
Разрабатываю игру при помощи ИИ
1 пост
Что исследования говорят о стратегиях, головоломках, шутерах и MOBA

Фото: Chí Thanh Do / Pexels.
Начнём со списка для тех, кто уже открыл Steam и не собирается читать ещё двадцать абзацев.
Для стратегии и быстрой смены планов: Age of Empires II, Age of Empires IV, StarCraft II.
Для логики и пространственного мышления: Portal 2, Baba Is You, The Witness, The Talos Principle.
Для системного мышления: Factorio, Oxygen Not Included, Satisfactory.
Для внимания и скорости обработки информации: Doom Eternal, Titanfall 2, Quake, Apex Legends.
Для работы с большим объёмом информации: Dota 2, League of Legends.
Если оставить три игры, я бы выбрал Age of Empires II, Portal 2 и Titanfall 2. Получится стратегия, головоломка и быстрый экшен. Разные игры, разная нагрузка.
Теперь плохая новость. Игры не выдают по пять пунктов IQ за каждое прохождение. Хорошая новость тоже есть: некоторые навыки они действительно тренируют. Просто слово «умнее» придётся разобрать на части.
Что нашли учёные
Компьютерные игры изучают давно. Исследователи сравнивают опытных игроков с новичками, дают людям несколько недель играть в определённый жанр, а потом проверяют внимание, память, скорость реакции и пространственное мышление.
Картина получается довольно земная. Игроки часто лучше справляются с задачами, похожими на то, что происходит у них на экране. Любители быстрых экшенов быстрее замечают объекты на периферии. Опытные стратеги лучше переключаются между несколькими источниками информации. Головоломки могут подтянуть пространственное мышление и поиск решений.
С общим интеллектом всё скромнее. В крупном метаанализе 2018 года авторы не нашли убедительных доказательств, что игровые тренировки улучшают широкие когнитивные способности [1]. Более свежий метаанализ 63 исследований получил небольшой средний эффект, но показал, что привычные ярлыки вроде «экшен» или «стратегия» плохо предсказывают результат [2]. Важнее оказались конкретные действия, которых требует игра.
Поэтому честный вывод звучит осторожно. После ста часов в StarCraft вы можете быстрее менять план и лучше следить за несколькими задачами. Формулы высшей математики сами в голове не появятся.
Психологи называют это переносом навыков. Ближний перенос выглядит правдоподобно: человек много искал цели среди визуального шума в игре и стал лучше выполнять похожий тест. Дальний перенос уже вызывает вопросы. Из улучшенного микроконтроля не следует умение вести бизнес, учить языки или принимать разумные решения в личной жизни.
Мозг довольно прижимист. Он охотно совершенствует то, чем вы его регулярно мучаете, и редко раздаёт бонусы всем способностям сразу.
Причина и следствие постоянно путаются
Представим сильного игрока в League of Legends. У него высокий рейтинг, хорошая рабочая память и высокий результат в тесте на подвижный интеллект. Очень хочется решить, что всё это подарила ему игра.
Но могло быть наоборот. Человек изначально быстро замечал закономерности, хорошо держал в голове много деталей и поэтому быстрее освоил LoL. Возможен и смешанный вариант: способности помогли ему войти в игру, а годы практики немного усилили отдельные навыки.
Поэтому простое сравнение геймеров с негеймерами мало что доказывает. В таких работах трудно отделить эффект игры от возраста, образования, образа жизни и первоначальных способностей.
Надёжнее эксперименты, где участников случайно делят на группы. Одни играют, другие получают иное занятие, а исследователи сравнивают изменения до и после. Такие работы иногда находят эффект, но обычно небольшой и довольно узкий. Результаты зависят от качества контрольной группы, выбранных тестов и того, учитывали ли авторы публикационное смещение. Это хорошо видно по разбору исследований экшен-игр 2019 года: после поправок свидетельства широкого переноса стали гораздо слабее [3].
Для заголовка «Dota делает гением» этого маловато. Для вывода «сложные игры способны тренировать отдельные функции» вполне хватает.
Стратегии: когда мир рушится каждые две минуты
Age of Empires II и StarCraft II хорошо показывают, за что ценят стратегии в реальном времени.
Допустим, вы решили спокойно развить экономику. Поставили второй городской центр, заказали улучшения, мысленно уже пересчитываете будущие золотые горы. Тут разведчик замечает вражескую казарму у вашей базы. План отправляется в мусор. Нужно отменять дорогие технологии, срочно строить защиту и угадывать, настоящий это удар или попытка напугать вас.
Через минуту ситуация снова меняется. Противник перешёл в копейщиков, а вы собирались делать конницу. На другом краю карты закончился лес. Рабочие стоят без дела. Где-то погиб забытый отряд, который стоил половину вашей экономики.
Всё это заставляет постоянно переключать внимание, пересматривать решения и действовать при нехватке информации. В эксперименте со StarCraft участники около сорока часов играли в специально изменённые версии стратегии [4]. У групп с более сложным управлением сильнее улучшилась когнитивная гибкость. Так называют способность быстро менять задачу и перестраивать план, когда старый уже не работает.
Это интересный результат, но не сертификат на повышение IQ. Исследование касалось конкретных когнитивных функций. Оно не доказывает, что любой человек станет умнее от любой стратегии.
Пошаговые игры вроде Civilization тоже требуют планирования. Разница в давлении времени. В Civilization можно десять минут разглядывать карту и ещё пять читать описание технологии. В StarCraft эти пятнадцать минут обычно заканчиваются дымящейся базой.
Есть ещё одна оговорка. Заученный порядок действий со временем превращается в рутину. Если человек годами повторяет один билд на одной карте, мозг всё реже сталкивается с новой задачей. Польза выше, когда приходится менять цивилизации, играть против более сильных соперников, разбирать повторы и пробовать решения, которые пока не получаются.
Головоломки: меньше угадывания, больше моделей
Хорошая головоломка заставляет сначала понять, как устроен мир, а потом использовать его правила в новой ситуации.
Portal 2 работает именно так. Игрок держит в голове геометрию комнаты, скорость движения, положение порталов и последовательность действий. Иногда решение видно сразу. Иногда двадцать минут смотришь на стену, потом замечаешь маленькую белую панель под потолком и чувствуешь себя одновременно гением и человеком, который двадцать минут не видел белую панель.
В небольшом эксперименте с Portal 2 и Lumosity 77 студентов восемь часов играли в одну из двух программ [5]. У группы Portal 2 лучше изменились результаты некоторых тестов на пространственные навыки и решение задач. Выборка маленькая, обучение короткое, поэтому делать из этой работы громкий вывод не стоит. Но она хорошо показывает, почему полноценная игра бывает интереснее однообразного «тренажёра мозга».
Baba Is You нагружает голову иначе. Здесь можно двигать слова, из которых собраны правила уровня. Стена перестаёт быть стеной. Камень становится управляемым персонажем. Условие поражения превращается в путь к победе. Игра приучает проверять саму постановку задачи, а не долбиться в первое очевидное решение.
