Имеется SQL запрос используемый , используемый в качестве бенчмарка. Идея очень простая - среднее(медианное) время выполнения запроса является показателем пропускной способности СУБД в целом.
Гипотеза - увеличение benchmark кластера 📈при нулевом значении ожиданий - свидетельствует о нехватке вычислительной мощности для СУБД. Или другими словами - пропускная способность СУБД не соответствует характеру нагрузки.
При проведении нагрузочного тестирования хорошо видно, что после определённого значения нагрузки на СУБД (количество сессий pgbench), среднее время бенчмарк увеличивается . Т.е. если гипотеза подтвердится , то можно будет использовать бенчмарк для оценки пропускной способности СУБД.
В ходе работ по подготовке эпюры производительности СУБД в очередной раз была получена иллюстрация проблем использования среднего арифметического при расчете производительности СУБД .
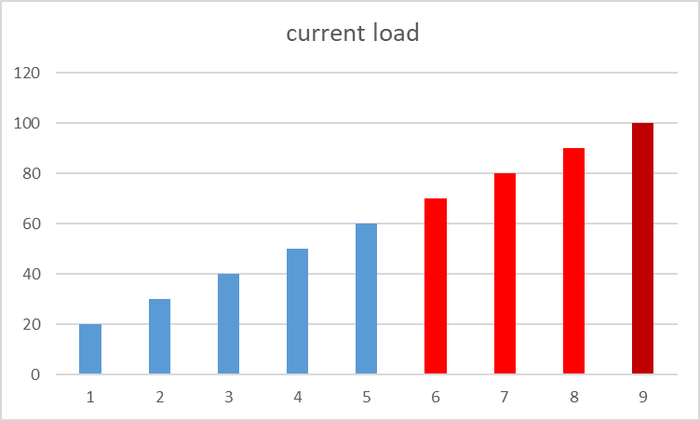
Последовательный рост нагрузки на СУБД
По X - номер итерации. По Y - количество сессий pgbench
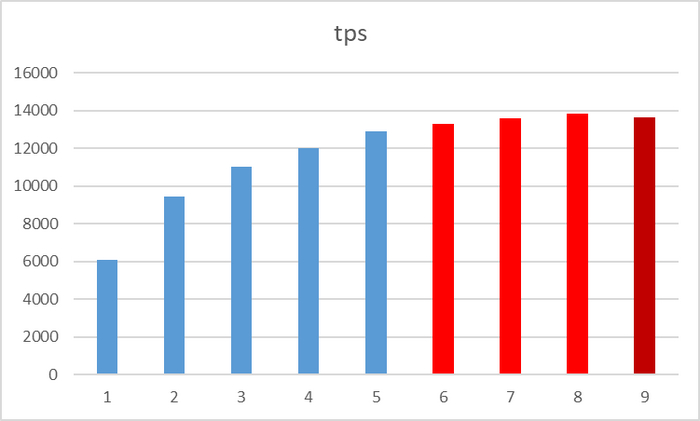
Результаты pgbench
Первые же результаты , показали несогласованность pgbench - TPS - с реальными показателями производительности СУБД
По оси X - номер итерации. По оси Y - TPS. TPS по результатам pgbench - растет.
Значение tps получено тривиально, из результата теста :
лог | grep tps
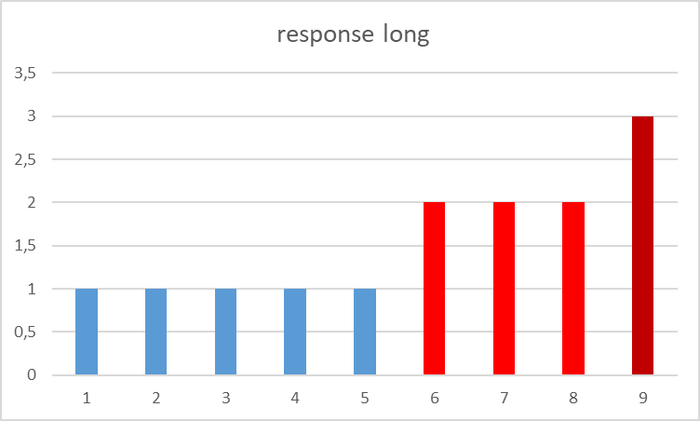
Среднее время отклика СУБД
По оси X - номер итерации. По оси Y - среднее время отклика СУБД.
