Обратная сторона индекса: когда первичный ключ становится узким местом
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Мы привыкли, что индексы — это святое. Но под нагрузкой святыни иногда приходится пересматривать
В мире СУБД общепринятая догма гласит: «Индексы ускоряют запросы». Но что, если в погоне за производительностью мы создали себе проблему? В этой статье на практике исследуется парадоксальный сценарий, при котором удаление первичного ключа у таблицы pgbench_branch и последующее увеличение стоимости запроса привели к впечатляющему росту общей производительности PostgreSQL под нагрузкой. СУБД не так просты, как кажется.
Продолжение экспериментов с расширением pg_expecto, начатых в предыдущей работе:
Задача
Оценить удаление ограничения первичного ключа в таблице на производительность СУБД в ходе нагрузочного тестирования.
Тестовая таблица pgbench_branches
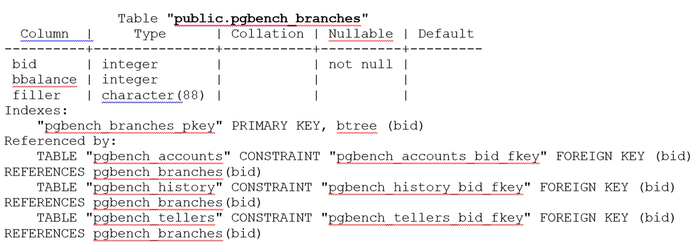
Тестовые запросы, в который участвует таблица pgbench_branches
Сценарий-1 "Select only"
Тестовый запрос
select br.bbalance
from pgbench_branches br
join pgbench_accounts acc on (br.bid = acc.bid )
where acc.aid = 1000 ;
План выполнения запроса
Nested Loop (cost=0.84..5.28 rows=1 width=4)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4)
Index Cond: (aid = 1000)