The Witness, The Talos Principle, Opus Magnum и SpaceChem тоже требуют строить мысленную модель, выдвигать гипотезы и отбрасывать их, когда факты не сходятся. Полезен именно момент, когда привычный подход ломается и приходится искать другой.
Специальные приложения для памяти часто дают более узкий результат. Человек быстро учится нажимать на нужные квадратики и запоминать знакомые последовательности. Результат внутри приложения растёт. В обычной жизни перемены могут остаться незаметными.
Шутеры: мозг тоже участвует
Шутеры легко принять за чистую проверку реакции. На деле хороший быстрый экшен заваливает игрока визуальной информацией.
В Doom Eternal нужно замечать врагов на разных уровнях арены, следить за патронами, выбирать оружие, помнить о восстановлении способностей и не останавливаться. Промедление быстро превращает героя в красивый набор спецэффектов.
Titanfall 2 и Quake добавляют сложное движение. В Apex Legends приходится учитывать ещё и позицию команды, границы зоны, возможные маршруты противника. Даже обычная перестрелка требует быстро отделять полезный сигнал от шума.
По динамичным экшенам накопилось много исследований. Метаанализ 2023 года объединил сравнительные и экспериментальные работы и получил небольшой эффект игрового обучения, около g = 0,30 [6]. Лучше всего выглядели задачи на восприятие, внимание и пространственную обработку. Опытные игроки обычно показывают более заметное преимущество, но здесь снова вмешивается отбор: люди с хорошей реакцией чаще задерживаются в жанре и играют лучше.
Шутер может научить быстрее замечать угрозу на экране. Он слабее подходит для долгого планирования или спокойного анализа текста. Это нормальное ограничение. Молоток тоже плохо закручивает винты, хотя в своём деле полезен.
Dota и LoL: огромная база знаний на высокой скорости
MOBA смешивают стратегию, экшен и командную игру. Уже через несколько минут матча игрок отслеживает линии, предметы, способности, время их восстановления, положение соперников и цели на карте. Часть информации видна. Остальное приходится достраивать.
Противник исчез с линии. Он мог уйти на базу, спрятаться рядом или уже бежать убивать вашего союзника. Ответа нет, а решение нужно принять сейчас.
В исследовании 2017 года игровой ранг в League of Legends положительно коррелировал с подвижным интеллектом [7]. Для Dota 2 и LoL авторы также увидели возрастную кривую результатов, похожую на кривую некоторых когнитивных способностей. У игроков в Battlefield 3 и Destiny такой картины не нашли.
Корреляция показывает связь, а направление этой связи остаётся неясным. Высокий подвижный интеллект может помогать в MOBA. Сама игра тоже способна тренировать часть нужных навыков. Работа не доказывает, что установка League of Legends повышает IQ.
Зато требования жанра видны без лаборатории. Нужно быстро обрабатывать много информации, предсказывать чужие действия и менять план вместе с командой. Иногда приходится тренировать ещё один полезный навык: вовремя выключать чат.
Factorio и другие игры про системы
Factorio выглядит как кандидат на звание лучшей игры для инженерного мышления. Начинается всё с пары печей и конвейера. Через несколько десятков часов поезда возят руду между районами, роботы таскают детали, электростанция работает на пределе, а нехватка одной шестерёнки останавливает половину завода.
Игрок ищет узкие места, считает потоки ресурсов и перестраивает производство. Любое удачное расширение рождает следующую проблему. Удвоили выпуск деталей, теперь не хватает меди. Добавили плавильни, просела электросеть. Построили новую ветку железной дороги, поезда устроили пробку.
Oxygen Not Included добавляет температуру, давление газов, воду и колонистов, которые умеют выбрать худшее место для паники. Satisfactory переносит производственные цепочки в трёхмерный мир. Kerbal Space Program заставляет хотя бы на интуитивном уровне разобраться с орбитами и тягой.
Такие игры явно требуют системного мышления. Однако прямых экспериментов по Factorio или Oxygen Not Included мало. Нельзя честно написать, что они доказанно повышают интеллект. Здесь рекомендация основана на характере задач, а не на уверенном результате серии исследований.
И всё же разница между проектированием фабрики и механическим повторением одного действия понятна. В первом случае игрок строит модель системы, ищет ошибку и проверяет новое решение. Это хорошая умственная работа, даже если учёные пока не превратили её в обещание прибавки к IQ.
Как играть с большей пользой
Название игры решает далеко не всё. Один человек за час в Age of Empires разберёт проигранный матч и попробует новый подход. Другой проведёт тот же час на автопилоте, в сотый раз повторяя знакомый билд. Формально оба играли в стратегию. Нагрузка была разной.
Игра должна оставаться чуть сложнее вашего текущего уровня. Слишком лёгкая быстро превращается в фон. Слишком трудная даёт хаос, в котором непонятно, чему учиться. Хороший уровень заставляет ошибаться, но позволяет увидеть причину ошибки.
Помогает короткий разбор после игры. Полезно найти момент, где развалился план, вспомнить пропущенную информацию и заметить решение, принятое по привычке. Пара минут честного анализа часто полезнее ещё одного матча, запущенного на раздражении.
Разнообразие тоже работает. Можно менять карты и персонажей, осваивать новый жанр, повышать сложность или играть с соперниками немного сильнее. Когда всё стало автоматическим, пора создать себе новую проблему.
И да, десять часов подряд не превращают тренировку в сверхтренировку. Усталый человек хуже замечает ошибки и хуже запоминает новое. Недосып, отсутствие движения и постоянный стресс легко съедят возможную пользу от игр. Четыре часа сна плюс восемь часов Dota остаются плохой программой развития мозга, сколько бы рейтинга вы ни набрали.
Что в итоге
Компьютерные игры могут немного улучшить отдельные навыки. RTS нагружают планирование и когнитивную гибкость. Быстрые шутеры тренируют зрительное внимание. Головоломки заставляют строить пространственные модели и пересматривать условия задачи. Factorio хорошо нагружает системное мышление, хотя прямых научных данных по ней мало. MOBA требуют держать в голове много меняющейся информации.
Обещать рост общего IQ было бы нечестно. Эффекты обычно небольшие, а лучше всего переносятся на похожие задачи. Поэтому разумнее выбирать игру под навык, который хочется нагрузить, и периодически менять тип нагрузки.
Мой набор выглядел бы так: Age of Empires II для решений под давлением, Portal 2 или Baba Is You для головоломок, Titanfall 2 для внимания и скорости. Factorio можно оставить на случай, если обычной жизни вам мало и хочется ещё одной системы, где всё ломается из-за нехватки меди.
Игры не заменят сон, чтение, физическую активность и обучение. Зато могут стать хорошей частью этой смеси. Так что вечер в Portal или Age of Empires не обязательно прошёл зря. Только три тысячи часов в Dota по-прежнему не равны степени MBA.
