Как читают ДНК. Патент US5302509A

Если бы прогресс в ракетостроении был бы таким, как в чтении ДНК, то у каждого сейчас был бы персональный космический корабль! На первое секвенирование генома человека было потрачено $3 миллиарда и продолжалось оно около 15 лет. Сейчас это стоит $1000 и делается за пару дней.
Все секвенциальные машины сейчас производит компания Illumina. Никто ничего лучшего придумать не может. Про технологию этой компании я и расскажу в посте.
Основная идея метода была описана еще в 1989 году в патенте "Метод секвенирования полинуклеотидов".
В этом методе предлагается разделить двойную спираль ДНК на одиночные "нитки", "пришить" их c одного конца к твердой поверхности, добавить ДНК-полимеразу, которая прицепится к противоположному концу и начнет "ремонтировать" ДНК, достраивая вторую цепь. (Для тех кто знает - да это ПЦР).
Обычно полимераза быстро двигается вдоль одиночной цепи ДНК, останавливается на каждой "букве", подбирает подходящую (комплементарную) "букву" для второй цепи из окружающего раствора и присоединяет ее к концу второй цепи. Вторая цепь строится строго по правилу "комплементарности" - напротив "A" одной цепи, должно быть "T" другой цепи, а напротив "G" должно быть "C".
Однако здесь в качестве "строительного материала" для второй цепи предлагается использовать модифицированные "буквы" (нуклеотиды). Во первых, к ним приделана цветная метка, причем у каждой буквы свой цвет. А во вторых, они останавают работу полимеразы, как только она добавляет их в цепь. Полимераза "застревает" на только что пришитой "букве" и процесс встает "на паузу".
В этот момент мы смываем весь "свободный строительный материал" и фотографируем под микроскопом поверхность с прикрепленной ДНК. Получается вот такая картинка:

Цветные точки - это буквы "застрявшие" в полимеразе, прикрепленной к ДНК. По цвету мы можем определить, где какая "буква" застряла.
Затем заливаются реагенты, которые убирают все модификации у застрявшего "стройматериала", снова добавляют цветной "стройматериал", полимераза делает шаг, встраивает следующую "букву" и опять "застревает".
Опять все смываем, фотографируем поверхность и определяем буквы, которые "застряли" на следующем шаге в тех же точках.
И т.д.
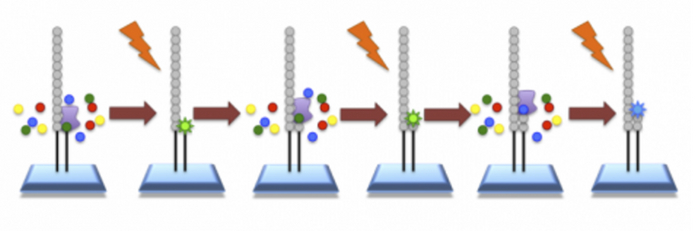
Весь этот процесс делается секвенатором автоматически.
Циклы секвенатор повторяет раз 150-300. Таким образом мы читаем кусочки ДНК длиной 150-300 "букв". (Больше не получается, так как падает качество чтения.) Но метод позволяет читать много молекул параллельно. Современная Illumina секвенсор способен читать миллиарды молекул параллельно!!! Мы можем разрезать длинную ДНК на небольшие молекулы, прочитать их, а затем специальной программой собрать прочитанные кусочки вместе.
Одного запуска секвенатора вполне хватает на чтение десятка человеческих геномов, причем каждый еще будет прочитан много раз (это делается, чтобы скорректировать ошибки чтения).
Вот как выглядит самый маленький, "лабораторный" секвенатор, способный прочитать "только" 25 миллионов молекул за запуск.

Кто-то может засомневаться и подумать, что даже в микроскоп увидеть свечение одной молекулы невозможно (или крайне сложно). И будет прав! Я упустил важную деталь. В самом начале, после прикрепления ДНК к поверхности и перед началом чтения запускается специальный процесс ПЦР, который делает тысячи копий прикрепленной ДНК, причем копии остаются прикрепленными практически в той-же точке. Т.е. цветная точка - это тысячи одинаковых молекул и их вполне видно в простой микроскоп.
PS.
Планирую набросать постов по статистическому анализу (по опыту знаю, что даже технари это практически не изучают). В какое сообщество писать еще не знаю, так что подписывайтесь на меня, кому интересно.