-> Index Scan using pgbench_branches_pkey on pgbench_branches br (cost=0.28..2.49 rows=1 width=8)
Index Cond: (bid = acc.bid)
Сценарий-2 "Select + Update"
Запрос-1,2
SELECT MIN(bid) FROM pgbench_branches ;
SELECT MAX(bid) FROM pgbench_branches ;
План выполнения запроса
Result (cost=0.31..0.32 rows=1 width=4)
InitPlan 1
-> Limit (cost=0.28..0.31 rows=1 width=4)
-> Index Only Scan Backward using pgbench_branches_pkey on pgbench_branches (cost=0.28..24.85 rows=685 width=4)
Update (тест)
UPDATE pgbench_branches SET bbalance = bbalance + 10 WHERE bid = 469 ;
План выполнения
Update on pgbench_branches (cost=0.28..2.49 rows=0 width=0)
-> Index Scan using pgbench_branches_pkey on pgbench_branches (cost=0.28..2.49 rows=1 width=10)
Index Cond: (bid = 469)
Эксперимент - удаление ограничения первичного ключа в таблице pgbench_branches
ALTER TABLE pgbench_branches DROP CONSTRAINT pgbench_branches_pkey CASCADE ;
pgbench_db=# ALTER TABLE pgbench_branches DROP CONSTRAINT pgbench_branches_pkey CASCADE ;
NOTICE: удаление распространяется на ещё 3 объекта
DETAIL: удаление распространяется на объект ограничение pgbench_tellers_bid_fkey в отношении таблица pgbench_tellers
удаление распространяется на объект ограничение pgbench_accounts_bid_fkey в отношении таблица pgbench_accounts
