


Stable Diffusion для ЛЛ
24 поста
24 поста
ОСТОРОЖНО! Очень громкий звук.
Как автор это сделал:
- Сначала я ротоскопирую отснятый материал с помощью After Effects.
- Затем я создаю маску, используя кадры ротоскопии.
- (Необязательно. D зависимости от компьютера) я конвертирую кадры в секунду в 12 кадров в секунду как для отснятого материала, так и для маски.
- После этого я экспортирую отснятый материал и маски в виде последовательностей PNG в их собственные папки.
- Затем я запускаю automatic1111 и перехожу на вкладку img2img.
- Я использовал модель animelike25D и установил значение CFG на 7. Denose Strength на 0,25 и шаги примера на 25.
- Для ControlNet я установил одну вкладку в openpose, а другую в depth.
- Затем я запускаю пакетную вкладку в img2img и устанавливаю входное и маскирующее изображения, а также выходную папку.
Как видим большая часть работы это создание маски.
Мои ссылки:
• Нейронная академия - канал с авторскими гайдами по SD и всем что с ним связано.
• Нейроновости - канал с новостями о нейросетях SD|MJ|ChatGPT и др.
• Нейронная эстетика - канал, где выкладываю красивости и интересности из разных нейросетей и описываю как это сделано.
• Чат - место где я собрал единомышленников, где мы делимся своими работами, обсуждаем разное и помогаем друг другу.
А так же ютуб канал и бусти с доп материалами.
Группа разработчиков представила интересный метод локального изменения стиля. Все происходит за счет изменения цвета слов, размера шрифта или стиля в виде сноски. А главное, что изменения применяются локально. Ждем в automatic1111?
Онлайн Демо (его интерфейс пока не так удобен).
Страница проекта. С большим количеством примеров.
Мои ссылки:
• Нейронная академия - канал с авторскими гайдами по SD и всем что с ним связано.
• Нейроновости - канал с новостями о нейросетях SD|MJ|ChatGPT и др.
• Нейронная эстетика - канал, где выкладываю красивости и интересности из разных нейросетей и описываю как это сделано.
• Чат - место где я собрал единомышленников, где мы делимся своими работами, обсуждаем разное и помогаем друг другу.
А так же ютуб канал и бусти с доп материалами.
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.

Если ControlNеt у вас еще нет, то в автоматике идем в Extension-Available жмем Load from. Ищем ControlNet, жмем Install. Скачиваем модели. И кидаем по пути ваша_папка_с_автоматиком/extensions/sd-webui-controlnet/models. Всё. Вы готовы. Можем начинать.
А теперь скачаем новинку. Перейдите по ссылке и скачайте t2iadapter_style_sd14v1.pth. Помещаем туда же куда и все модели контролнета.
Ваша_папка_с_автоматиком/extensions/sd-webui-controlnet/models
Не забудьте обновить сам контролнет, если давно этого не делали. На вкладке Extension.
Переходим txt2img. Сегенерируйте картинку на свой вкус, чтобы посмотреть как она выглядит без новинки. А теперь активируем контролнет. Препроцесср установите clip_vision, а модель t2iadapter_style_sd14v1.
У меня будет вот такая:

Мои настройки (обратите внимание на Weight):
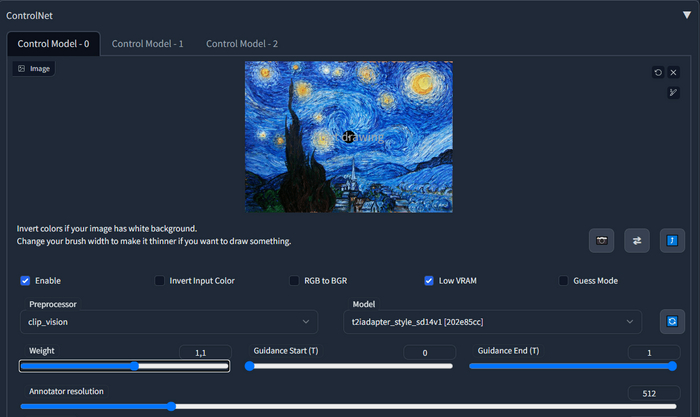
Из за вот этой Картины Ван Гога, я некоторое время не мог понять как это работает, но и она же все же дала понять как. Я прогнал один промпт через десятки фотографий.
Часть образцов:

