Так, продолжаем разбираться с моделями. В первой части мы узнали что такое модель, прочитали про основные виды (тренированные и миксы) и узнали где их качать.
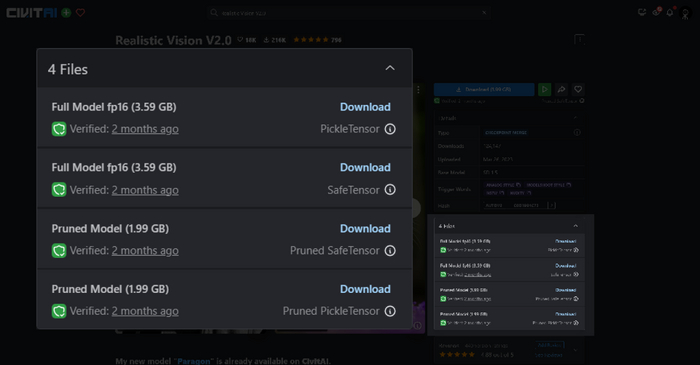
Мы довольные, резкий кликом мышки открываем civitai, выбираем понравившуюся модель, например Realistic Vision, открываем менюшку с файлами для скачивания и что мы видим
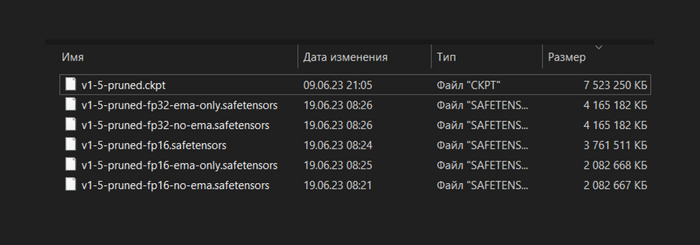
Какие-то Full, Pruned, fp, SafeTensor, PickleTensor. При этом еще и разница между файлами в несколько гигабайт. Можно мне ту которая будет картинки делать?
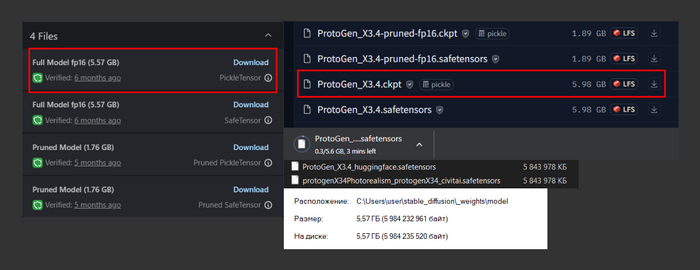
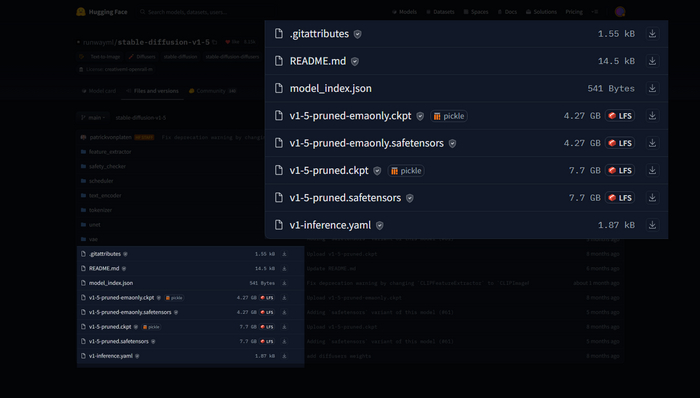
Ладно, испытаем удачу на huggingface, скачаем основную модель 1.5. Что может быть сложнее, правда?
Опять эти pruned'ы, еще и ckpt, safetensors и emaonly откуда-то взялись
Похоже придется чутка разобраться.
Небольшой дисклеймер: задача этой статьи - чтобы вы поняли какую модель качать. Где возможно, будет опущено и упрощенно все техническое, потому что на каждый раздел можно привести пачку статей которые объяснят как это работает, и еще пачки три, чтобы +- схватить базу на которой это все построено, начиная от статей как stable diffusion в принципе работает и небольшой доки по safetensors и заканчивая стандартами типа IEEE-754
Начнем с конца - расширения
У нас есть два основных формата:
ckpt (pickle tensor) - это стандартный формат для моделей, которые мы используем с SD. Их минус в том, что при желании в файл можно запихнуть вредоносный код, который выполниться, когда мы загрузим модель.
safetensors (safetensor) - доработанный формат для моделей, суть существования которого в том, чтобы нельзя было засунуть в модель что-то вредное. Также модель в этом формате грузиться быстрее чем модель в формате ckpt. (имеется в виду именно загрузка, например когда мы переключаем модели, а не скорость генерации картинок)
Разницы при генерации картинок нет абсолютно никакой. Содержимое, что модели ckpt, что модели safetensors одинаковое.