Исследования
Sala G., Tatlidil K. S., Gobet F. Video game training does not enhance cognitive ability: a comprehensive meta-analytic investigation. Psychological Bulletin, 2018.
https://pubmed.ncbi.nlm.nih.gov/29239631/
Smith E. T., Basak C. A game-factors approach to cognitive benefits from video-game training: a meta-analysis. PLOS ONE, 2023.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0285925
Hilgard J. et al. Overestimation of action-game training effects: publication bias and salami slicing. Collabra: Psychology, 2019.
https://online.ucpress.edu/collabra/article/5/1/30/113031/Overestimation-of-Action-Game-Training-Effects
Glass B. D., Maddox W. T., Love B. C. Real-time strategy game training: emergence of a cognitive flexibility trait. PLOS ONE, 2013.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0070350
Shute V. J., Ventura M., Ke F. The power of play: the effects of Portal 2 and Lumosity on cognitive and noncognitive skills. Computers & Education, 2015.
https://doi.org/10.1016/j.compedu.2014.08.013
Bediou B. et al. Effects of action video game play on cognitive skills: a meta-analysis. Technology, Mind, and Behavior, 2023.
https://doi.org/10.1037/tmb0000102
Kokkinakis A. V. et al. Exploring the relationship between video game expertise and fluid intelligence. PLOS ONE, 2017.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0186621
Правительство США, ссылаясь на органы национальной безопасности, издало директиву по экспортному контролю, запрещающую доступ к Fable 5 и Mythos 5 для всех иностранных граждан, как внутри, так и за пределами Соединенных Штатов, включая иностранных сотрудников Anthropic. В результате этого распоряжения мы вынуждены внезапно отключить доступ к Fable 5 и Mythos 5 для всех наших клиентов, чтобы обеспечить соблюдение требований. Доступ ко всем остальным моделям Anthropic останется без изменений.

https://www.anthropic.com/news/fable-mythos-access оригинал статьи
Anthropic выпустила исследование, которое странно читать. Не потому что там страшные прогнозы — там вообще нет почти никаких прогнозов. Там данные. И вот данные как раз неприятно конкретны.
Больше 80% кода, который сейчас идёт в продакшн Anthropic, написал Клод. Год назад — единицы процентов. Инженеры при этом никуда не делись: ставят задачи, делают ревью. Но код набирают не они. Итог — один инженер коммитит в 8 раз больше кода в квартал, чем в 2021–2024. Не потому что стал работать больше.
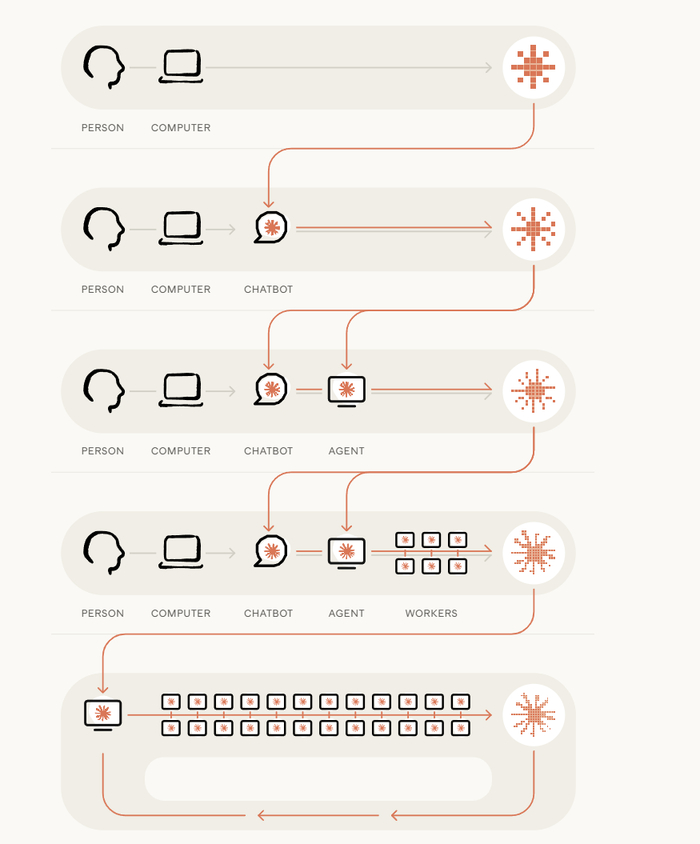
В марте 2024 года Claude Opus 3 справлялся с задачами на ~4 минуты человеческого времени. Год спустя — полтора часа. Ещё год — 12 часов. Горизонт удваивается каждые четыре месяца. Честно: я не знаю, как правильно на это реагировать.
Один кейс из статьи, который у меня застрял. В апреле 2026-го Клод самостоятельно пофиксил 800+ ошибок одного класса API-проблем и снизил их число в тысячу раз. Инженер, который курировал это, прикинул: человек потратил бы четыре года. Людям физически тяжело держать в голове столько чужого незнакомого кода. Один из разработчиков написал во внутреннем чате: «Уже пять месяцев как я сам не написал ни строчки».
Есть ещё один момент, который кажется мне важным. Anthropic прогоняет один и тот же тест с каждым релизом: даёт Клоду код тренировки маленькой модели, просит разогнать его насколько возможно. В мае 2025-го Opus 4 ускорял в ~3 раза. К апрелю 2026-го Mythos Preview — в 52. Для сравнения: опытный исследователь-человек за 4–8 часов выжимает 4x. Это не помощник для кода. Это что-то другое.
Пока человек держится на выборе задач и постановке направления. В реальных сессиях, где нужно решить, какой шаг делать следующим, в ноябре 2025-го Клод предлагал лучший вариант в 51% случаев, в апреле 2026-го — уже в 64%. Можно спорить, много это или мало. Но направление очевидно.
Что будет дальше — Anthropic описывает три сценария: рост тормозит и текущие модели просто расходятся по экономике; рост продолжается, но люди остаются на позиции «выбора направлений» и каждый управляет пирамидой агентов; или ИИ замыкает петлю и строит преемников уже сам. В последнем случае скорость определяется только вычислительными мощностями, и это единственный сценарий, про который компания честно пишет «мы не знаем, как это будет выглядеть».
Компания хотела бы притормозить — но не в одностороннем порядке, это просто поменяет лидера гонки. Нужна система глобальной верификации. Её пока не существует.

Метапромптинг: как заставить ИИ самому написать промпт для исследования
Метод Франкенштейна: прогон через три нейросети (Claude, ChatGPT, Gemini) и синтез лучшего
Telegram-хак: экспорт профессиональных чатов → NotebookLM → инсайты, которые нейросети не найдут в открытых источниках
Финальная сборка: все данные в одном месте → структура и выводы
Реальный кейс: исследование ЦА для курса по маркетингу медклиник. С промптами, скриншотами и ссылками на инструменты.
Целевая аудитория — это фундамент маркетинга. Без неё не понятно, кому продаёшь, какие боли закрывать и какие аргументы использовать. Классический подход: недели на интервью, опросники, фокус-группы. Я покажу, как сделать это за пару часов с помощью нейросетей — и получить результат местами даже глубже, чем после живых кастдевов.
Разберу на реальной задаче: мне нужно было исследовать ЦА для курса по маркетингу медицинских клиник.
Есть приём проще написания промптов вручную — попросить ИИ написать промпт за вас. Называется метапромптинг.