Результат:

Обратите внимание как переносится стиль. Это не простой перенос цвета. Например от мужика переехали усы. А от картины "Звездная ночь" только небо и немного город. Тут я и догнал что это как мини обучение. Он понимает что это именно небо и поэтому менял мне небо. Он нашел на фотографии которая имела совсем другие пропорции усы и прилепил похожие. И тд. и тп. Что как я считаю довольно круто.
Результат просто промпта:

++++++

====

За артефакты сорян, не про них статья)
Игры с имг2имг предлагаю вам устроить самостоятельно:

Что хочется отметить. Очень важен ползунок Weight. На 1 можно даже не увидеть воздействия. Лучшие результаты я получал на диапазоне 1.05-1.4. Для разных изображений по разному. Так же рекомендую поиграть с Guidance Start\End. При высоком весе, отстрочить вступление контролнета может дать результат как выше.
П.С. Это не единственная новая модель. Есть еще color, но он просто выделяет главные цвета из изображения и накладывает на новое, делает это довольно грязно. Если хотите попробовать то по той же ссылке файл t2iadapter_color_sd14v1, а препроцессор для него color.
Мои ссылки:
Нейронная академия - мой канал для которого пишу гайды, новости, советы.
Наш чат - место где мы общаемся, делимся работами, помогаем друг другу с решением проблем.
Интенсив - где за 2 дня собираемся обучить всех желающих основам использования SD.
Челенджи - раз в день, неделю, месяц публикуем тему и выясняем кто справился лучше.
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
Сегодня расскажу про одну из самых вау фишек ControlNet.
Интересно что эта возможность была доступна со старта, но ее не сразу нашли.
Прежде чем начать, кратко для новоприбывших, как установить контролнет. В автоматике идем в Extension-Available жмем Load from. Ищем ControlNet, жмем Install. Скачиваем модели. Сегодня нам понадобится depth. И кидаем по пути ваша_папка_с_автоматиком\extensions\sd-webui-controlnet\models. Всё. Вы готовы. Можем начинать. Если не совсем готовы можете прочитать мою статью про ControlNet - полный контроль над позой и положением персонажа. И Установка и объяснение настроек Control Net. (Копирование позы, композиции и т.д.)
Запускаем наш automatic1111. Нам нужна сгенерированная картинка с которой будем работать.
Я возьму старую и закину в img2img через pngInfo чтобы применились все настройки генерации.
Теперь нужно активировать ControlNet и закинуть в него туже самую картинку. Препроцессор выбираем depth модель control_depth.
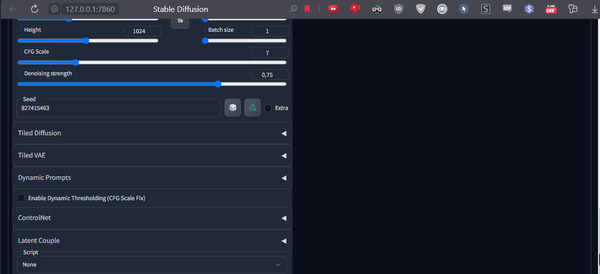
Что мы сделали? У нас все параметры генерации настроены так, чтобы сгенерировать ту же самую картинку. Но генерировать мы ее будем по карте глубины этой самой картинки. А теперь самая главная магия. Мы поменяем исходное изображение на что-нибудь интересное, например на чёрно-белую картинку с нарисованным светом (легко найти в интернете по запросу свет на черном фоне).
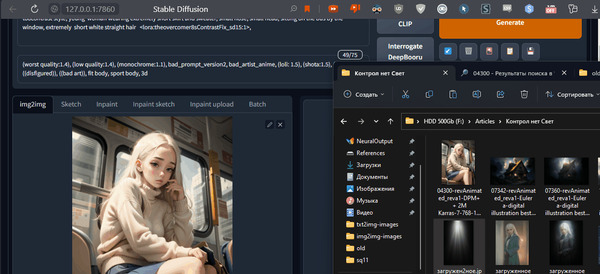
В итоге получаем наш промпт, который применен к карте обьема нашей же картинке в контролнете только ко всему этому мы подмешиваем еще одну картинку.
И это все так гладко ложится потому что у нас есть информация об объеме нашего изображения. Надеюсь понятно объяснил .
Но даже если не понятно, не важно. Это просто работает).
Сейчас настройки выглядят так


