1. Научные труды о применении методов нормального распределения результатов голосования для их оценки
Много научных работ было посвящено выявлению социальных и социально-психологических факторов, обуславливающих выбор избирателей и влияющих на общий результат голосования. П. Лазарсфельд, Б. Берельсон и Х. Годэ заложили основу для понимания роли социальных факторов в электоральном поведении. С. М. Липсета и С. Роккана выявили механизм расколов и продемонстрировали, как противоречия между широкими группами людей находят отражения в электоральном процессе. Часть расколов носит очевидно географический характер (например, раскол «город и село»).
Из работ Р. Инглхарта, К. Брукса и Дж. Манзы следует, что расколы в предпочтениях избирателей по-прежнему играют важную роль в структурировании электорального процесса, но с течением времени претерпевают изменения по форме и степени влияния. Релевантность механизма расколов для постсоциалистического пространства нашла подтверждение в работах Б. Димитровой, Г. Китшельта, Г. Голосова и Ю. Шевченко. Положения социологического подхода нашли своё развитие и расширение в рамках социально-психологической школы исследования
электорального поведения, к изучению которого достаточно системно подошли Э. Кемпбелл, У. Миллер, П. Конверс, Д. Стоукс, С. Люис-Бек, У. Джакоби, Х. Норпот, Г. Вайсберг. Эти учёные являются основоположниками современных практик электоральных исследований, базирующихся на опросной технике, как на научно-обоснованной теории проведения оценок
предпочтений избирателей.
Современные исследователи довольно далеко ушли от тривиального понимания парадокса явки и регулярно обращаются к рассмотрению ценностных и морально-этических мотивов поведения конкретных групп избирателей, когнитивным аспектам и т.д. (А. Блэ, С. Канадзава, Дж. Вун, О. Эврен, Дж. Макмюррей, А. Диган и А. Мерло).
Ряд ученых (А. Лейпхарт, В. Линдер, Ф. Леук, Н. Финсераас, Г. Такер, М. Мартинес и др.) указывают на наличие значимой связи между уровнем явки и результатами выборов, что пытаются отрицать сторонники «нормального распределения» голосов избирателей.
С недавнего времени в Интернете (не в научных изданиях) стали появляться материалы, связанные якобы с математической оценкой результатов выборов посредством сравнения распределения голосов в зависимости от явки с «нормальным распределением» («гауссовское
распределение», «колоколообразное распределение»), применяемых для идентичных сред и случайных процессов.
По мнению сторонников такого подхода, фальсификация результатов голосования должна обнаружить себя в виде электоральных аномалий – статистических свойств данных, которые отклоняются от средних величин и не укладываются в рамки математических моделей распределения случайных чисел.
Нацеленность авторов подобных теорий на заранее определенный политический результат превратило это направление исследований в область псевдонаучных измышлений. Подобные негативные тенденции уже были замечены некоторыми исследователями.
«Широко распространена вера в то, что статистические данные часто подчиняются нормальному распределению. Между тем анализ конкретных результатов наблюдений, в частности, погрешностей измерений, приводит всегда к одному и тому же выводу – в подавляющем большинстве случаев реальные распределения существенно отличаются от нормальных», - отмечал в своих работах советский и российский математик, экономист статистик, социолог и кибернетик А.И. Орлов.
В современной науке не существует однозначных аргументов, обосновывающих гипотезу о том, почему определённый вид социологического распределения должен подчиняться нормальному
распределению. «Во многих случаях предположение о нормальности обосновать довольно трудно, а подчас можно точно сказать, что распределение резко отличается от нормального», – указывал Александр Крыштановский, советский и российский социолог, математик, один из основателей и первый декан факультета социологии Государственного университета – Высшей школы экономики (ГУ-ВШЭ), специалист по методике социологических исследований и методологии анализа социологических данных.
Аналогичных позиций придерживается и Александр Орлов: «Как показали многочисленные исследования, почти все распределения реальных данных не принадлежат ни одному из известных параметрических семейств».