Написал в Claude примерно следующее:
Я хочу делать курс по маркетингу для владельцев и руководителей медицинских клиник. Цель курса — продать своё агентство как экспертов. Курс должен быть реально полезным, а не просто завлекающим. Распространять бесплатно в боте и через статьи. Плюс трафик налью с рекламы. Сейчас хочу собрать портрет целевой аудитории, найти боли. Планирую через Deep Research. Как тебе идея?
Обратите внимание на финальный вопрос «Как тебе идея?» — это чтобы нейросеть не просто согласилась, а покритиковала, если идея содержит ошибки.
Он написал, что идея рабочая, но рекомендовал верифицировать через живые интервью (5-7 созвонов). Задал уточняющие вопросы: какие сегменты клиник интересны, какой размер. После моих ответов сгенерировал промпт.
Промпт получился структурированный:
Портрет ЛПР по каждому из 4 сегментов
Реальные боли через Jobs-to-be-Done
Триггеры к действию
Сводная таблица
ИИ сам предупредил об ограничении: «Промпт не покроет личные инсайты, которые люди не пишут публично. Например: 'Я вообще не понимаю, за что плачу агентству, но боюсь спросить'». Но у меня был лайфхак для извлечения этих непубличных данных — об этом дальше.
Привожу промпт полностью — можете копировать и адаптировать под свою задачу:
Проведи глубокое исследование целевой аудитории для бесплатного образовательного курса по интернет-маркетингу, предназначенного для владельцев и руководителей частных медицинских клиник в России.
Контекст
Маркетинговое агентство, специализирующееся на медицинском маркетинге, создаёт бесплатный курс. Цель — дать реально полезные знания по интернет-маркетингу клиник и одновременно продемонстрировать экспертизу агентства. Курс распространяется через Telegram-бот, VK-бот, статьи на Дзене и видео на YouTube.
Сегменты клиник, которые нас интересуют
Стоматологии — от средних клиник (5–15 врачей) до сетевых
Косметология и эстетическая медицина — клиники с лицензией, не салоны красоты
Многопрофильные клиники — средние и крупные (терапия, хирургия, диагностика и т.д.)
Узкоспециализированные клиники — офтальмология, ортопедия, репродуктология, ЛОР-центры и т.д.
Размер: средние (5–15 врачей) и крупные сети (15+ врачей, филиалы).
География: вся Россия без разделения.
Что нужно исследовать
БЛОК 1. Портреты ЦА (для каждого сегмента отдельно)
Для каждого из 4 сегментов клиник определи и опиши типовые портреты лиц, принимающих решения (ЛПР):
Кто реально принимает решение о маркетинге: владелец-врач, наёмный управляющий, коммерческий директор, маркетолог в штате?
Их типичный возраст, образование, управленческий опыт
Уровень маркетинговой грамотности (понимают ли unit-экономику, LTV, CPL, или мыслят категориями «нам нужно больше пациентов»?)
Где они потребляют контент: Telegram-каналы, профильные форумы, конференции, YouTube, Дзен, VC.ru, профессиональные сообщества
Какие конференции и мероприятия посещают
Кого считают авторитетами в вопросах управления клиникой и маркетинга
БЛОК 2. Боли и проблемы (найди реальные формулировки)
Ищи информацию в:
Профильных Telegram-каналах и чатах для владельцев клиник
Форумах (dentalforum, doctor-forum, сообщества на Facebook/VK для управленцев клиник)
Отзывах о маркетинговых агентствах и фрилансерах на медицинскую тематику
Статьях и комментариях на VC.ru, Habr, Дзен о маркетинге клиник
Дискуссиях на профильных конференциях (MedBusinessForum, «Частная медицина», ПИР, Dental Salon и т.д.)
Вакансиях маркетологов в клиниках (hh.ru) — по требованиям можно понять, чего им не хватает
Конкретные боли, которые нужно выявить:
Боли в привлечении пациентов: что не работает, на что жалуются, какие каналы разочаровали
Боли с подрядчиками: почему недовольны агентствами, фрилансерами, штатными маркетологами
Боли с бюджетом: как принимают решение о бюджете на маркетинг, что считают дорогим/дешёвым, какой CPL считают нормальным
Боли с аналитикой и контролем: понимают ли, откуда пришёл пациент, используют ли CRM, сквозную аналитику
Боли с контентом и репутацией: отзывы, контент для соцсетей, сайт, работа с агрегаторами (ПроДокторов, НаПоправку и т.д.)
Боли с регуляторикой: ограничения рекламы медицинских услуг (ФЗ-38, маркировка рекламы), страхи штрафов
Боли с конкуренцией: демпинг, агрегаторы, сетевые клиники
БЛОК 3. Возражения и барьеры
Почему владелец/руководитель клиники может НЕ захотеть проходить курс:
«У меня нет времени» — насколько это реальный барьер?
«Я уже всё знаю / у меня есть маркетолог» — насколько распространена иллюзия контроля?
«Бесплатное = бесполезное» — есть ли скепсис к бесплатному контенту?
«Это просто продажа услуг агентства» — как нейтрализовать?
Какие ещё барьеры существуют?
БЛОК 4. Jobs to Be Done (JTBD)
Определи ключевые «работы», которые владельцы/руководители клиник «нанимают» маркетинг выполнять:
Функциональные (загрузить расписание врачей, заполнить новый филиал, вывести новую услугу)
Эмоциональные (чувствовать контроль, не зависеть от «одного Яндекса», не бояться проверок)
Социальные (быть не хуже конкурентов, показать современность клиники)
БЛОК 5. Триггеры к действию
Что заставляет владельца клиники ПРЯМО СЕЙЧАС начать искать информацию о маркетинге:
Сезонные спады
Уход ключевого врача (и «его» пациентов)
Открытие конкурента рядом
Провал с текущим подрядчиком
Запуск нового направления/филиала
Что ещё?
Формат ответа
Для каждого блока:
Дай структурированный ответ с разбивкой по сегментам клиник, где это важно
Приводи реальные цитаты и формулировки ЦА (со ссылками на источники, если возможно)
Отмечай, где данные точные (из исследований), а где — гипотезы, требующие проверки
В конце каждого блока — 3–5 инсайтов, которые могут повлиять на структуру курса
В самом конце дай:
Сводную таблицу «Сегмент → Главные боли → Что курс должен закрыть»
Рекомендации по приоритетам: какой сегмент самый «горячий» и почему
Список источников, которые использовал
Дальше использую метод из прошлых уроков: один промпт → три нейросети → синтез лучшего из каждой.
Claude выдал всё, что просили: портреты по сегментам, боли, таблицы, сводку.
Интересные находки:
Врачи вынуждены становиться предпринимателями: в 70–80% случаев маркетинговые решения принимает собственник лично;
У них низкая маркетинговая грамотность;
Негативный опыт с подрядчиками;
Лиды сливаются администраторами.
Портрет типичного ЛПР для стоматологии: врач-собственник 35–55 лет, совмещает приём и управление, работает по 12 часов, MBA нет, мыслит категориями «нам нужно больше пациентов», не считает CPL и LTV, понимает «дорого или дёшево» интуитивно.