Теперь необходимо настроить Denoising strength. Тут все просто, чем ближе к левой части тем ближе вы будете к картинке вверху, в данный момент освещения. Чем ближе к правой, к картинке в контролнете.
Крайнее правое значение:

В крайнем левом будет просто наша картинка со светом.
Ваша задача найти баланс для вашей сцены.
Для меня это где-то в диапазоне 0.5 до 0.9. Сделаю для вас сравнение через XYZ Plot. Как им пользоваться рассказывал у себя на канале.

0.3-1 [8] - Значит: сгенерируй 8 изображений с равным шагом в диапазоне межу ноль три и один.

И теперь самое интересное.
Мы можем использовать одно и то же изображение для получения разных результатов. Например, сейчас будем перемещать источник света.
Идем к нашему свету, нажимаем карандаш и указываем какую область картинки мы хотим использовать:
Внимание. На дату написания этого гайда 04.04.23 в актуальной версии автоматика, то что я показываю далее работает не корректно (картинка обрезается). Для записи гайда я откатился на более старое обновление. Как это делать рассказывал тут.
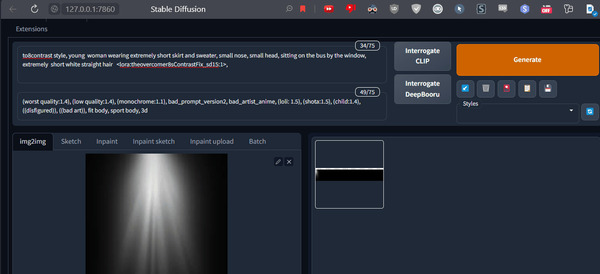
Можно уменьшать область и тем самым указать только верхний пучок или наоборот только низ.

Пример с другой картинкой:

Конечно же вы можете использовать как референс другие изображения:


Но и это еще не все.
Мы можем рисовать свет сами. Для этого выставляем все вот так. (Я взял другую картинку, более подходящую для того что сейчас будем делать)

И отправляем верхнюю картинку в скетч.
В скетче намечаем наш новый свет.

Да, я хз как правильно рисовать свет, поэтому я в нейронках
Хочу чтобы рефлекс от экрана проявлялся сильнее. Могу сгенерировать прямо отсюда, но это покрасит мне все волосы в рыжий.
Поэтому отправляю в инпейнт.

К сожалению, у меня получилась скорее гематома, этот инструмент для кого-то порукастее, чем я .
Попробую восстановить свою репутацию на другой картинке.

Ладно, всё, сдаюсь. Надеюсь в ваших руках этот инструмент будет полезней .
А на этом на сегодня всё.
Мои ссылки:
Нейронная академия - мой канал для которого пишу гайды, новости, советы.
Наш чат - место где мы общаемся, делимся работами, помогаем друг другу с решением проблем.
Интенсив - где за 2 дня собираемся обучить всех желающих основам использования SD.
Челенджи - раз в день, неделю, месяц публикуем тему и выясняем кто справился лучше.
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
Энтузиасты натренировали ControlNet на датасете LAION-Face dataset, чтобы улучшить уровень контроля при создании изображений лиц.

Хотя другие модели ControlNet могут использоваться для позиционирования лиц в сгенерированном изображении, мы обнаружили, что существующие модели страдают от аннотаций, которые либо недостаточно ограничены (OpenPose), либо чрезмерно ограничены (Canny / HED / Depth). Например, мы часто хотим контролировать такие вещи, как ориентация лица, открыты / закрыты глаза / рот и в каком направлении смотрят глаза, что теряется в модели OpenPose, а также не зависит от деталей, таких как волосы, подробная структура лица и не-лицевые черты, которые будут включены в аннотации, такие как canny или карты глубины. Достижение этого промежуточного уровня контроля стало стимулом для обучения этой модели.
Текущая версия модели не идеальна, в частности, в отношении направления взгляда. Авторы надеются улучшить это в следующей версии.
Так же они обнаружили, что многие ограничения модели сами по себе могут быть устранены путем расширения запроса на генерацию. Например, включение таких фраз, как "открытый рот", "закрытые глаза", "улыбающийся", "сердитый", "взгляд вбок", часто помогает, если модель не учитывает эти особенности. (Довольно очевидная вещь о которой я рассказывал тут)

