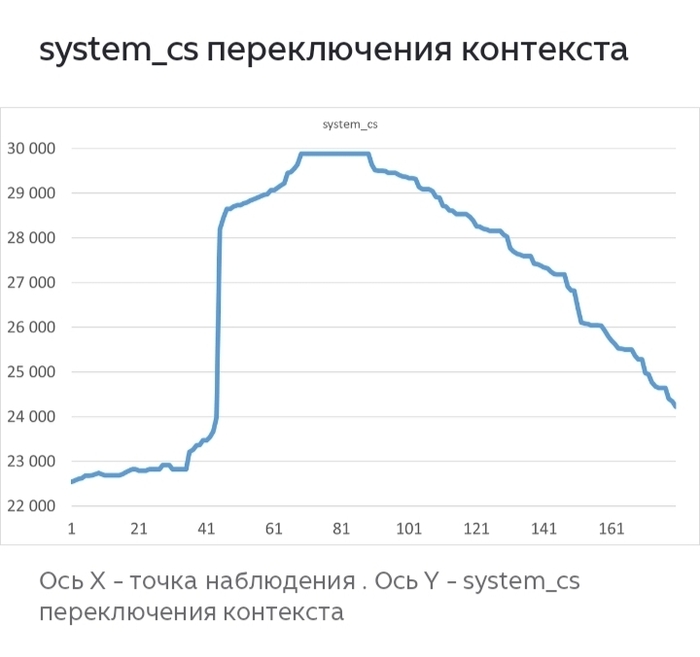
Как количество переключений контекста (показатель cs , утилиты vmstat) является критичным для СУБД PostgreSQL при ресурсах CPU=2 и RAM=2GB при экспоненциальном росте нагрузки с 5 до 115 сессий pgbench ?
Почему выводы нейросети DeepSeek о связи количеств переключений контекста (значение cs результата vmstat) не соответствует данным полученным в ходе эксперимента для СУБД PostgreSQL с ресурсами CPU=2 и RAM=2GB при экспоненциальном росте нагрузке от 5 до 115 соединений , для нагрузки генерируемой pgbench ?
Почему выводы нейросети DeepSeek о связи количеств переключений контекста (значение cs результата vmstat) и производительности СУБД PostgreSQL не соответствует данным полученным в ходе эксперимента для СУБД PostgreSQL с ресурсами CPU=2 и RAM=2GB при экспоненциальном росте нагрузке от 5 до 115 соединений , для нагрузки генерируемой pgbench ? Вывод о зеркальности графика TPS и cs полностью ложен. Как улучшить качество ответов DeepSeek для того , чтобы рекомендации нейросети можно было применять в практических задачах ?
В своем предыдущем ответе ты сказал, что график TPS и cs зеркальный , но данные эксперимента показывают прямую корреляцию значений TPS и cs . Пересмотри свой вывод с учетом этого противоречия .
Почему ты уверен, что имея полное описание всех конфигурационных параметров СУБД и строгое описание сценария тестирования ты сможешь точно предсказать картину изменения производительности СУБД, не имея математической модели процессов ?
В итоге можно ли сделать вывод , что значение cs это не причина а следствие изменения производительности СУБД PostgreSQL в ходе нагрузочного тестирования ? И мониторинг cs не имеет практического смысла ?
Какое количество переключений контекста (показатель cs , утилиты vmstat) является критичным для СУБД PostgreSQL при ресурсах CPU=2 и RAM=2GB при экспоненциальном росте нагрузки с 5 до 115 сессий pgbench ?
Цитата из ответа:
График TPS: Сначала растет линейно, затем выходит на плато, а после пика (~20-30 сессий) резко падает вниз.
График cs: Сначала пологий, затем его рост резко ускоряется, и он уходит в вертикальный взлет как раз в точке, где TPS начинает падать.
Эти два графика зеркальны друг другу.
Реальные данные эксперимента:
Итог
Реальные данные полностью противоположны выводам нейросети.
В каких случаях возникает ожидание SpinDelay в СУБД PostgreSQL ?
Цитата из ответа :
Ожидание SpinDelay в PostgreSQL возникает в ситуациях, связанных с конкуренцией за spin-блокировки (spinlocks). Эти блокировки используются для синхронизации доступа к критическим структурам данных в многопроцессорных системах. Вот основные случаи, когда возникает SpinDelay:
1. Высокая конкуренция за разделяемые ресурсы
Ситуация: Множество процессов одновременно пытаются получить доступ к одним и тем же структурам данных (например, буферам кеша, очереди блокировок, счётчикам).