Поэтому если есть safetensors - берем safetensors, если нет качаем ckpt и пользуемся.
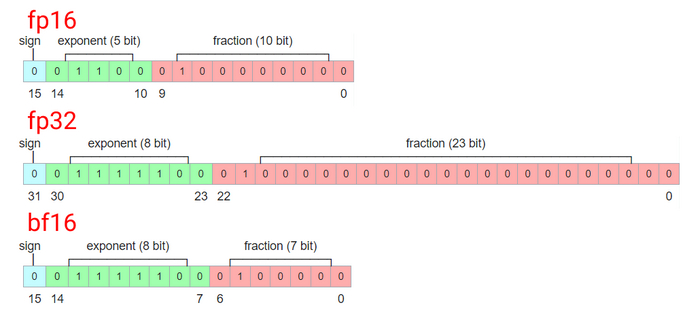
fp16/fp32/bf16
Компьютер все считает в числах. Числа нужно как-то хранить в памяти. Тут у нас классическая дилемма:
Если мы выделяем больше памяти, то числа будут точнее (больше), но требуется больше места и расчеты с ними проводить сложнее.
Если мы выделяем меньше памяти, то числа будут менее точными (меньше), но занимать они будут сильно меньше места и считаться значительно быстрее.
fp - это floating point (numbers), то есть (число) с плавающей точкой, например 0.00548219 или 7743.123, именно такой формат чисел и используется в моделях. (потому что могут еще быть просто числа, типа 10 или 66492, для нас, как говорил великий, шо то, шо это, но для компьютера это большая разница)
16 или 32 - число бит, которые мы выделяем для каждого числа. Как несложно заметить разница в два раза. В машинном обучении 32 это стандарт, а если нужно другое - конвертируют
Соответственно, fp32 значит, что в нашей модели для каждого числа выделяется 32 бита, а в fp16 - всего 16. Поэтому модели fp16 весят в +- два раза меньше чем fp32 и картинки генерируют быстрее.
bf16 - это попытка и рыбку съесть и косточки продать: места нужно как для fp16, но точность больше. Не все видеокарты поддерживают, не везде применяется, поэтому пропустим.
При генерации картинок результаты моделей fp16 не принципиально отличаются от fp32, поэтому если мы скачиваем модель погенерить, можно спокойно брать fp16. Если же мы выбираем модель, чтобы на ней тренировать что-то (модель, лору и тд), то лучше брать fp32 модель.
pastelmix и waifu diffusion
По умолчанию, автоматик все старается считать в fp16, поэтому то что у нас модель fp32, по сути влияет только на размер файла. Если хотите сравнить скорость генерации, то добавьте к параметрам запуска --no-half и у вас всегда будет считать в fp32
no-EMA/EMA-only
Тут для понимания лучше будет начать с отстраненного примера.
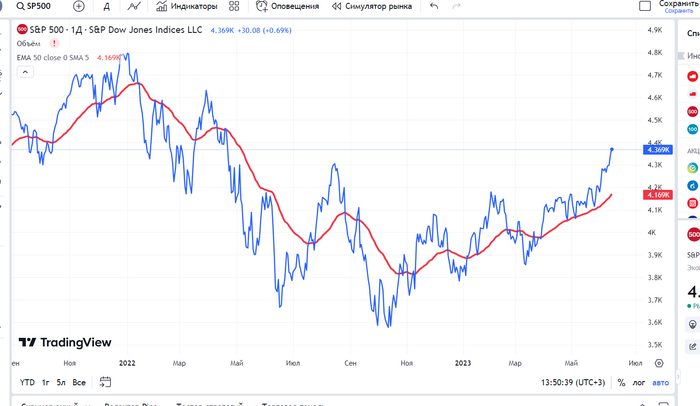
Если вы когда-нибудь смотрели на биржевые графики, то видели, что там идет подробная линия цены, которая реагирует на мельчайшие изменения на рынке. Но чтобы чуть лучше понимать что происходит, возможно нет смысла смотреть каждое движение цены? Может, чтобы уловить общую тенденцию нам лучше подойдет какое-то среднее значение? Именно для этого и применяется экспоненциальная скользящая средняя (ema, exponential movement average) - на графике она красная.