Более подробную информацию о наборе данных и модели можно найти на Hugging Face странице модели. Авторы создали открытый запрос на добавление в sd-webui-controlnet в расширение для automatic1111. В настоящее время они сделали доступной модель, обученную на основе базовой модели Stable Diffusion 2.1, и и находятся в процессе обучения модели на основе SD 1.5, которую надеются выпустить в ближайшее время. У них есть форк Репозитория ControlNet который включает в себя сценарии для извлечения набора данных и обучения модели.

Для заинтересованных в обучении или дальнейшем обсуждении авторы предлагают присоединиться к их Discord.
Источник: Reddit.
А теперь перевожу на совсем русский). К сожалению модель пока работает только с моделью SD 2.1 или основанными на ней. Например Иллюминати. Но хорошая новость в том что над версией 1.5 они работают. А так же отправили запрос создателями ControlNet чтобы их препроцессор был добавлен с одним из обновлений в интерфейс контролнета в автоматике. Но если вы не хотите ждать и понимаете что делаете все необходимые для установки ссылки есть в статье.
Поделиться результатом своей работы или задать вопрос, а так же пообщаться с единомышленниками вы можете в нашем нейробратском комьюнити.
Больше гайдов на моем канале, подписывайтесь чтобы не пропустить.
Так же анонсируем интенсив, который создали в содружестве с другими нейроэнтузиастами. Ознакомиться с его программой и временем проведения можно по ссылке.
Попробовать можно по ссылке
Тарифные планы доступные на сайте:

На моем свежесозданном аккаунте оказалось 525 кредитов. Одна секунда видео тратит 14 кредитов. Хватит, для того чтобы провести пару экспериментов.
Похоже, что сайт испытывает большой наплыв пользователей и регулярно падает. Так что возможно стоить зайти попозже.
Так же напомню что была анонсирована Gen-2. Нейросеть способная создавать видео лишь по текстовому описанию.
И хочу напомнить что уже вышел опенсорс аналог, о котором я писал на канале ранее (Пикабу).
Поделиться новостями или задать вопрос, а так же пообщаться с единомышленниками вы можете в нашем нейробратском комьюнити (ТГ).
А на моем канале (ТГ) вы можете найти кучу гайдов по использованию нейросетей.
TLDR: Че тут происходит вообще? Я тут делюсь своим опытом по работе с нейронками. Если тебе эта тема интересна, но ты только начал вникать загляни ко мне в профиль или в конец статьи, там есть полезные ссылки. Сейчас это может быть слишком сложным для тебя.
Привет, сегодня мы изучим основы получения фотореализма в ваших генерациях По большому счету нам необходимым всего 2 вещи, первая и самая, пожалуй, главная это модель, а второе - грамотный промптинг, начнем с модели.

Мы будем работать "deliberate". Потому что на аниме моделях заниматься этим глупо, а на фотореалистичных слишком просто. Напишем "woman". Посмотрим, что у нас получится:

Ни туда, ни сюда. Это еще не фото, но уже и не рисунок. Не то, что мы сегодня хотим достичь. Вообще модели можно поделить на две большие категории. Одна категория выдает годноту уже с парой слов (то есть работает примерно как миджорней), другим же нужно навалить "мяса". "Deliberate" по большей части относится ко второй. Что является платой за гибкость.
Добавим конкретики. a photo of woman

