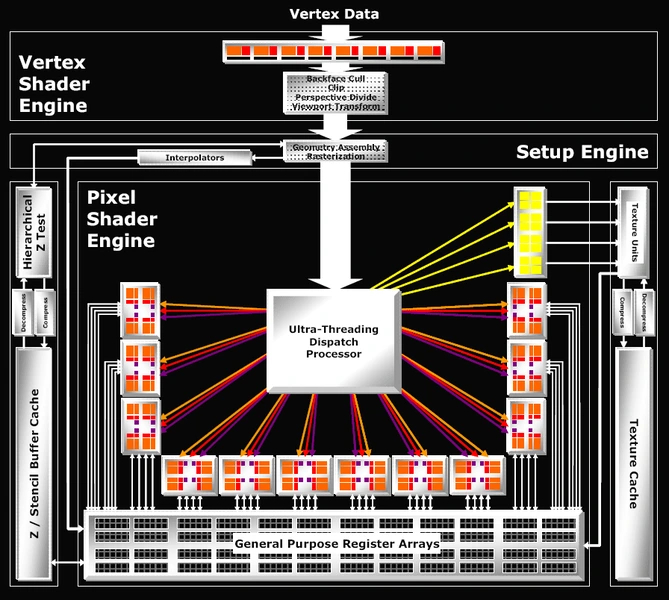
Модели построены на чипе Cayman, который использует обновленную архитектуру TeraScale 3. Основу чипа составляют все те же суперскалярные шейдерные кластеры. Но теперь в каждом из них не пять, а четыре SP, что позволяет более эффективно загружать их. Поэтому, несмотря на то, что в Cayman оказалось чуть меньше SP, он стал немного быстрее Cypress.
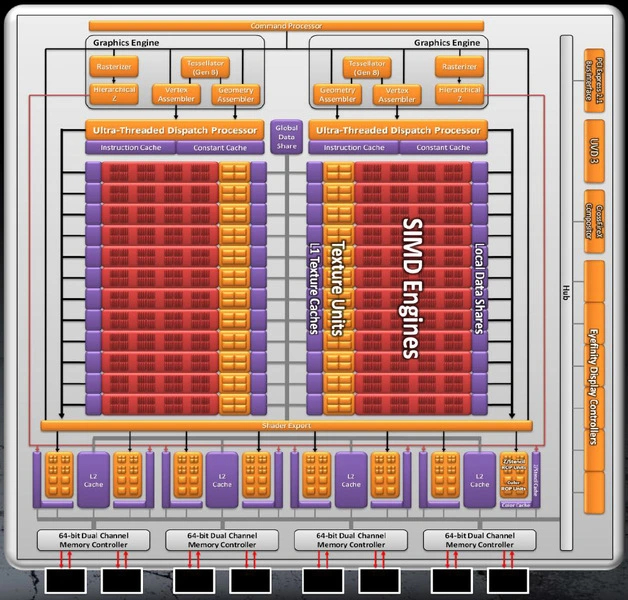
Полный чип содержит 24 SIMD, 384 суперскалярных блока и 1536 SP. Вычислительные блоки разделены на две части, каждой из которой управляет отдельный Ultra-Threading Dispatch Processor. Блоков геометрии и тесселяции теперь тоже по два. Каждый из них до полутора раз быстрее, чем у предшественника. Полный чип обладает 32 блоками ROP и 96 TMU. Шина памяти осталась 256-битной, но пропускная способность за счет более быстрых чипов GDDR5 возросла до 176 ГБ/c. Среди новых технологий — поддержка сглаживания EQAA.
Флагманская HD6970 получила полный чип, а субфлагман HD6950 — урезанный до 1408 SP. Стандартный объем памяти карт был увеличен до 2 ГБ. Несмотря на это, конкуренции с GTX580 не получилось — старшая карта была на уровне GTX570, а младшая — немного медленнее ее, хотя потребляли карты довольно много: до 250 Вт. Спустя год чип Cayman ляжет в основу еще одной модели — HD6930, в чипе которой оставили 1280 активных SP.
В марте 2011 года оба производителя карт выпускают свои топовые двухчиповые ускорители: NVIDIA — GTX590, а AMD — HD6990. И тут компания отыгралась: решение конкурента было немного медленнее. Однако HD6990 поставила рекорд по энергопотреблению — целых 375 Вт.