Причина: Spin-блокировки предназначены для очень краткосрочной синхронизации. Если процесс не может захватить блокировку с первой попытки, он входит в цикл повторных попыток (spin loop), где между попытками вводится задержка SpinDelay.
...
Вопрос нейросети :
Какое ожидание указывает на высокую конкуренцию за разделяемые ресурсы в СУБД PostgreSQL ?
Разумно и логично ожидать в ответе, в том числе упоминание ожидания SpinDelay? Это разумно , для любого человека с памятью не как у гуппи. Но, нейросеть не интеллект , алгоритмы статистического анализа текста устроены по другому и ничего общего не имеют с механизмами рассуждения человека. В результате , в ответе - нейросеть даже не упоминает ожидание SpinDelay:
В PostgreSQL ожидания, связанные с высокой конкуренцией за разделяемые ресурсы, обычно проявляются через события типа LWLock (Lightweight Lock) в представлении pg_stat_activity. ...
Вывод: в общем то неудивительно и вполне ожидаемо - пока, LLM это дорогие игрушки . Применять в качестве рабочего инструмента - чрезвычайно рискованно , по причине ложных и неполных ответов. Любой ответ LLM нужно проверять экспериментально с использованием методов объективного контроля.
P.S. Теперь придется дополнять список анализируемых ожиданий в pg_hazel ожиданием Timeout. И повторно анализировать характерные ожидания при выполнении стресс тестирования СУБД. И скорее всего SpinDelay окажется характерным ожиданием при ситуации недостатка вычислительных ресурсов .
Может быть когда ни будь в будущем, нейросети и смогут реально помогать в экспериментах , пока лучше не доверять их ответам.
К вопросу о том, что нейросеть в обозримом будущем не может заменить инженера , обладающего данными экспериментов .
У нейросети просто нет экспериментальных данных, но проблема не в этом. Глобальная проблема нейросетей — выдача ответа в условиях недостатка данных.
Сказано уже 100500 раз — ВСЕ ОТВЕТЫ НЕЙРОСЕТИ НУЖНО ПРОВЕРЯТЬ ЭКСПЕРЕМЕНТАЛЬНО, НИКАКОЙ ИНФОРМИИ НЕЙРОСЕТЕЙ ДОВЕРЯТЬ НЕЛЬЗЯ .
Статистически обработать огромные массивы информации — да, тут нейросеть поможет. Но, сделать исследования нового — тут нейросеть принципиально бессильна, у нее просто нет данных. А результат она выдает.
Вводные данные
Оценить влияние кардинального снижения параметра хранения таблиц fillfactor c базового значения 100 до 50, при агрессивной настройке autovacuum.
Допустим какой-то продвинутый DBA ,
следующий в русле новых тенденций решил не тратить время и задал вопрос нейросети DeepSeek:
Как повлияет уменьшение параметра fillfactor c 100 до 50 для таблицы с количеством строк примерно 60000000 на количество и время работы autovacuum для СУБД PostgreSQL c ресурсами CPU=2 , RAM=2GB при интенсивных операциях SELECT + UPDATE примерно в среднем 1000 транзакций в секунду, при нагрузке от 5 до 48 одновременных сессиях, при агрессивных настройках autovacuum для тестовой таблицы : autovacuum_vacuum_scale_factor=0 и autovacuum_vacuum_threshold=1000 ?
Ответ нейросети DeepSeek
Уменьшение параметра fillfactor с 100 до 50 для таблицы с 60 млн строк в PostgreSQL при указанных условиях существенно повлияет на работу autovacuum, преимущественно негативно. Вот анализ последствий:
1. Увеличение размера таблицы и фрагментации
Физический рост таблицы: При fillfactor=50 каждая страница таблицы заполняется только на 50%, что удваивает её физический размер (с ~60 млн строк до эффективных ~120 млн страниц). Это увеличит I/O-нагрузку и объём данных для обработки autovacuum.
Рост индексов: Индексы также увеличатся, так как новые версии строк (от UPDATE) будут чаще размещаться в новых страницах (из-за нехватки места в исходных), что дополнительно нагрузит autovacuum.
2. Частота запуска autovacuum
Агрессивные настройки: autovacuum_vacuum_threshold=1000 и autovacuum_vacuum_scale_factor=0 означают, что autovacuum запускается после каждых 1000 изменений (UPDATE/DELETE).
Интенсивность UPDATE: При 1000 транзакций/сек (часть из которых — UPDATE) порог в 1000 изменений будет достигаться каждую секунду. Это приведёт к почти непрерывной работе autovacuum.