Время отклика вычисляется , также, стандартно:
SUM(total_exec_time) / SUM(calls)
За период из представления pg_stat_statements.
И тут возникает 2 варианта анализа результатов:
1) Если ориентироваться на результаты pgbench, то , при росте количества подключений c 60 до 70 - tps вырос с 12870,870996 до 13294,489494 (+3%)
2) Если ориентироваться на среднее время отклика СУБД , то, при аналогичном росте количества подключений c 60 до 70 - среднее время отклика увеличилось на 100%
Вопрос - как анализировать результаты теста ?
Производительность СУБД растет с ростом нагрузки или нет ?
P.S.
Очередная иллюстрация на тему - ни TPS , ни время отклика - по отдельности не являются метриками производительности СУБД, потому, что не позволяют предсказать и описать реальную картину и получить объективные данные о реальной производительности СУБД .
P.P.S. Также нужно отметить, что история и анализ данных tps из лога pgbench с помощью grep - не самая удобная процедура . Особенно если не одна итерация, а несколько десятков.
Так, что - как средство создания нагрузки pgbench вполне рабочий и удобный инструмент. Как средство анализа результатов - нет.
Послесловие
Материал носит ознакомительный, справочный характер. Используемая методика расчета среднего времени отклика СУБД в настоящее время не используется. Вообще , среднее арифметическое в расчетах не используется. Да и методика расчета производительности СУБД сильно изменена , в настоящее время идут тесты и анализ результатов. Статьи будут чуть позже.
Статья завершает цикл статей о тестировании методики анализа результатов нагрузочного тестирования СУБД PostgreSQL . В настоящее время ведутся работы по совершенствованию методики расчета и сбора статистических данных производительности. По окончании разработки, сценарии тестирования будут повторены , результаты опубликованы с более детальным описанием процесса и результатов.
Задача и реализация эксперимента
Установить количественное влияние расположения файловой системы WAL на производительность СУБД.
В пределе - разницы нет. Но , есть некоторые моменты.
Для тестирования используется сценарий "Insert only" : 1000 INSERT в тестовую таблицу pgbench_history.
Тестируются 2 виртуальные машины : ВМ-1 , ВМ-2.
Версия СУБД - одинакова.
ОС - одинаковая.
Гипервизор - один.
Различия:
Системный диск: HDD / SSD
Файловая система /wal: HDD / SSD
Результаты эксперимента
Пояснение : по горизонтальной оси графиков(в данной и предыдущих статьях) - количество одновременных сессий pgbench.
Производительность СУБД
Некоторая разница в производительности - все таки наблюдается
Время выполнения тестовой транзакции
Разница по времени - практически отсутствует
Относительная разница производительности и времени работы
После 20 соединений разница в производительности и времени работы - несущественна
Итоги
При данном сценарии нагрузки , в данной облачной инфраструктуре - статистически значимая разница в производительности для СУБД с расположением файловой системы WAL на диске HDD или на SSD - отсутствует.
P.S. Еще одна иллюстрация по теме влияния HDD/SSD на скорость СУБД :
If you're running it on an enterprise level server (e.g. HP Proliant or similar) then there's a good chance that that writes to the HDDs are extremely fast because they're actually being written to a non volatile write cache. Ironic because writes to SSDs are much slower than reads so SSDs typically have their own RAM based write cache.