Из моего опыта работы со стоматологиями — попадание процентов на 90.
Единственный минус: данные местами не самые свежие. Где-то ссылки на источники 2024 года. Но для системных проблем это не критично — боли те же самые.

Результат от Claude
ChatGPT думал 40 минут — дольше всех. Зато выдал подробное исследование.
Те же инсайты, что и у Claude, но другими словами. А это хорошо: если две нейросети выдали одно и то же — скорее всего, не галлюцинация, а реальный факт из интернета.
Конкретная цитата из результатов: «Стал искать компанию, которая займётся раскруткой, Директом. Ценник высокий, гарантии не дают.» Это не нейросеть придумала — нашла где-то на форуме или в обсуждении.
Результат от ChatGPT
Gemini — многословен, как обычно. Инфу собирает качественно (особенно по источникам), но отчёт читать тяжело. Ощущение, что читаешь диссертацию.
Рынок частной медицины России: 1,6-2,0 трлн руб./год, рост 15-18% ежегодно
26 000+ стоматологий в России
Незанятая ниша: комплексный маркетинг для клиник с бюджетом 80-170 тыс. руб./мес. (крупные агентства не работают с такими клиентами, фрилансеры не дают системного подхода)
Плюс Gemini дал таблицу со сравнением сегментов по возрасту ЛПР, бюджетам, циклу принятия решений.
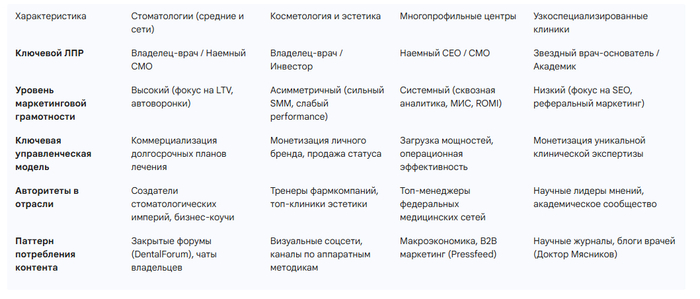
Результат от Gemini с таблицами
Никто. В этом и суть метода Франкенштейна — берёшь лучшее от каждого:
Claude — структура и портреты;
ChatGPT — глубина и цитаты;
Gemini — цифры и источники.
Все нейросети берут информацию из открытых источников: статьи, отчёты, форумы. Но самые ценные инсайты люди пишут в закрытых Telegram-чатах. Там нет фильтра «а что обо мне подумают». Там пишут как есть: «Слил 300к на подрядчика, заявок ноль», «Администратор сливает лиды, а я не могу это доказать».
Вот как это вытащить.
В десктопной версии Telegram:
Открываем нужный чат (ищи профильные чаты по твоей нише);
Нажимаем «Экспортировать историю чата»;
Убираем фотографии (они не нужны);
Выбираем формат JSON;
Жмём «Экспортировать».
Я экспортировал несколько чатов: «Медплатформа», «Школа медицинского маркетинга», чат стоматологов. Сотни тысяч сообщений.
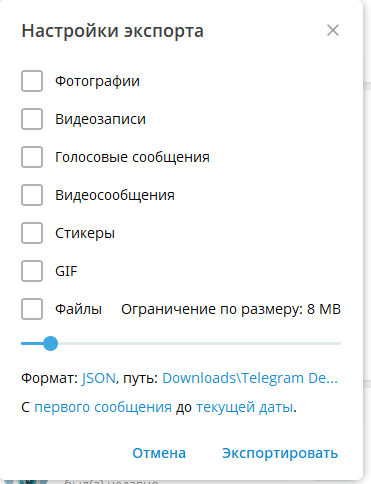
Экспорт чата из Telegram
JSON-файл напрямую в нейросеть не загрузить — слишком большой и не в том формате.
Для этого я сделал конвертер: forstartup.ru/telegram-notebooklm
Что он делает:
• Берёт JSON-файл из Telegram
• Разбивает на части (по 100 000 слов в файле)
• Переводит в Markdown-формат, который понимает любая нейросеть
На выходе — zip-архив с файлами. Распаковываешь и загружаешь в NotebookLM.
Можете воспользоваться им тут: https://forstartup.ru/telegram-notebooklm
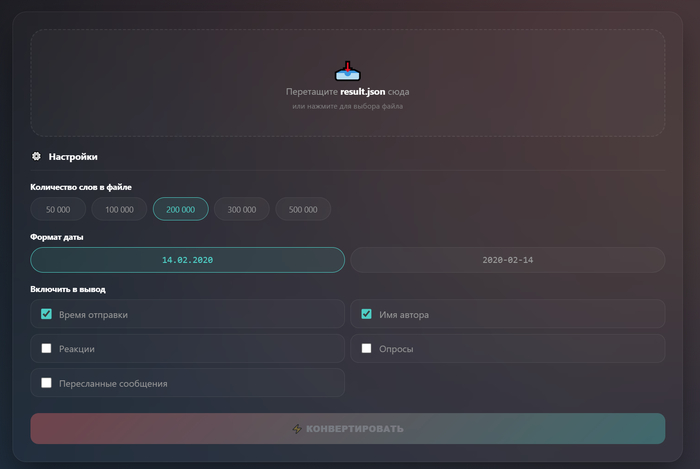
Интерфейс конвертера
NotebookLM — это нейросеть от Google, которая работает только с загруженными файлами. Она не выдумывает из головы, а анализирует конкретно то, что вы ей дали. Индексирует содержимое и отвечает на вопросы строго по нему.
Загружаем Markdown-файлы (из нескольких чатов) и начинаем спрашивать:
С какими проблемами в интернет-маркетинге чаще всего сталкиваются владельцы медклиник?
И вот тут начинается магия.
NotebookLM выдаёт сводку по реальным сообщениям реальных людей:
Ожидание волшебной таблетки;
Маркетинг без продукта (хотят лиды, но не работают над сервисом);
Кладбища подрядчиков — устойчивый термин в сообществе;
Приписки в отчётах;
Считают клики, а не фактические лиды;
Перекладывание ответственности.
И он показывает конкретные сообщения, из которых это вытащил. Можно кликнуть и увидеть, кто написал, что написал, в каком контексте.
Это те самые «непубличные инсайты», о которых нейросеть нас предупреждала на первом шаге. Только мы их нашли.

NotebookLM — результат анализа чатов с источниками
• Таблицы. Я сделал отчёт «Обсуждение продаж, маркетинга, сервиса» — кто написал, тезис, аргументы, инструменты. Большая таблица, которую потом экспортировал в Excel.
• Карты персонажей. Попросил составить архетипы владельцев медклиник — и он выделил типы: «Врач-творец», «Искатель волшебных таблеток», «Отстранённый инвестор», «Технократ-инноватор».
• Презентации. NotebookLM генерирует презентации, которые можно скачать в PowerPoint.
Это как если бы вы лично прочитали 100 000 сообщений и выписали главное. Только за 5 минут.