3. Время работы autovacuum
Увеличение длительности циклов: Autovacuum должен сканировать вдвое больше страниц (из-за fillfactor=50), что резко увеличит время каждого запуска. Например: При fillfactor=100: сканирование 1 млн страниц. При fillfactor=50: сканирование ~2 млн страниц.
Ресурсные ограничения: Слабые ресурсы (2 CPU, 2 GB RAM) не позволят autovacuum справляться с возросшим объёмом. Нехватка памяти вызовет активное использование диска (I/O), замедляя процесс.
4. Проблемы из-за нехватки ресурсов
Конкуренция за I/O: Autovacuum будет постоянно читать/писать данные на диск, конкурируя с пользовательскими запросами (SELECT/UPDATE). Это увеличит задержку транзакций.
Нехватка памяти: Буферный кэш (shared_buffers) ограничен ~512 MB (25% от 2 GB RAM). Таблица размером > 2x не поместится в кэш, что вызовет чтение с диска и замедлит все операции.
Риск блокировок: Длительные циклы autovacuum могут конфликтовать с пользовательскими транзакциями, особенно при 48 одновременных сессиях.
5. HOT-обновления: частичное смягчение
Преимущество fillfactor=50: Свободное место в страницах может повысить долю HOT-обновлений (когда новые версии строк помещаются в ту же страницу). Это уменьшит фрагментацию и нагрузку на индексы.
Ограниченная польза: На фоне удвоенного объёма таблицы и слабых ресурсов этот эффект не компенсирует общее снижение производительности.
6. Риск накопления dead tuples
Autovacuum может не успевать: При такой частоте UPDATE и нехватке ресурсов autovacuum будет отставать от нагрузки. Это вызовет: Рост dead tuples. Увеличение I/O (из-за чтения "мертвых" строк). Замедление SELECT (из-за необходимости фильтрации мёртвых версий). Блот (bloat) таблицы и индексов.
Рекомендации
Не снижать fillfactor до 50 на такой конфигурации. Оптимально: fillfactor=80–90 (если требуются HOT-обновления).
Увеличить порог autovacuum: Например, autovacuum_vacuum_threshold = 10000 (вместо 1000), чтобы сократить частоту запусков.
Вывод: Уменьшение fillfactor до 50 на маломощном сервере с агрессивным autovacuum вызовет хроническую нехватку ресурсов, рост времени вакуумирования и общее снижение производительности. Без увеличения RAM/CPU это изменение не рекомендуется.
«Вот оно как» — подумает продвинутый DBA , следующий в русле новых тенденций и не будет менять параметр fillfactor.
Другой инженер, якудза старой школы
не верит бездушным алгоритмам и решает проверить всё лично.
И приходит к очень интересным, и прямо противоположным результатам.
Итоги
Для данной СУБД и данного сценария нагрузки , уменьшение параметра хранения таблиц на 50% c 100 до 50 , повысило эффективность работы autovacuum:
Количество запусков autovacuum увеличилось на 261% c 193 до 697
Максимальное время работы autovacuum уменьшилось на 29% с 936 сек. до 663 сек.
Среднее время работы autovacuum уменьшилось на 73% с 46 сек. до 12 сек.
Предельная нагрузка на autovacuum увеличивалась на 50% с 8 до 12 соединений.
Молодой DBA, следующий в русле новых тенденций и доверяющий математическим алгоритмам статистической обработки текстов — потерял шанс сильно улучшить работу одного из ключевых механизмов СУБД PostgreSQL — autovacuum.
Старый, тертый жизнью и не доверяющий новым веяниям DBA — получил конкретный полезный результат и запланировал новые эксперименты по оптимизации и настройке СУБД.
Немного тонкой настройки и СУБД будет работать как часы.
Вопрос нейросети:
Какой параметр для настройки автовакуума для СУБД PostgreSQL эффективнее использовать для очень больших таблиц : autovacuum_vacuum_scale_factor или autovacuum_vacuum_threshold ?
Ответ DeepSeek:
Для очень больших таблиц в PostgreSQL эффективнее использовать параметр autovacuum_vacuum_threshold, а не autovacuum_vacuum_scale_factor. Вот обоснование:
Проблема autovacuum_vacuum_scale_factor для больших таблиц:
Масштабируемость: Формула запуска автовакуума: autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * table_size. По умолчанию: threshold = 50, scale_factor = 0.2 (20%). Для таблицы на 1 млрд строк порог срабатывания: 50 + 0.2 * 1 000 000 000 = 200 000 050 мертвых кортежей. Это приводит к редким запускам и накоплению огромного числа мертвых кортежей.