Часть 3 - Сценарий нагрузочного тестирования "Heavyweight"
Нужно выбирать
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "Heavyweight"
Тестовый запрос состоит только из выражений SELECT с использованием JOIN ,ORDER BY и математических функций.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
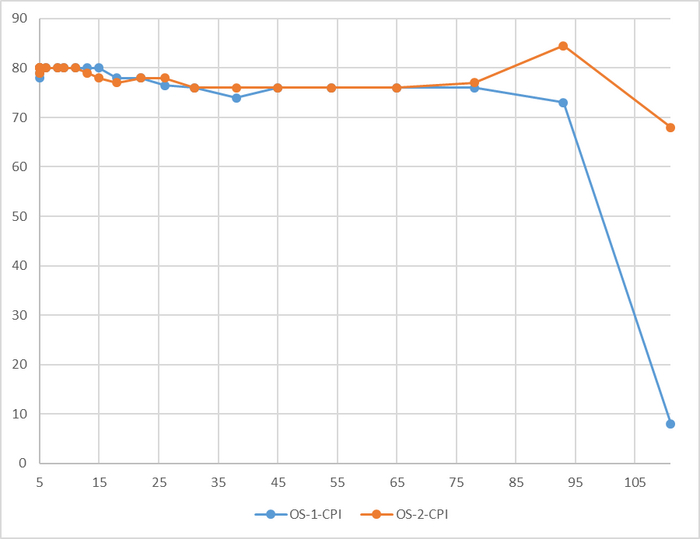
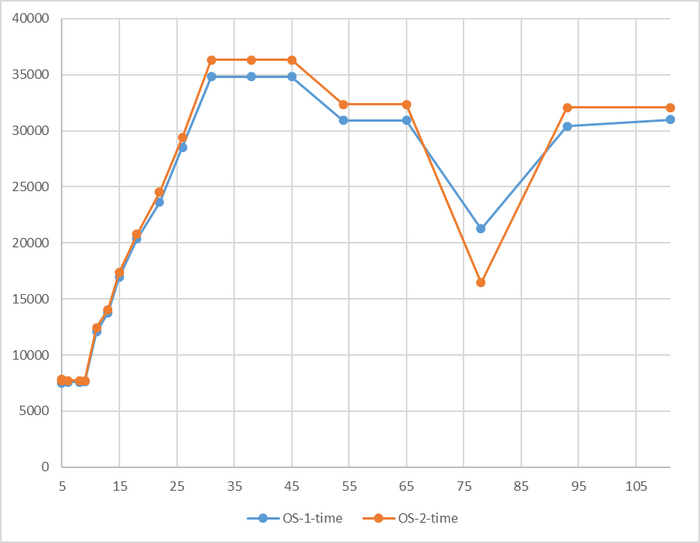
Производительность СУБД
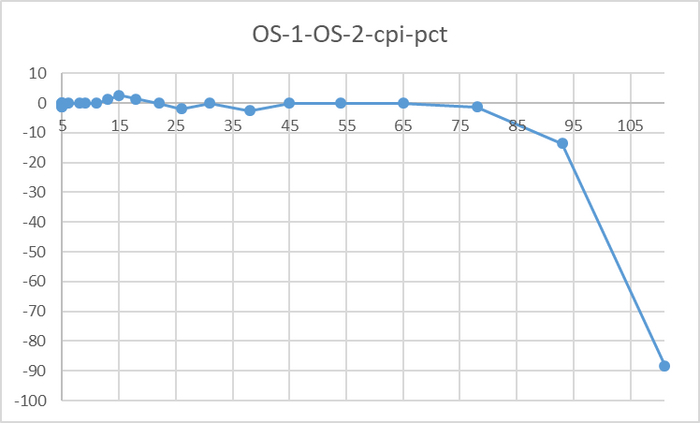
До 78 соединений - разница в производительности не более 3%
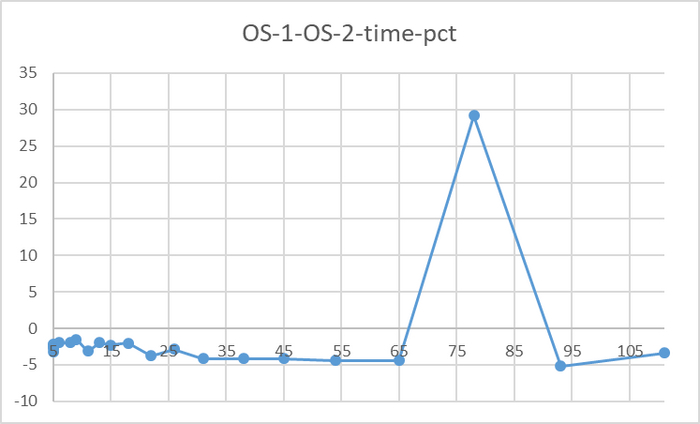
Резкий рост относительной разницы производительности после 76 соединений
До 78 соединений - разница в производительности практически отсутствует.