Спустя месяц на сцену выходят HD6770 и HD6750. AMD не стала разрабатывать для карт новые чипы: обе модели представляют из себя переименованные HD5770 и HD5750 на ГП Juniper. То же относится и к HD 6350 — это переименованная HD5450 на ядре Cedar. А вот промежуток между средним производительным сегментом и откровенно бюджетным компания заполнила новыми чипами: Turks и Caicos.
Несмотря на новизну, в основе пары чипов старая архитектура TeraScale 2. Turks имеет 480 SP и 128-битную шину памяти, поддерживающую как GDDR5, так и более медленную GDDR3. Он лег в основу моделей HD 6670 и 6570. Caicos, имеющий всего 160 SP и 64-битную шину памяти DDR3, использовался в единственной модели — HD 6450.
Radeon HD7000: DirectX 11.1 и скалярная GCN
В январе 2012 года начинается новая глава в истории графики AMD. Тогда были выпущены первые карты на основе совершенно новой графической архитектуры — Graphics Core Next (GCN). В отличие от суперскалярной TeraScale, GCN является скалярной архитектурой. Это значит, что ее блоки можно нагрузить гораздо эффективнее, чем блоки предшественницы. К тому же и для неграфических вычислений такая архитектура подходит куда больше.
Основой новых ГП являются вычислительные блоки (CU). В одном блоке содержатся 4 TMU и 64 SP, поделенных на четыре группы. Каждая из них работает со своим потоком команд, которые задает планировщик исполнения, имеющийся внутри CU.
Первыми картами на основе GCN стали HD7970 и HD7950 на базе ГП Tahiti. Чип имеет 32 CU, которые образуют 2048 SP и 128 TMU. Управляют ими процессор графических команд и два движка асинхронных вычислений (ACE). Благодаря этому ГП поддерживает одновременно три потока команд — один графический и два вычислительных, каждым из которых могут заниматься произвольное число CU.

Как и предшественник, Tahiti имеет два блока обработки геометрии и тесселяции. Они были переработаны и значительно оптимизированы, благодаря чему стали от трех до четырех раз быстрее, чем у чипа прошлого поколения. Таким образом, в этом поколении один из главных недостатков карт AMD по сравнению с конкурентом — медленная работа тесселяции — был устранен.

В прочее оснащение чипа входят 32 блока ROP. Память представляет 384-битная шина, которая вкупе с GDDR5 обеспечивает полосу пропускания 264 ГБ/c. ГП получил интерфейс PCI-E 3.0, который в очередной раз удваивает скорость «общения» карты с системой. Вдобавок к этому имеется полная поддержка DirectX 11.1, частичная — DirectX 11.2. Хотя для производства используется 28 нм техпроцесс, максимальный TDP такой же, как у предшественников — 250 Вт.
Топовая HD7970 получила полный чип, HD7950 — урезанный до 1792 SP. Обе карты имели 3 ГБ памяти и обгоняли GTX580, но реальный противник для них был представлен лишь спустя два месяца. GTX680 на старте была немного быстрее HD7970, как и вышедшая позже GTX670 по сравнению с HD7950.
Однако карты AMD могли работать на более высоких частотах, и уже летом 2012 года компания представила две обновленные модели — HD7950 Boost и HD7970 GHz Edition. Эти модели первыми получили поддержку динамического увеличения частоты ядра, аналогично технологии GPU Boost конкурирующей NVIDIA. Обновленные карты сравнялись с конкурентами, а спустя некоторое время стали обгонять их в новых играх — сказывалась оптимизация архитектуры, более высокая пропускная способность памяти и ее больший объем.

Февраль 2012 года принесет бюджетный чип архитектуры GCN — Cape Verde. Он содержит 640 SP и комплектуется 128-битной шиной памяти. Одновременно будут выпущены две карты на его основе: старшая HD7770 с полным чипом и младшая HD7750 — с урезанным до 512 SP. Cтаршая модель стала первой картой компании, частота ядра которой достигла 1 ГГц. Обе модели имеют варианты с 1 и 2 ГБ памяти GDDR5. В апреле 2013 года на базе этого чипа выйдет еще одна модель — HD7730. В ней останутся активными только 384 SP, а к варианту с GDDR5 добавится более бюджетный с DDR3.