При обработке конкретных данных иногда считают, что погрешности измерений имеют нормальное распределение. На предположении нормальности построены классические модели регрессионного, дисперсионного, факторного анализов, метрологические модели, которые еще продолжают встречаться как в отечественной ноpмативно-технической документации, так и в международных стандартах. На то же предположение опираются модели расчетов максимально достигаемых уровней тех или иных характеристик, применяемые при проектировании систем обеспечения безопасности функционирования экономических структур, технических устройств и объектов. Однако теоретических оснований для такого предположения нет. Необходимо экспериментально изучать распределения погрешностей.
Погрешности измерений в большинстве случаев имеют распределения, отличные от нормальных. Это означает, в частности, что большинство применений критерия Стьюдента, классического регрессионного анализа и других статистических методов, основанных на
нормальной теории, строго говоря, не является обоснованным, поскольку неверна лежащая в их основе аксиома нормальности распределений соответствующих случайных величин.
Правила отбраковки, основанные на использовании конкретной функции распределения, являются крайне неустойчивыми к отклонениям от её распределения элементов выборки, а гарантировать отсутствие подобных отклонений невозможно. Поэтому отбраковка по классическим правилам математической статистики не является научно обоснованной, особенно при больших объемах выборок. Указанные правила целесообразно применять лишь для выявления «подозрительных» наблюдений, вопрос об отбраковке которых должен решаться из соображений соответствующей предметной области, а не из формально-математических соображений.
В 2018 году факультет политологии МГУ им. М. В. Ломоносова провел исследование «Политика и математика: феномен распределения Гаусса», в котором авторы пришли к однозначному выводу: «Нормальное распределение работает со случайными величинами. Оно прекрасноможет иллюстрировать некоторые физические процессы, но не осознанный выбор миллионов людей, различающихся по месту проживания, достатку, национальности и другим атрибутам».
Аналогичную позицию относительно нормального распределения голосов публично выражает заведующий кафедрой методологии социологического исследования социологического факультета МГУ Юрий Аверин, который считает, что кривой Гаусса можно описать только случайные события: «Выборы не попадают в эту категорию. Хотя некоторая часть избирателей, до 10 – 15%, голосует случайным образом, остальные делают абсолютно осознанный выбор».
Еще жестче звучат аргументы экономиста Нассима Талеба, утверждающего, что «кривая нормального распределения – великий интеллектуальный обман».
Справедлива и обоснована позиция профессора НИУ ВШЭ Леонида Владимировича Полякова: «Стремление привлечь математические и статистические методы для изучения политических процессов абсолютно легитимно и не вызывает никаких вопросов. Но есть некая граница, где чисто исследовательская работа вступает в область уже не политологических, а чисто политических интерпретаций. Те, кто пытается использовать для анализа электорального процесса кривую Гаусса, отталкиваются от спорных исходных данных: всех избирателей считать одинаковыми. Но избиратели по определению по-разному ориентированы, по-разному мотивированы и принадлежат к разным социальным группам. Сама неоднородность исследуемого материала уже противоречит исходной теоретической предпосылке».
Сомнительным аргументом авторов нормального распределения является и то, что корреляция между уровнем явки на выборах и голосованием за провластных кандидатов свидетельствует о вбросе бюллетеней и «накрученной явке». По мнению сторонников «электоральной теории Гаусса», относительно других партий или кандидатов такой закономерности якобы не наблюдается. Исследователи факультета политологии МГУ отмечают, что такая корреляция очевидна, если рассматривать консервативные слои населения, например сельских жителей
или пенсионеров, отличающихся конформистским поведением и склонных голосовать за действующую власть. И на тех участках, где эти слои преобладают и демонстрируют высокую явку, выше будет и голосование за партию власти.
Все попытки сравнивать графики голосования за разных кандидатов и партии и делать какие-то выводы лишь потому, что линии различаются по кривизне, не имеют никаких теоретических обоснований.