удаление распространяется на объект ограничение pgbench_history_bid_fkey в отношении таблица pgbench_history
Изменение планов выполнения
Сценарий-1 "Select only"
Тестовый запрос
select br.bbalance
from pgbench_branches br
join pgbench_accounts acc on (br.bid = acc.bid )
where acc.aid = 1000 ;
План выполнения запроса
Hash Join (cost=2.80..372.68 rows=1 width=4)
-> Seq Scan on pgbench_branches br (cost=0.00..366.78 rows=1178 width=8)
-> Hash (cost=2.79..2.79 rows=1 width=4)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4)
Index Cond: (aid = 1000)
Сценарий-2 "Select + Update"
Запрос-1,2
SELECT MIN(bid) FROM pgbench_branches ;
SELECT MAX(bid) FROM pgbench_branches ;
План выполнения запроса
Aggregate (cost=369.72..369.73 rows=1 width=4)
-> Seq Scan on pgbench_branches (cost=0.00..366.78 rows=1178 width=4)
Update (тест)
UPDATE pgbench_branches SET bbalance = bbalance + 10 WHERE bid = 469 ;
План выполнения
Update on pgbench_branches (cost=0.00..369.73 rows=0 width=0)
-> Seq Scan on pgbench_branches (cost=0.00..369.73 rows=1 width=10)
Filter: (bid = 469)
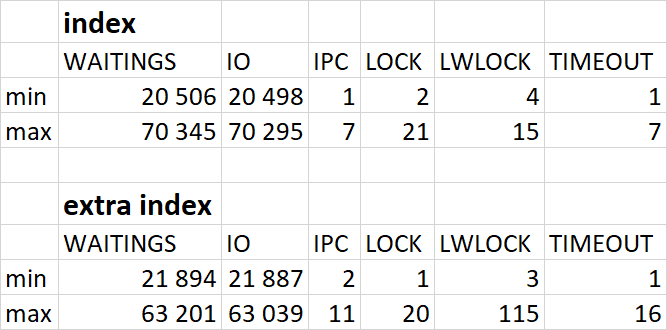
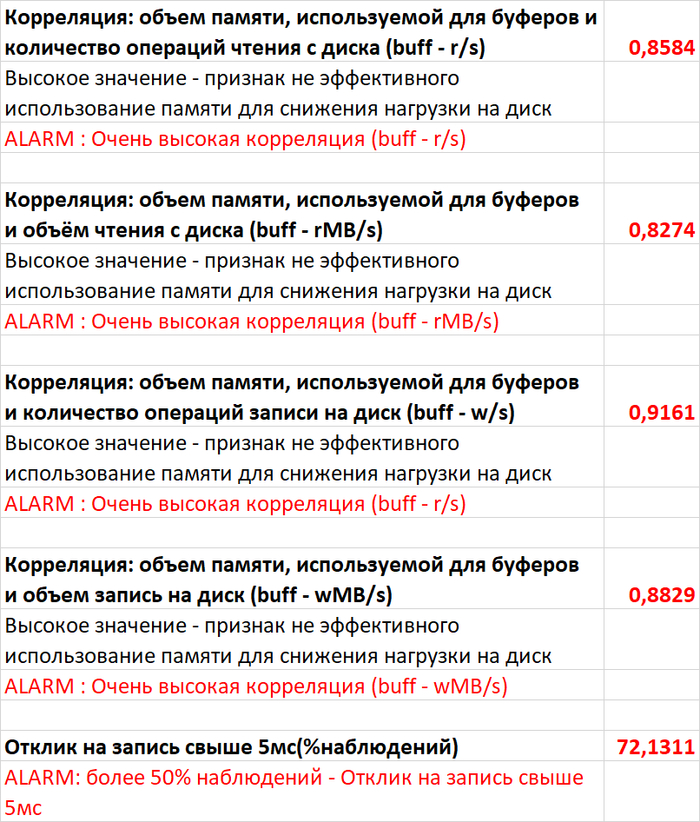
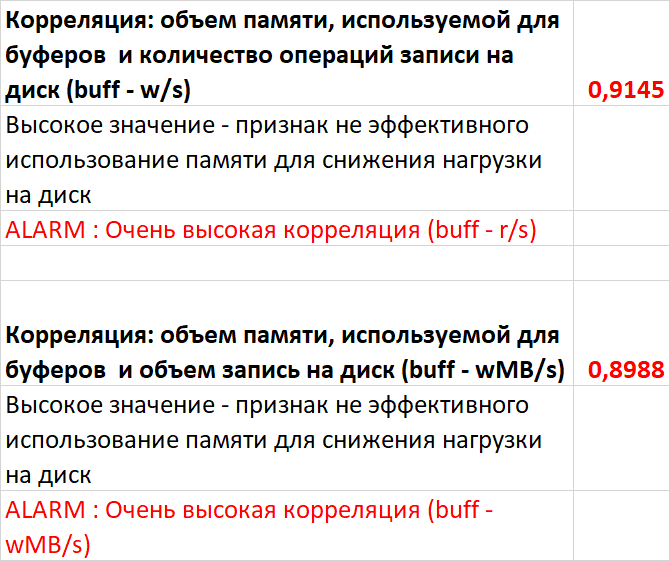
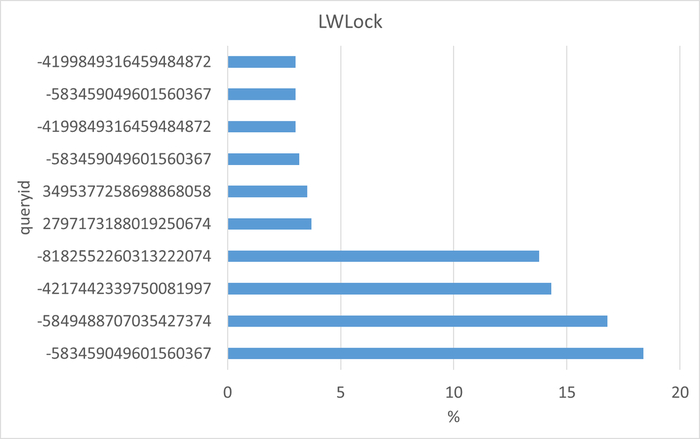
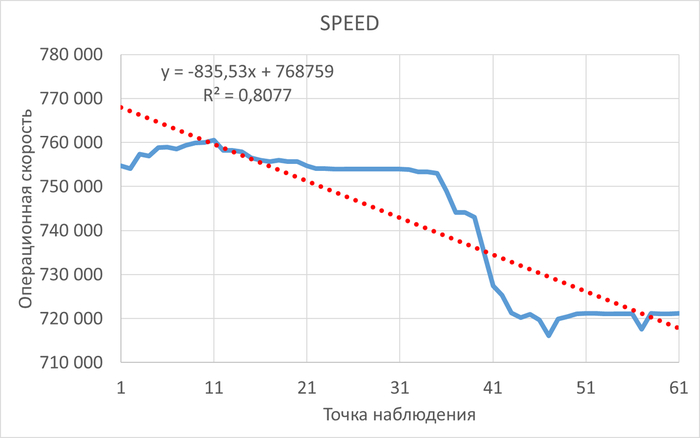