В марте 2012 года были представлены карты серии HD7800 на чипе Pitcairn. Он получил 1280 SP и 256-битную шину памяти. Старшая HD7870 получила полный чип и 2 ГБ памяти. В младшей HD7850 осталось активными 1024 SP, а к 2 ГБ варианту добавился более бюджетный с 1 ГБ памяти. В ноябре 2012 года была представлена HD7870 XT. В ее основе старший чип Tahiti, в котором остались активными 1536 SP. Помимо этого, карта получила урезанную до 256 бит шину, вследствие чего ей достались лишь 2 ГБ памяти.
Младшие линейки новой серии представляют собой переименованные карты прошлого поколения на архитектуре TeraScale 2. Все модели линеек HD7600, HD7500, HD7400 и HD7300 обладают аналогичными характеристиками с картами серий HD6600, HD6500, HD6400 и HD6300.
В апреле 2013 года выходит двухчиповая HD7990, представляющая собой пару HD7970 на одной плате. Несмотря на то, что карта вышла на год позже конкурентной GTX690, она показывала сравнимую с ней производительность и была быстрее имиджевой GTX Titan.
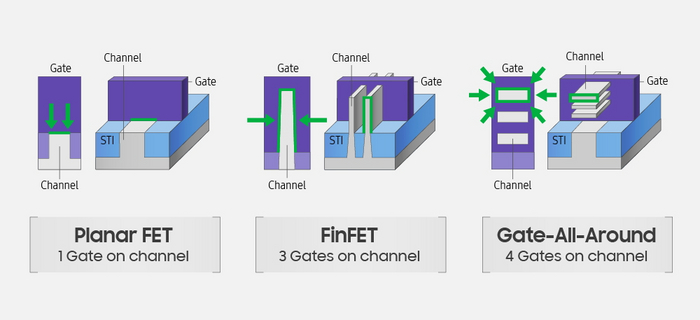
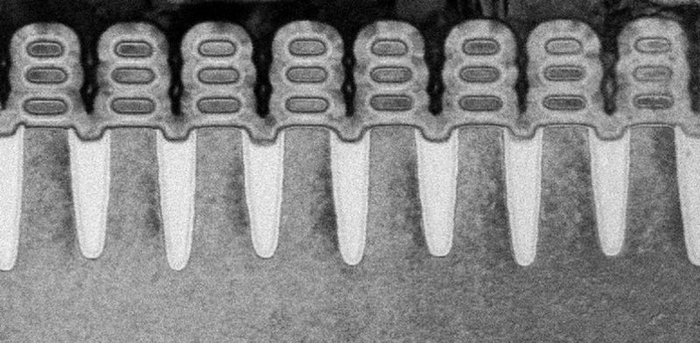
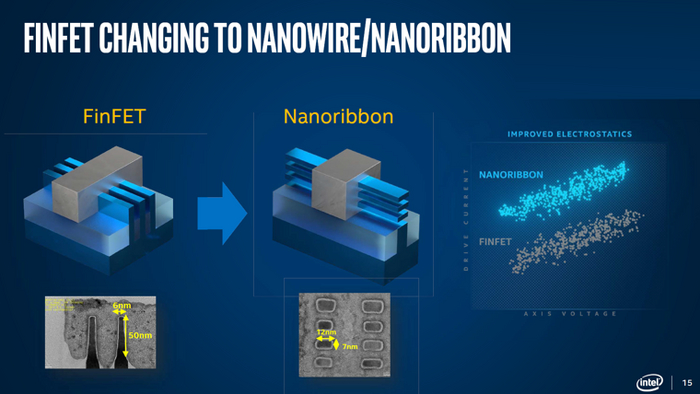
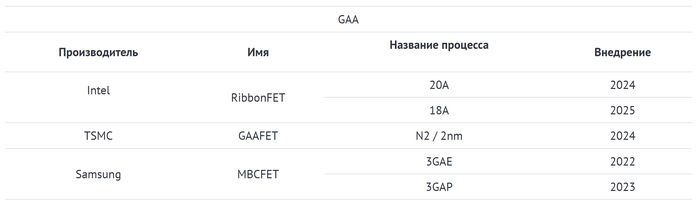
С выходом ОС Windows 10 карты серии HD7000 на архитектуре GCN получили частичную поддержку DirectX 12. Но полной совместимостью с новым API обзаведётся только следующее поколение карт — Radeon R200, с которого начнется значительная часть современной истории графики AMD.