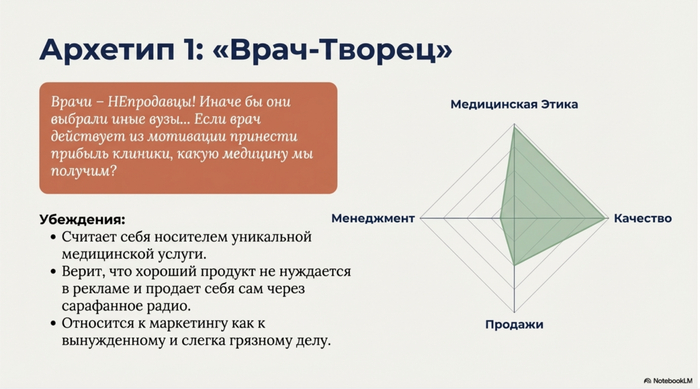
Презентация от NotebookLM
Теперь у нас куча материала:
исследование от Claude;
исследование от ChatGPT;
исследование от Gemini;
таблицы и инсайты из NotebookLM.
Берём всё это и загружаем обратно в Claude (или в ту нейросеть, которой доверяете больше) с промптом:
Вот исследования от трёх нейросетей плюс анализ реальных диалогов из чатов через NotebookLM. Сделай финальный итог по портретам и болям.
Claude прочитал все файлы (391 релевантную реплику из чатов) и выдал финальный синтез.
Главный инсайт, который подтвердили все источники единогласно: самая недооценённая боль — потеря 40-60% оплаченных лидов на этапе обработки администраторами.
То есть, клиники тратят деньги на рекламу, лиды приходят — а администраторы их сливают. И никто этого не замечает, потому что нет системы контроля.
Интересная деталь — Claude скептически отнёсся к некоторым цифрам: «Оба источника ссылаются на агрегаторы подрядчиков, которые заинтересованы завышать эти цифры. Для курса лучше давать диапазон и учить считать свой CPL, чем фиксировать конкретные числа.» Согласен.
Стоматологии. ЛПР — владелец, сам врач в 98% случаев. Маркетинговая грамотность самая высокая среди ниш (понимают LTV, воронку). Ключевая метрика: загрузка кресел, выручка в час. Пустое кресло в Москве — потеря 15-30 000 руб. в час.
Косметология / многопрофиль. Тандем: собственник + управляющий (часто не врач, а экономист-менеджер) + CMO. Отдел маркетинга 5-6 человек в сетях. Самая корпоративная культура.
Владелец в замкнутом круге: стыд за продажи (конфликт миссии врача и целей бизнеса), «кладбище подрядчиков», поиск волшебной таблетки, зависимость от конкретного врача-«звезды».

Финальный синтез от Claude
На момент написания статьи (март 2026) я рекомендую Claude. Он лучший в аналитике и текстах.
Но есть проблема: лимиты. Даже на платной подписке.
Вот что произошло за одну сессию: Deep Research + аналитика по файлам = половина месячных лимитов. Осталось ровно на один ответ. Три таких глобальных запроса — и всё, жди следующий период.
За $200/мес можно больше, но мне пока некомфортно столько отдавать. Приходится экономить и распределять.
Плюс бывают глюки и ошибки — стабильность у Claude хуже, чем у ChatGPT и Gemini. Но эффект лучше.

В 2020 запускал агентство "Эй, Стартапер!" с бюджетом 1500 рублей. Партнёр — бывший сотрудник Яндекса, я — с опытом работы с клиентами.
За два года вышли на стабильный поток клиентов. Только эти пять инструментов.
Как это делали — рассказываю по шагам.
Суть метода
Находите целевую аудиторию в соцсетях и пишете персонализированные сообщения. Не спам. Не шаблоны. Каждое письмо — под конкретного человека.
Как делать
Шаг 1: Определите ЦА.
Например, для B2B-услуг это владельцы бизнеса в конкретной нише. Для локального бизнеса — жители района с определённым интересом.
Шаг 2: Найдите людей.
- VK: поиск по интересам, группам, комментариям под постами конкурентов
- Telegram: профильные каналы и чаты (подробнее в пункте 3)
- LinkedIn: поиск по должностям, компаниям, активность в релевантных постах
Шаг 3: Персонализируйте сообщение.
Плохо: "Здравствуйте! Предлагаем услуги маркетинга. Интересно?"
Хорошо: "Андрей, увидел ваш комментарий в чате про запуск контекста для клиники. Сталкивались с похожей задачей для флебологии — снизили CPL с 3500 руб. до 1200 руб. Могу поделиться подходом, если интересно."
Шаг 4: Считайте метрики.
- Отправлено сообщений
- Открыли диалог
- Ответили
- Перешли в продажу
Реальные цифры
Средняя конверсия из сообщения в ответ — 3-7% для холодного B2B.
Это значит: отправили 100 сообщений → 3-7 человек ответили → 1-2 встречи → 0-1 клиент.
Для консервативного прогноза закладывайте 1% конверсии в сделку. 100 сообщений = 1 клиент.
Временные затраты
- Поиск 20 контактов: 30-40 минут
- Написание 20 персонализированных сообщений: 40-60 минут
- Итого: 1,5-2 часа на 20 лидов
Если делать 20 сообщений в день, через месяц получите 3-6 встреч и 1-3 клиента. При среднем чеке услуги 50 000 руб. это уже 50-150 тысяч выручки.
Риски и ограничения
Риск бана. VK и Telegram банят за массовые рассылки. Решение: не более 20-30 сообщений в день, перерывы между отправками, разные формулировки.
Выгорание. Писать персонализированные сообщения утомительно. Решение: ставьте таймер на 1 час, делайте серию, потом переключайтесь.
Низкий отклик. Если конверсия ниже 2%, проблема в сообщении или ЦА. Тестируйте разные формулировки, меняйте угол входа.
Суть метода
Пишете экспертные статьи на публичных платформах. Органический трафик идёт годами. Один хороший материал может приносить несколько лидов в месяц на протяжении года.
Как делать
Выберите платформу:
- Habr: технические темы, разработка, маркетинг с аналитикой, глубокие кейсы
- VC.ru: бизнес, стартапы, маркетинг, предпринимательство
- Яндекс.Дзен: широкая аудитория, упрощённая подача, больше эмоций
Выберите тему:
Не пишите "10 трендов маркетинга в 2026". Это никому не нужно.
Пишите то, что решает конкретную проблему вашей ЦА:
- "Как снизить стоимость лида в медицинской рекламе"
- "Запуск MVP за 20 000 руб.: пошаговый чек-лист"
- "Почему вашу клинику не находят в Яндексе (и как это исправить)"
Структура статьи:
1. Проблема (боль ЦА)
2. Контекст (почему это важно)
3. Решение (ваш подход)
4. Кейс или данные (доказательство)
5. Выводы (что делать дальше)
Реальные цифры
Одна хорошая статья на Habr:
- 5 000-15 000 просмотров
- 0-5 обращений
Если публикуете 1 статью в неделю, через 3 месяца получите устойчивый поток тёплых лидов.