При высокой нагрузке - OS-2 существенно производительнее.
Время выполнения тестового запроса
Явная аномалия в районе 78 соединений
Имеется аномалия значений
За исключением аномалии при 78 соединений, относительная разница времени выполнения не превышает 5%.
Итог
Для сценария "Heavyweight", при нагрузке свыше 78 сессий - производительность СУБД развернутой на ОС Linux версии OS-2 превосходит производительность СУБД развернутой на ОС Linux версии OS-1 более чем на 10%.
P.S. Аномальное значение при 78 сессиях нуждается в повторном эксперименте.
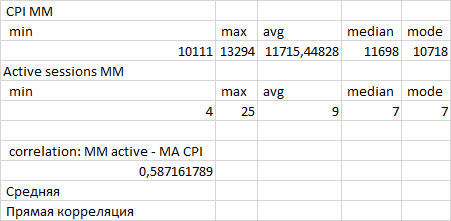
Прямая корреляция между количество активных сессий и производительностью СУБД . Или другими словами - чем выше нагрузка на СУБД , тем выше производительность.
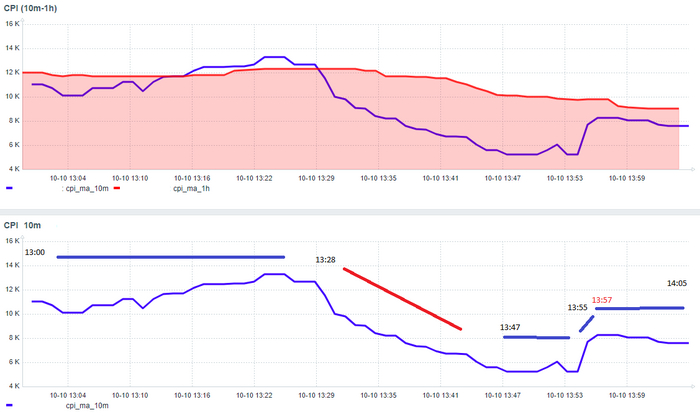
Статистические показатели ожиданий СУБД - корреляция ожиданий и производительности СУБД
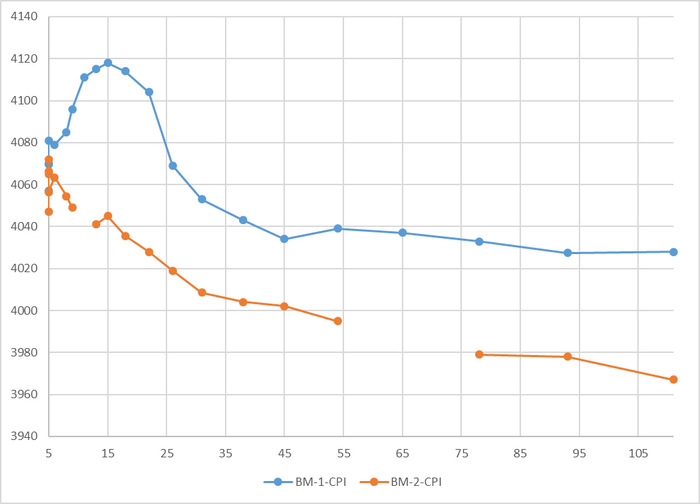
Рис.2. Корреляционный анализ ожиданий и производительности 13:00-13:28
Количество пользовательских запросов по которым имеются события ожидания СУБД - минимально.
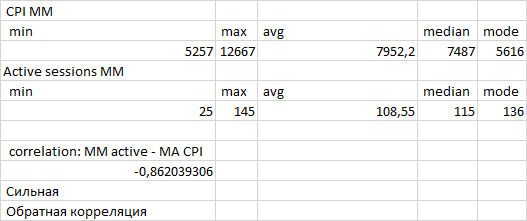
Сильная обратная корреляция - чем выше нагрузка на СУБД тем ниже производительность. Явный признак инцидента производительности СУБД
Статистические показатели ожиданий СУБД - корреляция ожиданий и производительности СУБД
Рис.4. Корреляционный анализ ожиданий и производительности СУБД нисходящего тренда 13:28 - 13:47
Как видно из таблицы - количество ожиданий кардинально увеличилось. Явный признак - имеются серьезные проблемы с производительностью СУБД.