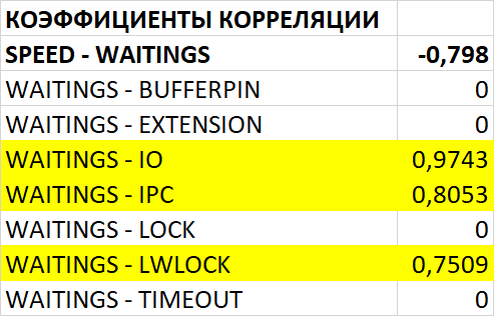
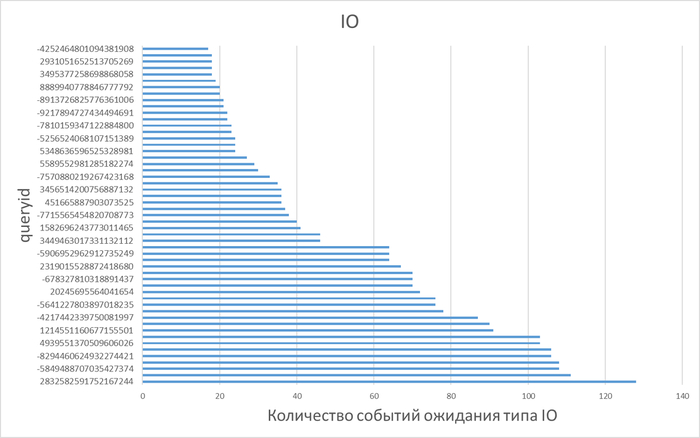
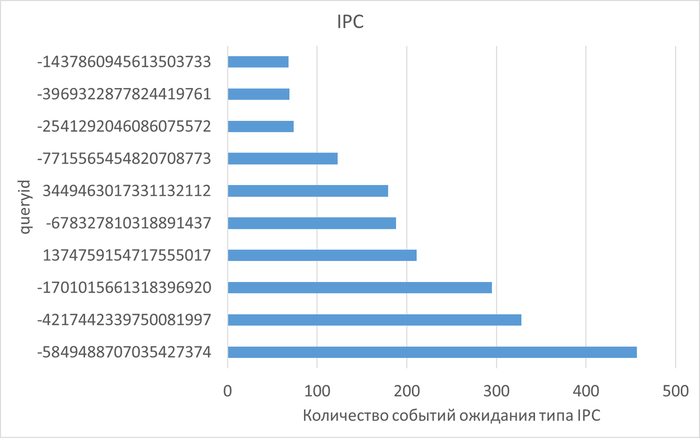
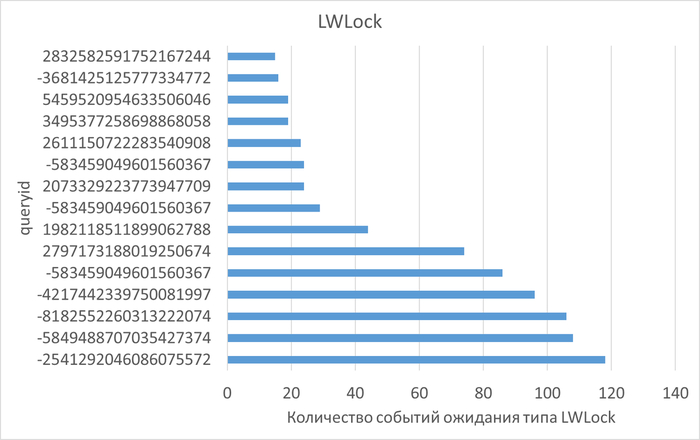
Изменение производительности в ходе нагрузочного тестирования (Эксперимент-2) по сравнению с базовыми значениями (Эксперимент-1)
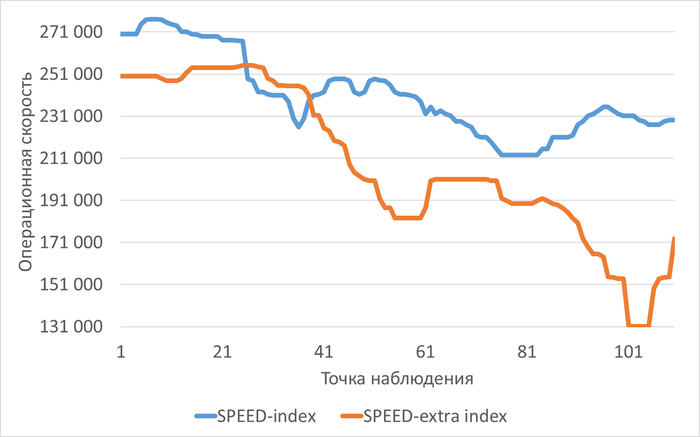
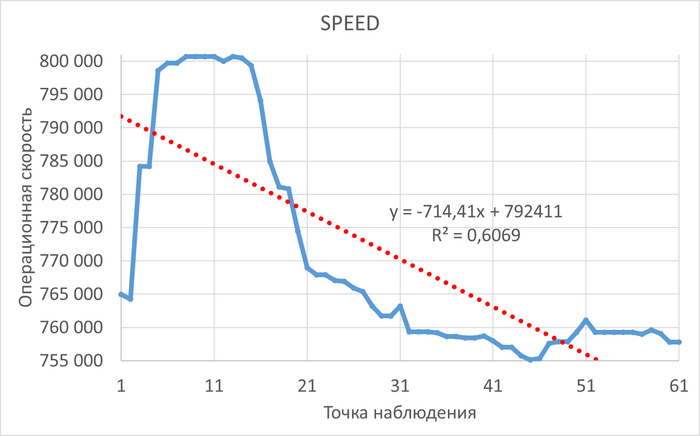
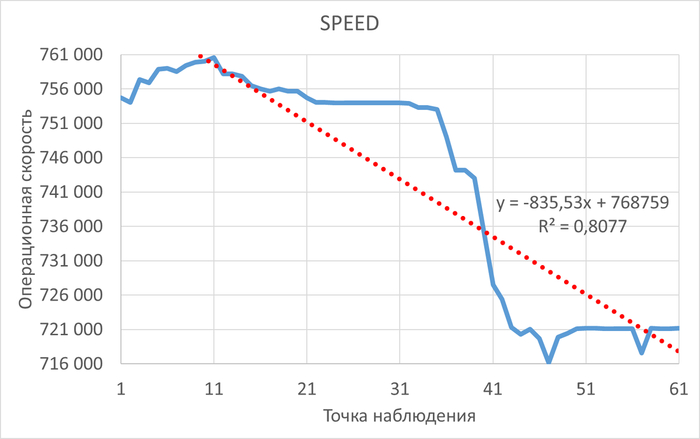
Операционная скорость
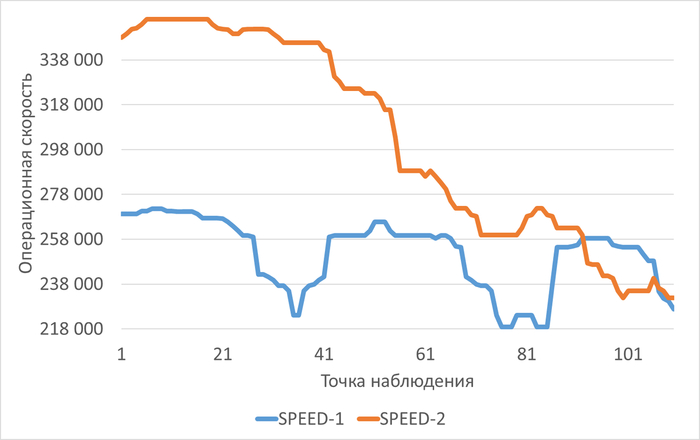
Графики операционной скорости в ходе Эксперимента-1(SPEED-1) и Эксперимента-2(SPEED-2)
Среднее увеличение операционной скорости в эксперименте-2 составило ~20%