«Кажущиеся странными закономерности в данных голосования не обязательно указывают на мошенничество», – достаточно мягко отмечается в исследовательской работе, размещенной на сайте электронной библиотеки Кембриджского университета США.
Исследование Нью-Йоркского университета еще более четче резюмирует возможности выпадения «любых комбинаций» в итогах голосования: используя аналитические результаты и моделирование, четко показано, что сама по себе частота грубого распределения доли голосов по участкам (0,50, 0,60, 0,75…) вполне вероятна из-за простых числовых законов и сама по себе не является доказательством мошенничества.
В 2016 году в Санкт-Петербургском государственном университете была защищена кандидатская диссертация «Электоральные аномалии в постсоциалистическом пространстве: опыт статистического анализа». Ее автор Н.Е. Шалаев в своем научном исследовании приходит к однозначному выводу: анализ распределения цифр в рамках известных методов неприменим для поиска электоральных аномалий.
С другой стороны, как отмечает Н.Е. Шалаев, хорошо известна проблема мониторинга выборов и способов манипуляций результатами голосования. Одними из наиболее видных авторов в этой области являются С. Хайд, Дж. Келли и А. Симпсер. В частности, работы последнего революционализировали представления об электоральных фальсификациях, продемонстрировав, что они носят не только инструментальный, но и важный информационный характер, который всегда задействуется в интересах политических акторов.
Как отмечает социолог И.В. Задорин, выявление причин отклонения результатов голосования от нормального распределения не входит в зону ответственности избирательных институтов и зачастую остается полем спекуляций разных заинтересованных сторон. К сожалению, эти спекуляции, интерпретирующие необычные результаты голосования на конкретных избирательных участках исключительно как следствие сознательных фальсификаций, как правило, являются частью политтехнологий, использующихся для делегитимации результатов выборов.
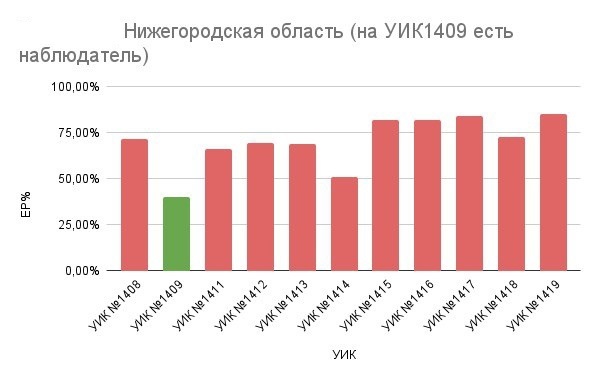
На практике отдельные территории демонстрируют существенно «необычные» для среднестатистических показатели электорального поведения (сплошная/повышенная явка, повышенная/пониженная доля голосования за определенного кандидата, сильная неравномерность голосования по времени дня, одинаковость результатов с другими соседними
объектами и т.п.). Интерпретация таких «аномалий» может быть очень разной и объясняться разными причинами: от ошибок в работе избирательных комиссий и особенностей прошедшей избирательной кампании до реальных объективных особенностей конкретного избирательного округа (больница, ЗАТО, военная часть и т.п.).
С научной точки зрения результаты исследования наглядно демонстрируют, что на современном этапе развития поиск электоральных аномалий оказался в интересах достижения поставленного политического эффекта, сфокусирован на наименее плодотворном подходе к анализу агрегированных данных об электоральном поведении, фактически построенном на исследовании частоты цифр. А географический анализ аномалий оказался несправедливо и преднамеренно маргинализированным, хотя именно он не только выделяет наличие нормы в характеристиках электорального поведения, но и позволяет выявлять аномальные случаи
конкретно и точечно, что является невозможным для всех остальных известных методов анализа.
Уф..... Далее в докладе идёт подробный разбор всех графиков и комментариев. И там несколько десятков страниц текста. Думаю, что тем, кто заинтересовался эти могут продолжить:
2. Соотношение результатов выборов и выводов «электоральных математиков»