Временные затраты
- Исследование темы: 1-2 часа
- Написание черновика: 2-3 часа
- Редактура и оформление: 1 час
- Итого: 4-6 часов на статью
С использованием нейросетей (см. пункт 5) время сокращается до 2-3 часов.
Риски и ограничения
Долгая отдача. Первые результаты появятся через 1-2 месяца. Это марафон, не спринт.
Требует экспертизы. Если вы не разбираетесь в теме, это будет видно. Аудитория Habr и VC критична к пустым статьям.
Модерация. На Habr строгий отбор. Рекламные статьи удаляют. Пишите ценность, не продажу.
Суть метода
Вступаете в тематические чаты, отвечаете на вопросы, даёте экспертизу бесплатно. Люди запоминают вас как эксперта. Приходят с заказами.
Как делать
Найдите чаты:
Поиск по ключевым словам в Telegram:
- "маркетинг чат"
- "стартапы Россия"
- "предприниматели"
- "медицинский бизнес"
Или через TGStat — поиск и аналитика телеграм-каналов и чатов.
Выберите активные чаты.
Признаки живого чата:
- 10+ сообщений в день
- Конструктивные обсуждения (не спам)
- Вопросы участников получают ответы
Правила игры:
1. Не продавайте в лоб. Никаких "Делаем маркетинг для клиник, обращайтесь". Вас забанят.
2. Отвечайте на вопросы. Кто-то спросил про запуск контекста — дайте развёрнутый ответ с конкретикой.
3. Делитесь опытом. "Запускали для клиента квиз, конверсия выросла на 40%" — такое запоминается.
4. Будьте регулярны. 2-3 сообщения в неделю. Не нужно спамить, но и пропадать на месяц нельзя.
Как монетизировать:
После 2-3 недель активности люди начнут писать в личку: "Видел ваши ответы в чате. Можем обсудить проект?"
Реальные цифры
Из одного активного чата на 500-1000 человек можно получать 1-2 обращения в месяц.
Если вы в 5 чатах — это 5-10 лидов ежемесячно.
Временные затраты
- Поиск чатов: 1-2 часа (разово)
- Участие в дискуссиях: 30-60 минут в день
- Итого: ~15 часов в месяц
Риски и ограничения
Долгая раскачка. Первые лиды придут через месяц-два. Нужно терпение.
Репутационные риски. Один неверный совет — и вас запомнят негативно. Давайте только проверенную информацию.
Время. Нетворкинг требует регулярности. Пропустили месяц — начинаете заново.
Суть метода
Создаёте бесплатную карточку компании в Яндекс.Картах и 2ГИС. Настраиваете правильно. Получаете органические заявки от людей, которые ищут услуги рядом.
Как делать
Шаг 1: Создайте карточку
- Яндекс.Карты: business.yandex.ru
- 2ГИС: 2gis.ru/firmsonmap
Заполните все поля:
- Название
- Адрес (точный, с фото вывески)
- Телефон и сайт
- Часы работы
- Категории (выберите все релевантные)
- Фото (минимум 5-10 качественных)
Шаг 2: Оптимизируйте описание
Пропишите ключевые услуги. Пример для стоматологии: "Семейная стоматология в Отрадном. Лечение кариеса, отбеливание, имплантация. Приём по записи и без. Первичная консультация бесплатно."
Шаг 3: Соберите отзывы
Просите клиентов оставлять отзывы. Чем больше положительных отзывов, тем выше в поиске. Отвечайте на все отзывы — даже на негативные. Это повышает доверие.
Шаг 4: Обновляйте регулярно
Добавляйте фото, акции, новости. Активные карточки ранжируются выше.
Реальные цифры
По данным анализа медицинских клиник (из практики работы с клиентами):
- Карточка в топ-3 по запросу "стоматология рядом" → 30-50 звонков в месяц
- CPL (условная стоимость лида) в 3-5 раз ниже контекстной рекламы
Если средний CPL в Яндекс.Директе для медицины 2000 руб., то через карты — 400-700 руб. (время на ведение карточки пересчитано в деньги).
Временные затраты
- Создание карточки: 1-2 часа
- Обновление контента: 30 минут в неделю
- Итого: ~3 часа на запуск + 2 часа в месяц
Риски и ограничения
Работает только для локального бизнеса. Если вы продаёте услуги по всей России — это не ваш канал.
Конкуренция. В Москве и Питере в топ-3 пробиться сложнее. В регионах проще.
Зависимость от платформы. Яндекс может изменить алгоритм — ваши позиции упадут.
Суть метода
Используете ChatGPT, Qwen, DeepSeek и другие бесплатные нейросети для создания черновиков контента. Экономите 60-70% времени на рутине.
Инструменты
Текстовые нейросети:
- ChatGPT 5.4 mini (бесплатно с ограничениями): генерация текстов, идеи, структура статей
- Claude 4.6 (бесплатно с лимитами): лучший для текстов, качественная генерация длинных форм, отлично подходит для статей и аналитики
- Qwen (бесплатно): китайская модель с хорошим пониманием контекста
- DeepSeek (бесплатно): альтернатива для технических текстов
Визуальные нейросети:
- ChatGPT (DALL-E 3) (бесплатно с лимитами): встроенная генерация изображений
- Qwen VL (бесплатно): визуальная модель от Qwen
- Nana Banana (с VPN): качественная генерация креативов
- Шедеврум (бесплатно от Яндекса): быстрая генерация картинок для соцсетей
Как использовать
1. Структура статей
Промпт для ChatGPT или Claude:
"Контекст: Я маркетолог, пишу статью для владельцев медицинских клиник. Тема: снижение стоимости лида в контекстной рекламе.
Задача: Создай подробную структуру статьи с разделами: проблема (почему CPL высокий), анализ причин (3-4 типичные ошибки), решение (пошаговый план), реальный пример с цифрами, выводы.
Формат: Заголовки разделов с 2-3 тезисами под каждым. Объём итоговой статьи: 4000 знаков."
Получите структуру. Дополните данными и примерами из практики. Отредактируйте под свой стиль. Готово.
2. Структура постов для соцсетей
Промпт:
"Контекст: Telegram-канал о маркетинге для малого бизнеса.
Задача: Создай структуру поста про квизы на лендингах.
Формат: Хук (1 предложение с вопросом или болью) → Проблема (2 предложения) → Решение (квиз: как работает) → Цифры (конверсия до/после) → Призыв к действию.
Объём: 600 знаков. Стиль: прямой, короткие абзацы, без воды."
3. Структура Email-рассылок
Промпт:
"Контекст: Холодная B2B-рассылка руководителям стоматологий.
Задача: Создай структуру письма с предложением настройки контекстной рекламы.
Формат: Персонализированное вступление (1 предложение о клинике получателя) → Проблема (типичная боль: высокий CPL или мало заявок) → Наш опыт (1 кейс с цифрами за 1 предложение) → Предложение (что конкретно сделаем) → Мягкий призыв к действию (без давления).
Тон: профессиональный, уважительный, без агрессивной продажи. Длина: 800 знаков."
4. Креативы для рекламы
Используйте ChatGPT (DALL-E 3), Qwen VL, Nana Banana или Шедеврум для генерации изображений под рекламные объявления.