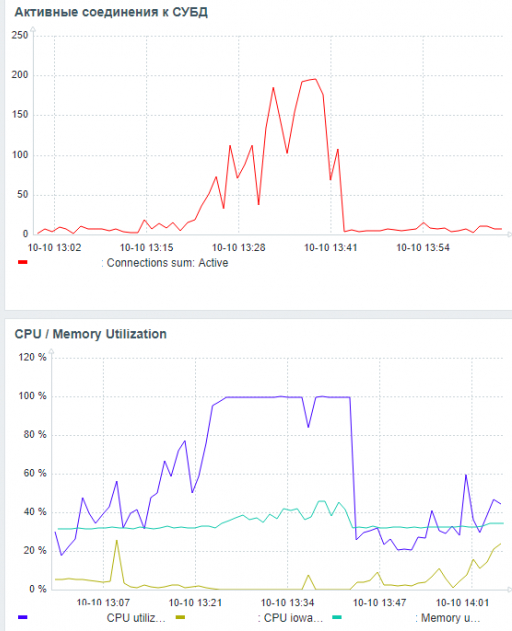
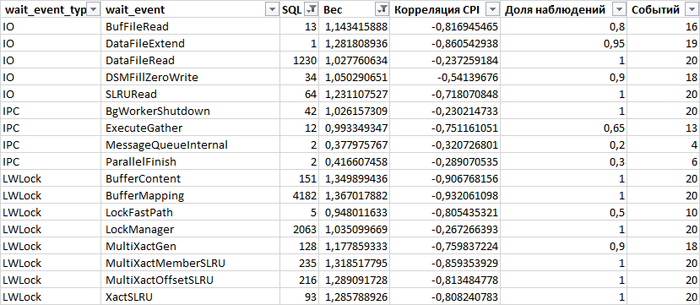
2.Определение наиболее значимой причины деградации производительности СУБД
Из Рис.4 видно, что наибольшая обратная корреляция между событиями ожидания и снижением производительности СУБД имеется для события LWLock / BufferMapping
Рис.5. Ожидание LWLock / BufferMapping
Как видно - количество ожиданий менее чем за 20 минут - весьма существенно.
Итак, первый результат
Первой( но конечно не единственной) причиной деградации производительности СУБД в период 13:28 - 13:47 является - большое количество ожиданий LWLock / BufferMapping при выполнении пользовательских запросов.
Чуть подробнее об ожидании BufferMapping
Ожидание при связывании блока данных с буфером в пуле буферов.
This event occurs when a session is waiting to associate a data block with a buffer in the shared buffer pool.
Context
The shared buffer pool is an PostgreSQL memory area that holds all pages that are or were being used by processes. When a process needs a page, it reads the page into the shared buffer pool. The shared_buffers parameter sets the shared buffer size and reserves a memory area to store the table and index pages. If you change this parameter, make sure to restart the database. For more information, see Shared Buffer Area.
The buffer_mapping wait event occurs in the following scenarios:
A process searches the buffer table for a page and acquires a shared buffer mapping lock.
A process loads a page into the buffer pool and acquires an exclusive buffer mapping lock.
A process removes a page from the pool and acquires an exclusive buffer mapping lock.
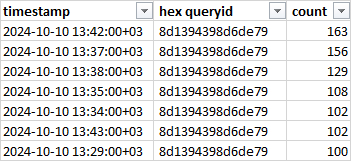
3. Определение запросов с максимальным количество ожиданий
Рис.6. Запросы с ожиданием LWLock / BufferMapping c количество более 100.
Далее, дело техники, используя утилиту pgpro_pwr по queryid, находим проблемный запрос за период 13:30 - 13:50(снимки pgpro_pwr формируются каждые 10 минут).
Запрос передается разработчикам , для анализа .
Дальнейшие события ожидания анализируются схожим образом. Если отсортировать таблицу Рис.4. по количеству пользовательских запросов(более 100) , то можно и нужно сформировать список проблемных запросов для передачи группе разработки на оптимизацию и доработку.
Рис.7. Список ожиданий отсортированный по количеству пользовательских запросов.