Риски: Замедление запросов: Длинные таблицы (из-за мертвых кортежей) снижают производительность. Блокировки: Очистка большого объема данных блокирует операции. Срыв транзакций: Если autovacuum не успевает очищать данные до заполнения autovacuum_freeze_max_age.
Почему autovacuum_vacuum_threshold эффективнее?
Фиксированный порог: Позволяет задать абсолютное число мертвых кортежей для запуска (независимо от размера таблицы). Пример: ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000); Автовакуум запустится при достижении 1 млн мертвых кортежей, даже если таблица содержит 1 млрд строк.
Гранулярность: Настройка применяется индивидуально к большим таблицам без влияния на маленькие. Оптимальные значения: от 100 000 до 10 000 000 (зависит от нагрузки и размера).
Рекомендуемая стратегия:
1. Уменьшить scale_factor:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.01); -- 1%
Для таблицы на 1 млрд строк порог: 50 + 0.01 * 1e9 = 10 000 050.
2. Увеличить threshold:
ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000);
Порог: 1 000 000 (фиксированный, без умножения на размер).
3.Комбинировать параметры:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.005, -- 0.5%autovacuum_vacuum_threshold = 500000);
Формула: 500 000 + 0.005 * N.
Дополнительные настройки:
autovacuum_vacuum_cost_limit (увеличить для ускорения):
ALTER TABLE big_table SET (autovacuum_vacuum_cost_limit = 2000); -- вместо 200 по умолчанию
autovacuum_naptime (уменьшить интервал проверок).
Итог:
Для очень больших таблиц:
Основной параметр: autovacuum_vacuum_threshold (фиксированный порог).
Вспомогательный: autovacuum_vacuum_scale_factor (уменьшать до 0.1–0.5%).
Настраивать индивидуально для таблицы через ALTER TABLE.
Мониторить эффективность через представление pg_stat_user_tables (столбцы n_dead_tup и last_autovacuum).
Какие типы ожидания wait_event_type будут иметь наибольшую корреляцию со снижением производительности СУБД PostgreSQL при выполнении UPDATE для виртуальной машины CPU = 2 и RAM = 2GB при росте нагрузки с 5 до 115 одновременных соединений ?
Ответ нейросети
При анализе корреляции между типами ожиданий (wait_event_type) в PostgreSQL и снижением производительности во время UPDATE на слабой ВМ (2 vCPU, 2 ГБ RAM) при росте нагрузки с 5 до 115 соединений, наибольшую корреляцию будут иметь следующие типы ожиданий, ранжированные по степени влияния:
1. LWLock (Lightweight Locks)
Почему корреляция высокая:
На слабых ВМ (особенно с 2 vCPU) нехватка CPU усиливает конкуренцию за системные ресурсы.
LWLock защищает внутренние структуры данных (буферы, память, lock-менеджер). При высокой нагрузке (115 соединений) процессы блокируются в очередях на эти ресурсы.
Подтипы buffer_content, buffer_mapping, lock_manager будут доминировать из-за частого доступа к буферам и блокировкам.
Связь с производительностью: Прямая корреляция с ростом времени ожидания и снижением TPS (transactions per second).
2. Lock (Транзакционные блокировки)
Почему корреляция высокая:
UPDATE вызывает эксклюзивные блокировки строк (ROW SHARE/EXCLUSIVE).
При 115 соединениях конкуренция за одни строки/таблицы резко возрастает → частые ожидания снятия блокировок.
Возникает при ожидании доступа к буферу данных, удерживаемому другим процессом.
Усиливается при нехватке RAM и высокой конкуренции за буферы.
Менее критичен, чем LWLock/Lock, но значим при массовых UPDATE.
Итог: Наибольший вклад в снижение производительности внесут LWLock и Lock из-за нехватки CPU/RAM и высокой конкуренции. IO станет критичным при исчерпании буферного кеша.
Как обстоит ситуация в реальности :
Результаты
Для данного сценария "Update only"и данной конфигурации СУБД характерными значениями корреляции между ожиданиями СУБД и типами ожиданий , являются :
IO : сильная отрицательная корреляция , влияние ожиданий типа IO на производительность СУБД отсутствует.
IPC : ожидания практически отсутствуют, влияние на производительность СУБД отсутствует.
Lock : очень сильная прямая корреляция, сильное влияние ожиданий типа Lock на снижение производительности СУБД .
LWLock : слабая отрицательная корреляция , влияние ожиданий типа LWLock на производительность СУБД отсутствует.