Промпт для ChatGPT (DALL-E 3):
"Create a professional photograph of a modern dental clinic interior. Requirements: natural daylight coming through large windows, clean white and light blue color scheme, state-of-the-art dental chair visible in the background, minimal medical equipment shown, bright and welcoming atmosphere. Style: commercial photography, high resolution, professional lighting, shallow depth of field. No people in the frame."
Промпт для Nana Banana:
"Professional dental clinic advertisement image, photorealistic style, modern minimalist interior design, white and blue color palette, natural lighting, clean surfaces, medical professionalism meets comfort, 4K quality, Canon EOS R5 aesthetic"
Промпт для Шедеврум:
"Современная стоматологическая клиника, интерьер, естественный свет из больших окон, белые и голубые тона, профессиональное оборудование на фоне, чистота и уют, реалистичное фото, высокое качество"
Реальные цифры
С использованием AI:
- Статья на 4000 знаков: было 4-6 часов → стало 2-3 часа
- 10 постов для соцсетей: было 3 часа → стало 1 час
- Email-рассылка на 50 писем: было 5 часов → стало 2 часа
Экономия времени: 50-70%
Временные затраты
- Обучение работе с промптами: 3-5 часов (разово)
- Генерация + редактура контента: в 2 раза быстрее ручной работы
Риски и ограничения
AI — не замена мозгу. Нейросети выдают шаблонные тексты. Нужна редактура и добавление конкретики из вашего опыта.
Фактические ошибки. Нейросети могут придумать несуществующие данные. Всегда проверяйте факты.
Лимиты бесплатных версий. ChatGPT и Claude ограничивают количество запросов. Qwen и DeepSeek — тоже. Чередуйте инструменты.
Узнаваемый AI-стиль. Опытный читатель распознает AI-текст. Добавляйте личный опыт, конкретные примеры, цифры из практики.
Эти пять инструментов работают. Проверено на практике запуска агентства и работе с клиентами.
Что важно понимать:
1. Время — ваш бюджет. Бесплатно = вы платите временем. Если у вас есть деньги, лучше купить рекламу. Если денег нет — вкладывайте руки.
2. Результаты не мгновенные. Первые лиды через аутрич придут через неделю. Через контент — через месяц-два. Через нетворкинг — через 1-2 месяца.
3. Масштабирование ограничено. Вы один — можете делать 20 аутричей в день. Это 5-10 клиентов в месяц максимум. Хотите больше — нанимайте людей или покупайте рекламу.
4. Комбинируйте методы. Используйте все пять одновременно. Аутрич даёт быстрые результаты. Контент работает на долгую. Нетворкинг строит репутацию.
Реалистичный прогноз:
Если вы будете делать это системно 2-3 месяца:
- 10-20 лидов в месяц из аутрича
- 5-10 лидов из контента
- 3-5 лидов из нетворкинга
- 5-15 лидов из Яндекс.Карт (для локального бизнеса)
Итого: 23-50 лидов в месяц без бюджета на рекламу.
При конверсии из лида в клиента 10-20% это 2-10 новых клиентов. При среднем чеке 50 000 руб. выходит 100-500 тысяч выручки.
Цифры реалистичные. Но требуют работы. Каждый день. Без выходных первые 3 месяца.
Если готовы — вперёд. Если хотите быстрее — ищите деньги на рекламу.
Дмитрий Сатаров
Основатель "Эй, Стартапер!", наставник в Яндекс Практикум
С введением белых списков и ограничением доступа в интернет у рекламодателей могут появится закономерные мысли - Яндекс в белых списках, поэтому он откроется. Но мой сайт не в белых списках (если же ваш сайт в белых списках, то просто проигнорируйте этот пост, мы тут малым бизнесом выживаем) и он недоступен. А реклама моего сайта в Директе при этом показывается, потому что у Яндекса нет причин убирать его из выдачи. И вот пользователь заходит в Яндекс, вводит поисковый запрос, видит мой сайт, переходит по нему и… всё, белый (или какой там) экран.
Спишутся ли деньги за такой переход? С этим вопросом мы обратились в техподдержку Яндекса на что получили предельно точный ответ - “Отстаньте, мы сами без понятия”. Ну или можете понять их ответ, как сами хотите.
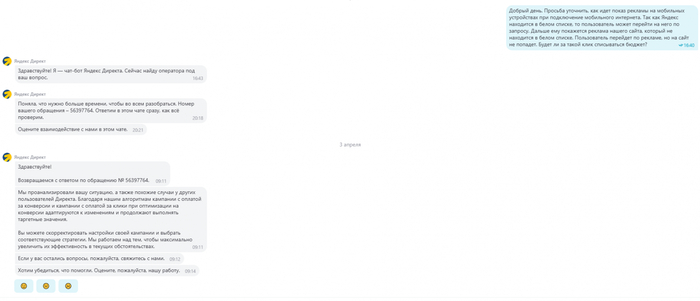
Скрин переписки с техподдержкой Яндекса
Вопрос
Добрый день. Просьба уточнить, как идет показ рекламы на мобильных устройствах при подключение мобильного интернета. Так как Яндекс находится в белом списке, то пользователь может перейти на него по запросу. Дальше ему покажется реклама нашего сайта, который не находится в белом списке. Пользователь перейдет по рекламе, но на сайт не попадет. Будет ли за такой клик списываться бюджет?
Ответ Яндекса
Мы проанализировали вашу ситуацию, а также похожие случаи у других пользователей Директа. Благодаря нашим алгоритмам кампании с оплатой за конверсии и кампании с оплатой за клики при оптимизации на конверсии адаптируются к изменениям и продолжают выполнять таргетные значения.
Вы можете скорректировать настройки своей кампании и выбрать соответствующие стратегии. Мы работаем над тем, чтобы максимально увеличить их эффективность в текущих обстоятельствах.
То есть, при оплате за конверсии с вас, естественно, ничего не спишут. А вот при оплате за клики вполне, но, возможно, меньше, потому что алгоритмам нужно придерживаться установленных в настройках значений стоимости конверсии. Ну или просто напишет, что обучение остановлено, ничего не получится, у алгоритма лапки.
Затем Яндекс выкатил новую штуку - резервная посадочная страница (https://yandex.ru/support/direct/ru/efficiency/backup-landing-page).
Как это работает? У Яндекса какое-то уже время есть возможность создавать внутри рекламного кабинета мини лендинги - некрасивые, с малой функциональностью, но зато можно запустить рекламу без сайта (олды помнят, что когда-то у яндекса уже были Турбо-сайты, но потом их убрали).
Теперь можно активировать настройку, что в случае недоступности основного сайта, пользователь увидит этот лендинг (который доступен, ведь он на домене Яндекса). Ну, спасибо, наверное, но звучит как не то, чтобы я хотел рекламировать. Если для локального бизнеса (салон маникюра, парикмахерская, шиномонтаж) это не так страшно, то вот остальному бизнесу будет очень не приятно.
С другой стороны, к вам хоть как-то смогут зайти, хоть и не через ту дверь. У плебеев из органической выдачи такой альтернативы нет.