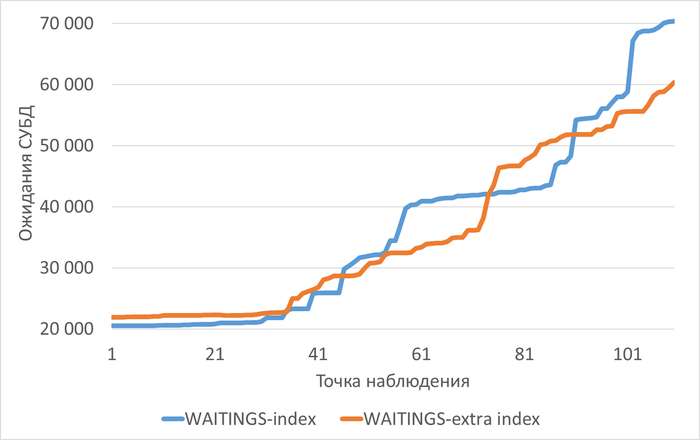
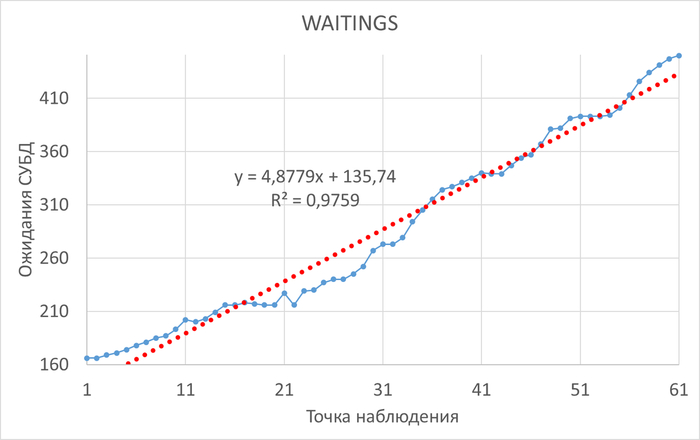
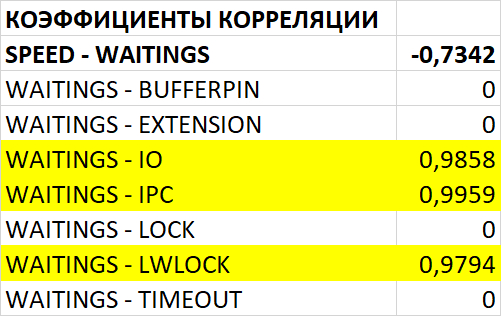
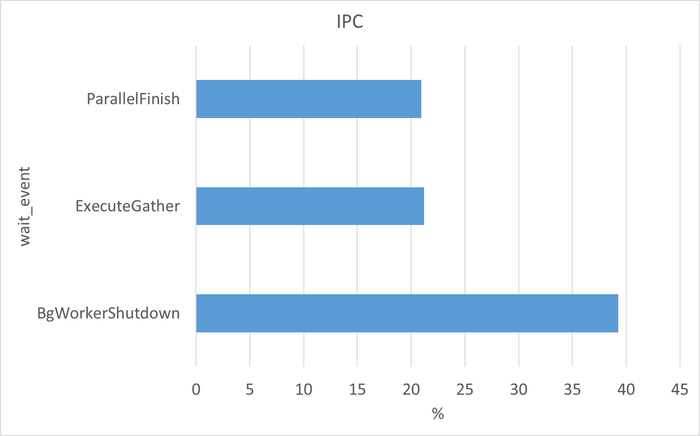
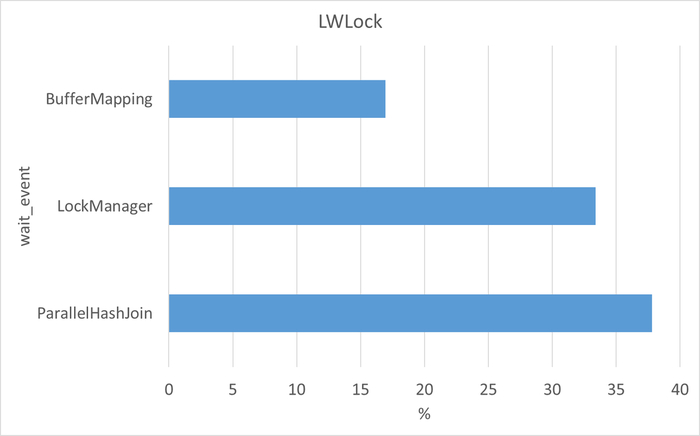
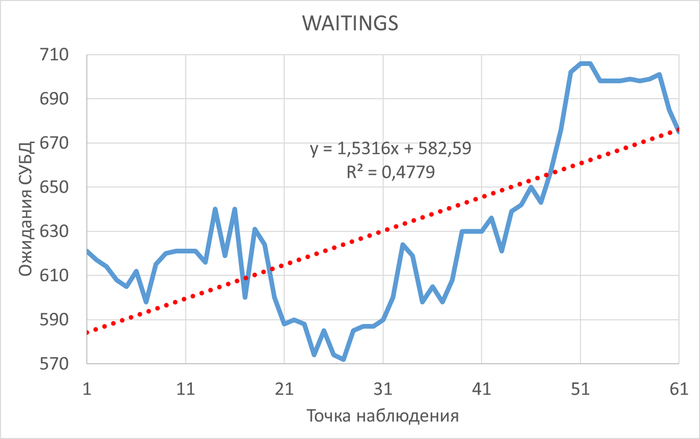
Ожидания СУБД
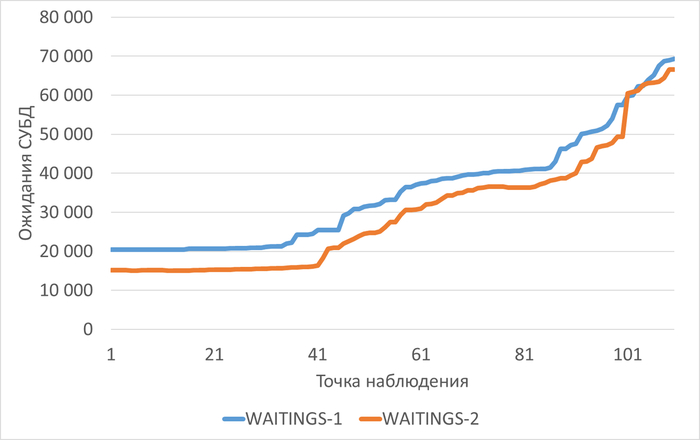
Графики ожиданий СУБД в ходе Эксперимента-1(WAITINGS-1) и Эксперимента-2(WAITINGS-2)
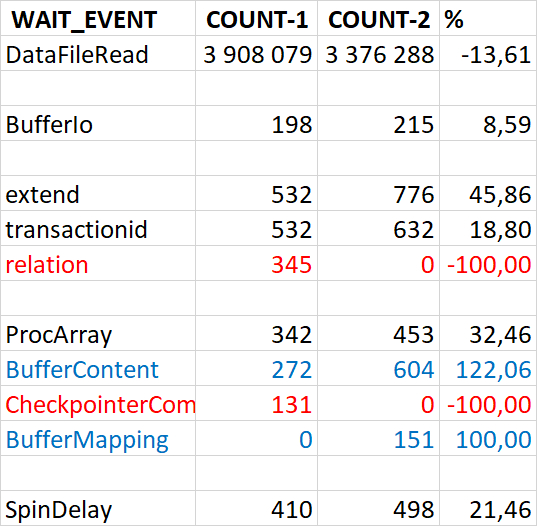
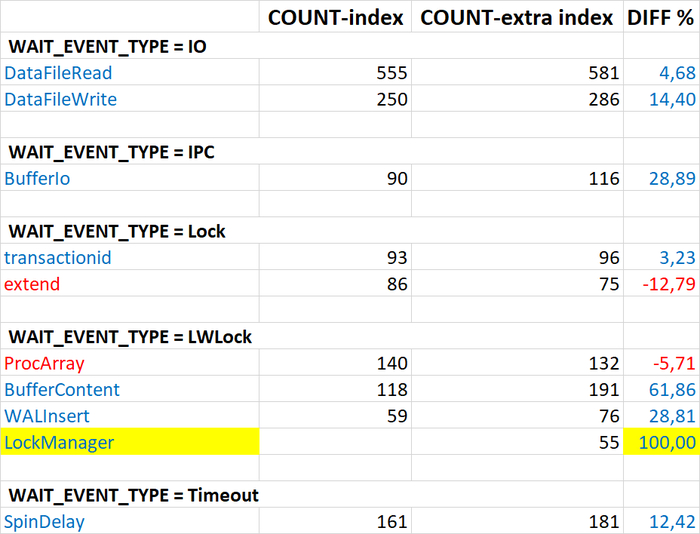
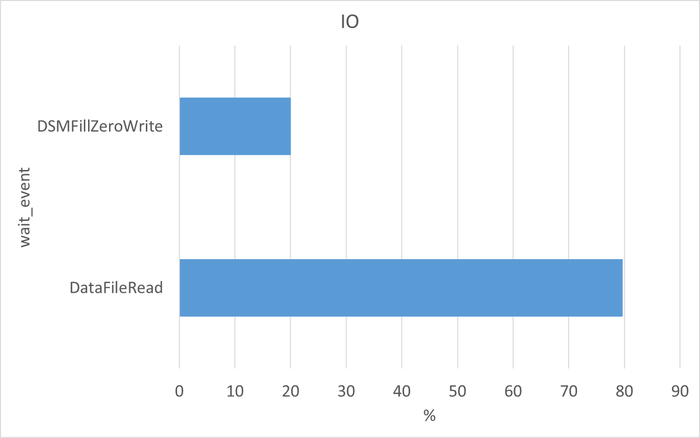
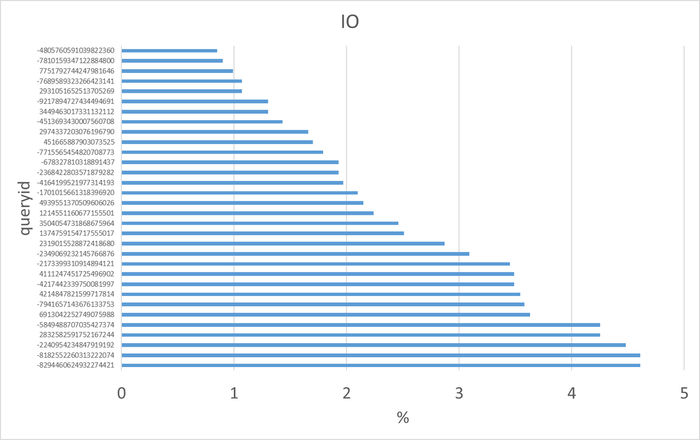
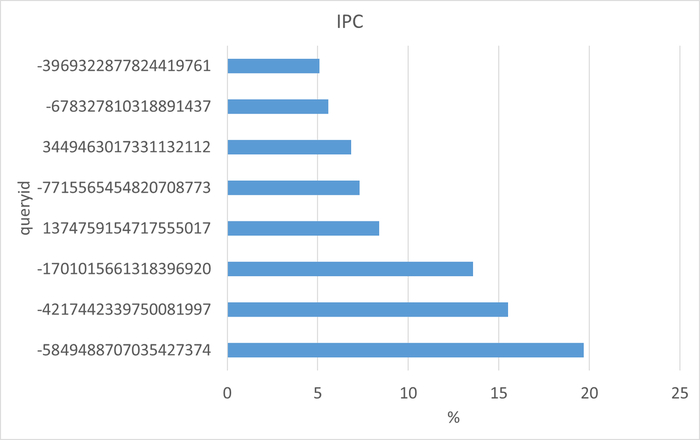
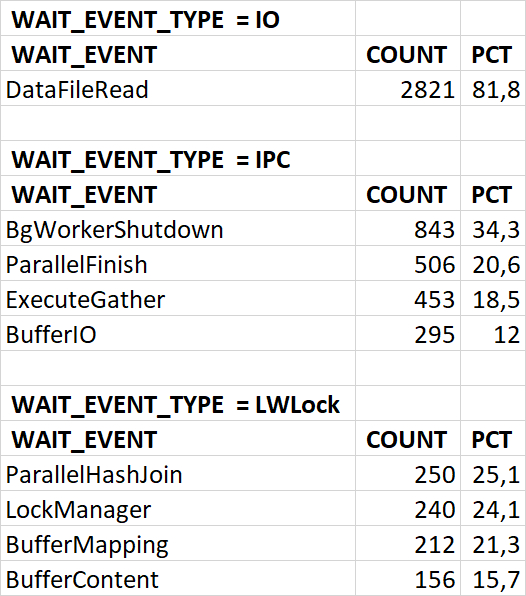
Ожидания по SQL запросам