Итог
Статистический анализ производительности СУБД позволяет подтвердить наличие деградации производительности не дожидаясь деградации на уровне приложения.
Корреляционный анализ ожиданий и производительности СУБД позволяет быстрее определить корневую причину снижения производительности СУБД и определить список проблемных пользовательских запросов.
P.S.
В настоящее время ведутся работы по разработке и тестированию новой версии инструментария по мониторингу и анализу производительности СУБД PostgreSQL - "Орешник".
Методология статистического анализа производительности СУБД PostgreSQL будет довольно существенно дополнена и доработана.
Часть 2 - Сценарий нагрузочного тестирования "OLTP"
Выбирай сердцем
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "OLTP"
Тестовый запрос состоит только из выражений SELECT - UPDATE.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
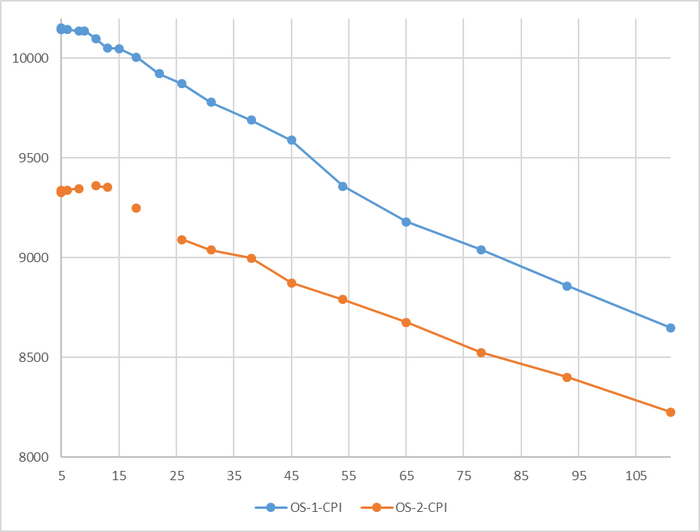
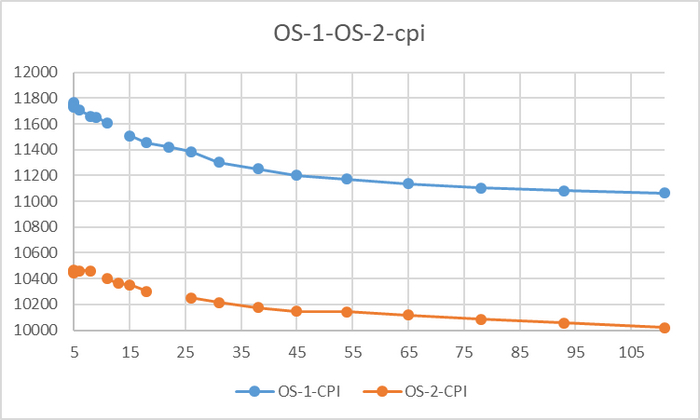