Примерно тоже самое и у нас. У моделей stable diffusion при тренировке сохраняли две пачки весов: non-ema и ema.
no-EMA - это обычная модель, как тренируется, так и тренируется, примерно также как обычный график цены. Иногда это может сказаться не совсем хорошо, потому что мы учили модель долго, упорно и вначале-середине все было ок, а под конец ее повело немного не туда и она так и сохранилась.
EMA-only применительно к модели, означает что веса в модели более "гладкие" и во время тренировки модель обращала внимание не только на текущий шаг, но брала во внимание и несколько предыдущих. Аналогично тому, как и ema на графике
Соответственно модель в которой у нас обе пачки весов называется full, full-ema или никак не обозначается, модель в которой одна из пачек: no-ema и emaonly обычно так и называются.
Большинство авторов либо сами вырезают лишнее или выбор достается автоматику. Если в модели есть обе пачки, то автоматик всегда выбирает no-ema, если есть только ema - тогда ema.
Но, если все так интересно, какая нужна нам? Зависит от модели, но как правило можно принять так: для тренированных оставляем ema/no-ema (тестируем какая будет лучше), для миксов оставляем no-ema.
С миксами зачастую ema-only генерят только шум или результат значительно хуже
Pruned
Тут только пара слов. У нас есть модель. Суть в том что на входе она получает что-то одно и выдает что-то другое на выходе. Соответственно внутри происходят некоторые преобразования. Часть этих преобразований может быть почти незаметной, можно сказать незначительной, например если мы умножим 5 на 1.0000001 то у нас получиться 5.0000005. Если нас интересует только первые три знака после запятой, то есть 5.000, то подобные изменения для нас некритичны. Мы можем пропустить подобные операции, а операций таких может быть много, а может и не быть совсем. Процесс, когда мы избавляемся от незначительных кусочков в модели, называется pruning, а модель которая прошла через этот процесс pruned.
Как мне кажется, в сообществе есть некоторая путаница: pruned - значит уменьшенная, соответственно как бы образом мы не уменьшали модель она теперь pruned. Это не совсем так.
Это достаточно сложный процесс, который нужно знать как делать, поэтому, если вы видите, что у модели приписка pruned, то скорее всего имеется в виду либо то что она fp16, либо что она только ema/non-ema, либо и то и другое вместе.
No vae/baked vae
Откроем например страничку Dreamshaper'а и увидим еще один параметр
VAE - это часть модели, а как мы знаем из первой статьи, без модели ничего работать не будет. И если выкинуть ее часть - тоже.
Когда у модели указано "no vae" - значит в модель зашита та VAE, которая шла по умолчанию. Если написано baked значит зашили какую-то нестандартную.
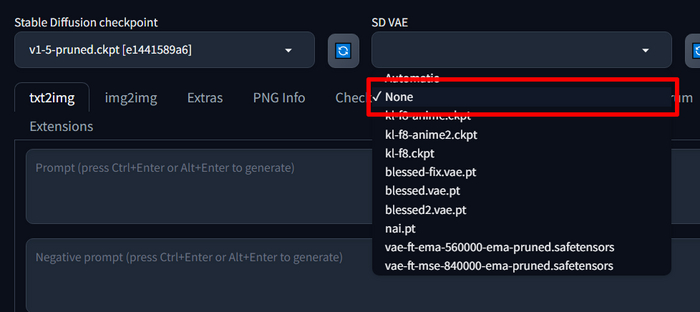
Это просто не совсем корректное название, которое прижилось и путает, поэтому когда вы выбираете "none" в автоматике в поле для выбора VAE - вы указываете, чтобы использовалась та VAE, которая вшита в модель, а не чтобы не использовалась никакая.
Если вы при генерации выбираете VAE, в таком случае вам все равно какую VAE запихнули в модель.