В принципе - ничего неожиданного. Наивно было бы ожидать от алгоритма статистической обработки текстов в интернете исследований и логических выводов, тем более в отсутствии материалов и результатов реальных экспериментов.
Меня всегда интересовало - откуда вообще пошла рекомендация 25% RAM для shared_buffers ?
Спросил у DeepSeek
Кто первый рекомендовал значение 25% от размера RAM для параметра shared_buffers для СУБД PostgreSQL ?
Рекомендация устанавливать параметр **`shared_buffers`** в размере **25% от объёма оперативной памяти (RAM)** в PostgreSQL впервые появилась в **официальной документации проекта** и стала результатом **коллективного опыта разработчиков и сообщества**, а не авторства одного конкретного человека. Вот ключевые аспекты её происхождения и распространения:
---
### 📜 1. **Источник рекомендации** - **Документация PostgreSQL**: В ранних версиях документации (например, в версии 9.1 и более поздних) явно указано, что для серверов с RAM ≥1 ГБ "разумным начальным значением" является **25% от общего объёма памяти** . Например: > *"Если вы используете выделенный сервер с объёмом ОЗУ 1 ГБ и более, разумным начальным значением `shared_buffers` будет 25% от объёма памяти"* . - Эта рекомендация позже стала стандартом в руководствах по настройке производительности.
---
### ⚙️ 2. **Почему именно 25%?** - **Компромисс между кэшем PostgreSQL и ОС**: PostgreSQL использует двойное кэширование: - `shared_buffers` — внутренний кэш СУБД. - Кэш файловой системы ОС. При значении выше 25% возникает дублирование данных в памяти, снижающее эффективность. При этом выделение <25% ухудшает производительность чтения данных . - **Эмпирические тесты**: Эксперименты показали, что 25% обеспечивают баланс для большинства рабочих нагрузок (OLTP, аналитика). Например, тесты EDB в 2022 году подтвердили, что превышение 25% даёт незначительный прирост производительности, но повышает риски нехватки памяти для других процессов . ⚠️⚠️⚠️ Я провел серию тестов для EDB в 2022 году, чтобы определить, как общие буферы влияют на производительность PostgreSQL. Анализ проводился на устаревшем оборудовании с жесткими дисками и на более современных системах на базе SSD. В итоге мы пришли к выводу, что рекомендация 25 % в целом достаточна ⚠️⚠️⚠️ "(Из ссылки на результаты тестов) Вы серьезно ? Это называете тестом и рекомендацией !? Ни одной цифры , ни одного графика . Просто "мы пришли к выводу" . А почему я могу верить вашим выводам ? Выводы на чем основаны ? Я кстати, помню как во времена публикации на Хабре, один кекс в качестве критического комментария к моей статье по анализу производительности СУБД приводил эту статью. " ---
### 📣 3. **Распространение рекомендации** - **Сообщество и эксперты**: Совет стал общепринятым благодаря статьям на Habr , Crunchy Data , EnterpriseDB и в инструментах вроде **pgTune**. - **Реальные конфигурации**: В корпоративных решениях (например, для розничных сетей) параметр строго следует правилу 25%: - Для сервера с 6 ГБ RAM → `shared_buffers = 1.5 ГБ` . - Для 32 ГБ RAM → `shared_buffers = 8 ГБ` .
---
### ⚠️ 4. **Исключения** - **Системы с малым RAM** (<1 ГБ): Рекомендуется снизить долю до 15% или ниже . - **Специфические нагрузки**: - Для OLAP-систем с большими запросами иногда эффективнее 15–20% . - Для чисто записывающих (write-heavy) нагрузок избыток `shared_buffers` может замедлить работу из-за накладных расходов на запись WAL .
---
### 💎 **Заключение** Рекомендация в 25% для `shared_buffers` **не имеет единственного автора** — она сформирована разработчиками PostgreSQL на основе многолетнего опыта оптимизации. Её первое официальное упоминание появилось в документации (версии 9.x и ранее) , а затем было подтверждено практикой сообщества. Для современных систем это значение остаётся отправной точкой, но требует адаптации под конкретную нагрузку и мониторинг (например, через `pg_buffercache` и анализ соотношения попаданий в кэш) .
В общем , всё как обычно - в стародавние времена просто взяли цифру с потолка и затем рекомендация стала передаваться от одного акына к другому . При этом не особо и задумываясь над целесообразностью, обоснованностью и не проведя анализ и тесты. Что , в общем то подтверждает давно известное - основная масса DBA - ремесленники , верящие алхимикам. Подлинное научное и инженерное знание и опыт в DBA это исключение , чем правило.