Производительность СУБД
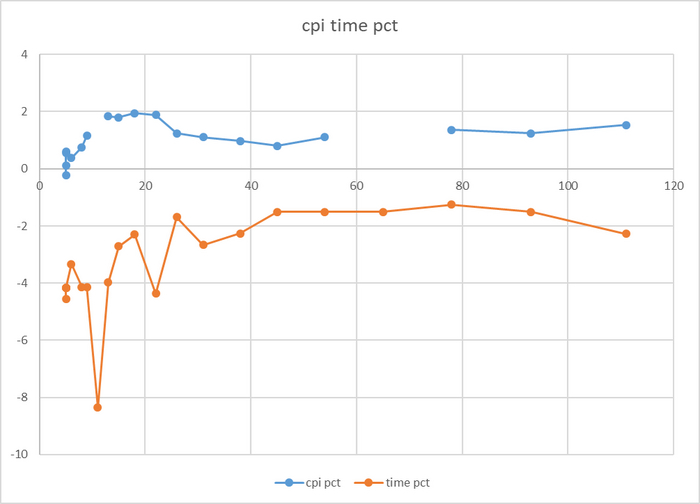
Разница производительности от 5-9%
Относительная разница производительности OS-1 и OS-2
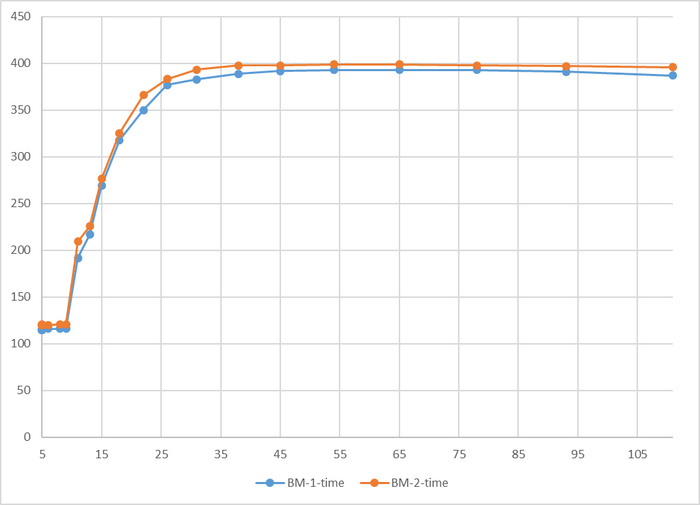
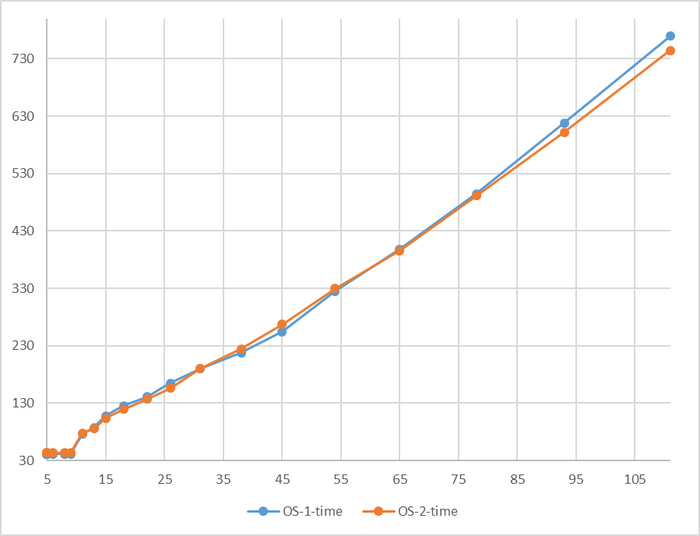
Время выполнения тестового запроса
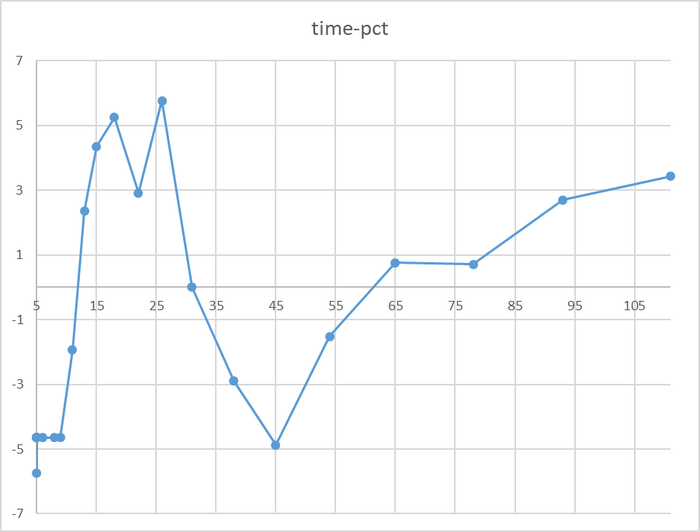
Разница времени выполнения тестового запроса от -5% до 7%
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "OLTP", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 на 5-9% .
Часть 1 - сценарий нагрузочного тестирования "Select only"
Какой Linux выбрать ?
Задача эксперимента
Необходимо провести количественный анализ влияния версии Linux на производительность СУБД для разных дистрибутивов Linux : OS-1 и OS-2 .
СУБД расположены на разных виртуальных машинах. Гипервизор - один. Конфигурация файловых систем - одинаковая. Ресурсы хоста - одинаковые.
Сценарий "Select only"
Тестовые запрос состоит только из выражения SELECT.