Нестандартные модели
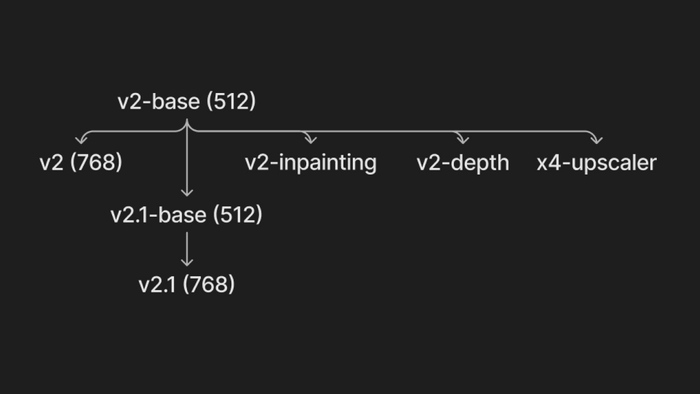
У моделей есть определенная структура. Примерно как разные версии одной и той же программы могу конфликтовать между собой, также и модели с разными архитектурами нужно использовать немного по разному. Структура моделей stable diffusion первой версии, и например контролнета 1.0 считаются основными и поэтому автоматик со всеми моделями работает как-будто они модели sd 1.x или controlnet 1.0. Именно поэтому для моделей версий sd 2.x или controlnet 1.1 нам нужен дополнительный файлик, который и подскажет автоматику, что с этой моделью нужно работать немного иначе. Это будет файл с расширением yaml. Это конфигурационный файл, в котором храниться вся нужная информация о модели. Обычно, скачать их можно там же где и сам файл модели.
Итого
Формат: ckpt или safetensors?
Предпочтительнее safetensors - она безопаснее и быстрее загружается. Нет safetensors версии? Ну и пускай, можно брать ckpt.
Точность чисел: fp16 или fp32?
Для генерации картинок лучше 16, для тренировки лучше 32. Нет 32? Ну и ладно, берем 16
Пачка весов: ema или non-ema?
Для миксов - non-ema, для тренированных нужно протестировать какая лучше.
Комплектная VAE: no vae или baked?
no vae - будет дефолтная, baked - та, которую автор зашил в модель. Если вы все равно выбираете какую-то другую, то без разницы.
Для нестандартных моделей, например модели sd 2.0 нужен файл настроек с расширением yaml, который должен называться также как и файл модели и лежать рядом с моделью.
По умолчанию, автоматик считает все в fp16 и использует no-ema веса
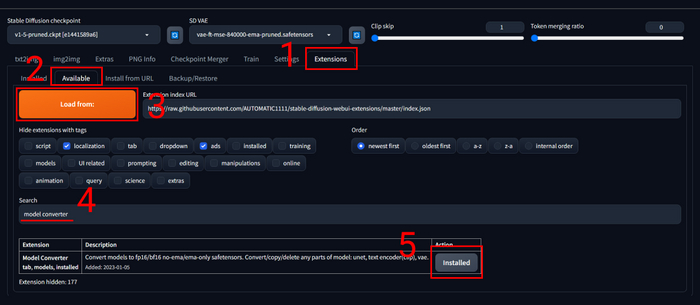
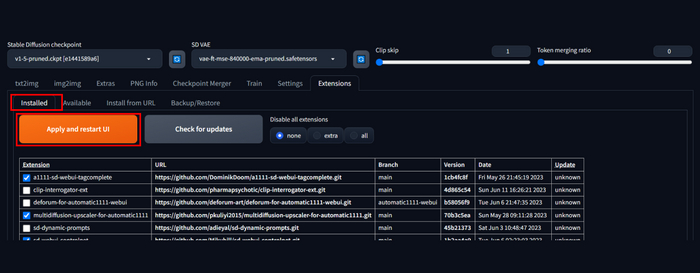
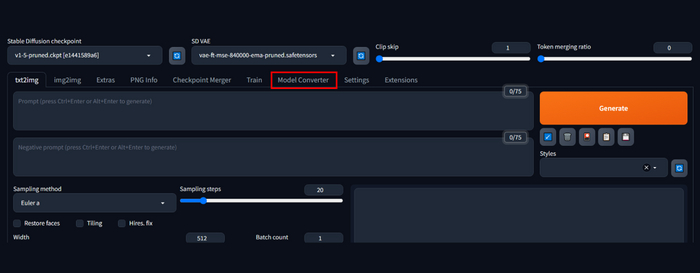
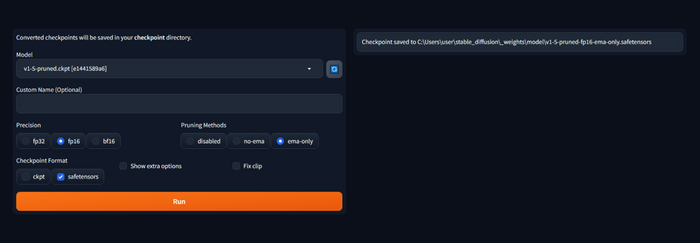
В следующей, заключительной части, сделаю небольшой обзор на расширение-конвертер, с которым очень просто можно получить ту модель которую нужно.
Нейронки интересная и непростая штука, поэтому если хотите лучше в них разобраться, подписывайтесь на канал, там рассказываю как работать с stable diffusion