Лучше. Продолжаем
Думаем как думает модель. При обучении ей скармливали изображения с подписями о том что на нем изображено. Значит нам нужны подписи которые могли быть под фотографией.
photography, 4k, 8k, 100mm, canon EOS, dof, analog photo, dslr, bokeh, grain и так далее, много их. Часть выкладывал файлов в свой группе. Дальше можно поработать над деталями и вот тут люди часто делают ошибку. Они пишут realistick eyes, hyperrealistick skin и так далее. Это подсказки которым место наоборот в негативе так как относятся хоть и к крайне детализированным, но все же картинам и рендерам. Мы используем detailed skin, detailed face, intricate detailed
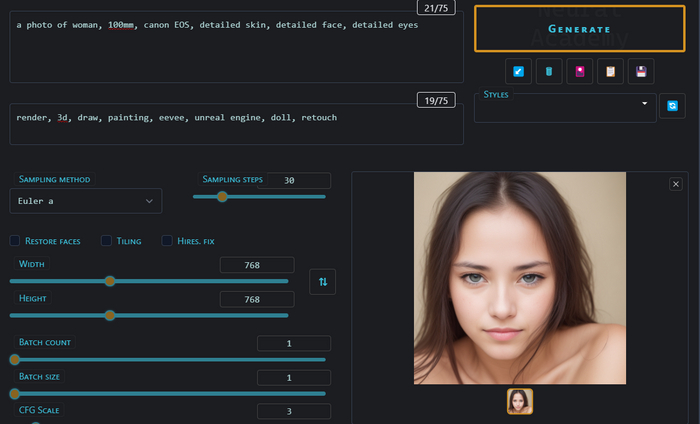

Мы уже ближе, но все еще есть самая большая ошибка. Идеальная кожа. Да мы уже можем видеть поры, но она ну слишком гладкая. Нет ни родинок ни смены пигментации. Ни-че-го. Это сильно бьет по натуральности картинки. Без нашего вмешательства сетка обычно такое не добавляет. Вмешаемся.
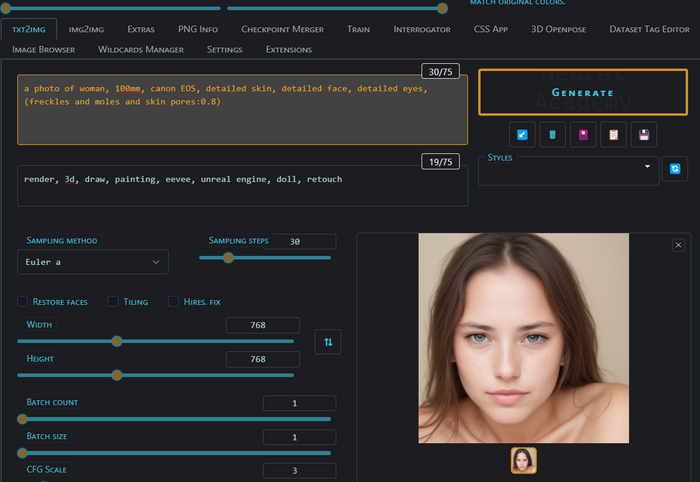

Так же обратите внимание на CFG - он всего 3. Хотя обычная рекомендация 7-11. Но я обнаружил что большинство моделей в реализме показывают себя лучше с довольно низким CFG.
+ pigmentation

В общем, дефекты кожи наш бро. А кто еще наш бро? Правильный семплер конечно. Видим что "фотка" слегка заблюрена. Это дело рук Eauler a. Переставим на DPM ++ 2M Karras и сразу получаем вот такой прирост:

Кстати выше я упоминал токен inricate detailed будьте с ним осторожны, это очень сильный токен который сильно умножит нам детали и получим вот это. Токены бываю как слабыми так и сильными. Некоторые на первый взгляд могут вообще не давать эффекта, но оказывают хорошее действие в совокупности с другими. Как видим эффект этого токена на лицо.

Сверху это всё можно полернуть нейросетевым апскейлером. Например, через Hires fix или SD Upscale. Но учтите, что скорее всего вам прийдется отрегулировать вес дефектов. Они могут начать проявляться слишком сильно.
Подведем итог. Для фотореализма нужно:
Выбрать правильную модель
Правильный промптинг
Выбрать подходящий семплер
Не забыть про дефекты
Правильный CFG
Все советы это лишь советы, а не строгие правила. Например, добавление realistick eyes может наоборот улучшить вашу работу если грамотно подобрать ему вес.
Еще один пример применения этих советов на практике:

Поделиться результатом или задать вопрос, а так же пообщаться с единомышленниками вы можете в нашем нейробратском комьюнити.
Больше гайдов на моем канале, подписывайтесь чтобы не пропустить:
На моем бусти вы сможете найти датасеты для обучения, доп материалы к гайдам и многое другое. Или просто финансово отблагодарить если мои материалы вам как-то помогли.