Все блоки использующиеся в запросе - находятся в распределенной области.
Для создания нагрузки используется pgbench.
Количество сессий к СУБД растет экспоненциально для каждого прохода теста.
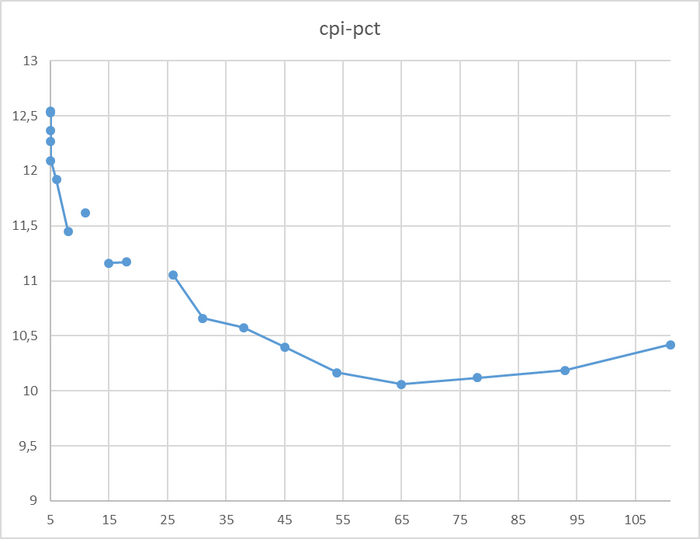
Производительность СУБД
Разница производительности от 10 до 13%
Относительная разница производительности OS-1 и OS-2
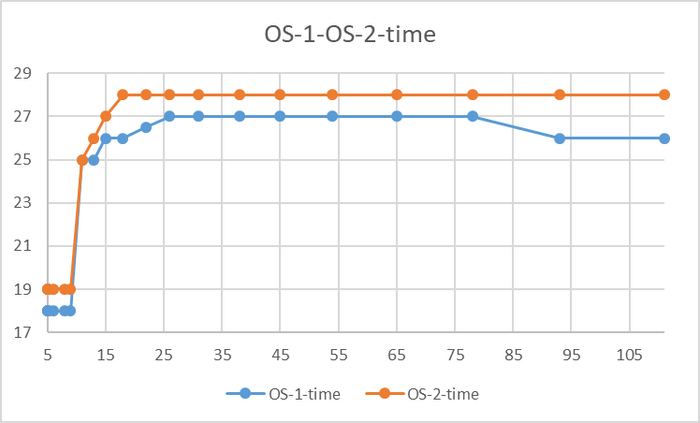
Время выполнения тестового запроса
Разница времени выполнения тестового запроса до 7%
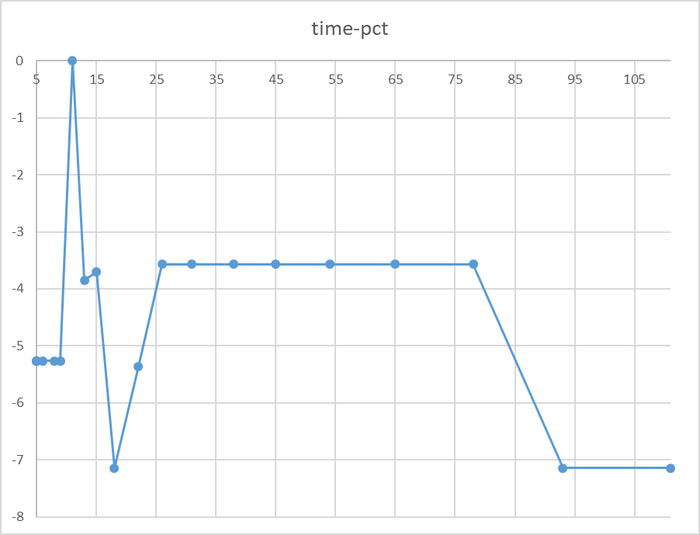
Относительная разница времени выполнения тестового запроса
Итог
Для сценария "Select only", при нагрузке до 111 сессий - производительность СУБД развернутой на ОС Linux версии OS-1 превосходит производительность СУБД развернутой на ОС Linux версии OS-2 не менее чем на 10% .