

Почему переводчикам в ближайшие годы можно не опасаться машинного интеллекта, или на что не способны современные нейросети. Часть I - теория
В последние несколько лет в связи со значительными успехами, достигнутыми искусственным интеллектом в областях, которые ещё недавно считались безраздельной вотчиной человека (раскрашивание черно-белых фотографий, обработка фотографий в стиле того или иного художника, ведение воздушного боя, вождение автомобиля без водителя, расчет оптимальных по расходу материала конструктивных узлов, состязание на равных с чемпионами го и телевизионного конкурса Jeopardy «Своя игра») в широких слоях населения набирает силу мнение, согласно которому ещё немного – какие-нибудь 5-10, максимум 15 лет – и под натиском компьютера падут рубежи крепости, которая остается для него неприступной более 60 лет, а именно – машина наконец-то овладеет ремеслом перевода и сможет выдавать тексты на уровне как минимум среднего, а то и хорошего переводчика.
Короче говоря, если вы задумали стать переводчиком и готовитесь поступать в институт иностранных языков – выкиньте эту пустую затею из головы, потому что когда вы этот самый иняз закончите, вместо переводчиков в бюро переводов будут стоять ряды аккуратных никелированных терминалов с прошивками на нейросетях. Красота - пришёл, сунул флэшку (или какой носитель к тому времени будет в ходу), нажал кнопку, получил перевод. В условиях нынешней компьютерной вакханалии, когда про грядущую в результате натиска роботов безработицу сказали все – от Обамы до Жириновского – это поистине кошмарная перспектива для переводчиков и заветная мечта для всех остальных людей, изнемогающих от обилия языков :-) Так что же – не пора ли нынешним переводчикам поискать себе новое занятие?

Этот вопрос мы и попробуем разобрать в данном посте. Но сразу следует отметить вот что: если мы не придерживаемся идеалистических взглядов, согласно которым мозг – это якобы нечто большее, чем совокупность молекул, организованных в ряд иерархических систем, образующих конечный автомат, который действует в полном согласии с законами физики, химии и теории информации, то надо сразу откинуть идею, что хороший перевод – это нечто такое, что машине не будет по силам никогда. С материалистической точки зрения никакой грани между человеческим мозгом и любым другим конечным автоматом, доступным для изготовления человеком, кроме уровня сложности, не существует. Вопрос не в том, появится ли когда-нибудь хороший машинный переводчик (по аналогии: хороший машинный программист, хороший машинный врач… - никаких технических ограничений здесь нет, только технологические, так что это лишь вопрос времени), а в том, реализуемо ли его создание с использованием тех систем «слабого» машинного интеллекта, - в том числе и на базе нейросетей – которые имеются в нашем распоряжении сейчас и благодаря которым компьютер обошел человека, в частности, в игре го и симуляции воздушного боя?
Мой ответ – однозначно нет. Причина кроется в том, что решение задачи перевода в общем виде на пару порядков сложнее, чем нахождение выигрышной последовательности действий в том или ином виде деятельности, которые можно охарактеризовать как «игра с полной информацией», и не найдено человечеством до сих пор, причем есть все основания считать, что в ряде случаев задача нерешаема принципиально. Поэтому для достижения результатов, сопоставимых с человеческими, компьютер должен обладать и сопоставимой с человеком интеллектуальной мощностью. Однако обо всем по порядку.
Для начала немного заглянем в прошлое. Когда в середине 1950-х годов были впервые начаты серьёзные работы в области машинного перевода, считалось, что в свете достигнутых на тот момент вычислительных мощностей» компьютеров, воспринимавшихся как нечто невообразимое, автоматизация данного вида деятельности – дело десятилетия-другого. В этом, кстати, нынешнее положение дел зеркально отражает имевшее место на тот момент – только сейчас надежды возлагаются на «чудо-нейросети», а тогда – на «чудо-компьютеры» (об этой параллели мы еще поговорим ниже). Перевод в большинстве случаев воспринимался только и исключительно как сопоставление словаря и правил грамматики языка A словарю и правилам грамматики языка B, а все сложности в представлении создателей первых систем машинного перевода сводились к тому, чтобы ввести в компьютер достаточно полный словарь и достаточно полно описать грамматики обоих языков, а также набор правил для их сопоставления – короче говоря, подход был примерно таким же, как к созданию шахматных программ. Все остальное считалось делом техники.
Прошли годы, за ними десятилетия. Вычислительные мощности и объемы памяти компьютеров выросли на порядки, многократно увеличился объем «забитых» на машинные носители словарей и изощренность правил сопоставления синтаксиса. Обескураживающим был лишь результат. Несмотря на все впечатляющие достижения прогресса, качество перевода, достигнув определенного уровня, практически не росло и уже в конце 1960-х годов большинству создателей подобных систем стало ясно, что «механический» лексико-грамматический подход к машинному переводу ведёт в тупик, что ни наращивание мощностей, ни совершенствование алгоритмов в качество перевода не конвертируются. К середине 1970-х это стало прописной истиной, что отразилось в закрытии множества подобных проектов как бесперспективных.
Потерпев поражение в «лобовой атаке», создатели программ-переводчиков открыли для себя то, о чем давно предупреждали мыслители и философы: что язык – нечто большее, чем простая совокупность словаря и грамматики, что смысл текста – любого текста – лежит вне самого текста и без понимания этого смысла говорить о качественном переводе не приходится, а приходится лишь говорить о более-менее точной имитации этой деятельности.
Конечно, с точки зрения достижения заданной цели для нас без разницы, что происходит внутри системы, лишь бы она выдавала нужный результат, а имитация это или нет – дело десятое. Шахматный компьютер не думает, как человек, однако он выигрывает у человека в шахматы. Увы, к переводу подобное оказалось неприменимо. Процитирую отрывок из «Суммы технологии» Станислава Лема, который сумел увидеть проблему во всей её полноте ещё 50 лет назад:
«Неимоверно трудоемкие структурные исследования указывают на то, что каждый микроскопический шаг на пути улучшения качества примитивных машинных переводов должен быть куплен ценой непропорционально огромного усложнения применяемых алгоритмических структур. Одно дело – запрограммировать большую цифровую машину так, чтобы она переводила фразы типа «Там стоит стул», «Падает снег», «Дети идут в школу», и совсем иное – создать программу, с помощью которой машина может перевести фразу вроде следующей: «Первичный способ преподнесения объекта включает “изоляцию” объекта не только в смысле ограниченности, но также и в том смысле, что объект лишь “извне” доступен для познающего субъекта, каковой при этом в едином акте постигает его как целое либо же только предвосхищает». Перевод этой фразы «без понимания вообще» представляется невозможным. Человеку, который захочет ее перевести, надлежит изучать не синтаксис, а скорее феноменологистские журналы. И он наверняка не сможет «схватить» их стиль ни в каком алгоритме, дающем перевод хотя бы с некоторым приближением к оригиналу».
Потерпев поражение с попытками подступиться к переводу с классическими детерминированными алгоритмами, создатели машинных переводчиков не отступились и пошли в атаку, вооружившись статистическими методами, когда перевод осуществляется на базе сопоставления большого количества текстов на исходном языке и языке перевода. Свой подлинный расцвет эти методы пережили после развития сети Интернет и создания огромных сопоставительных баз данных, хранящихся в недрах поисковых машин. Гугл- и Яндекс-переводчики, сумевшие в определенной степени повысить качество перевода за счет комбинации алгоритмического подхода с гигантскими сопоставительными базами, известны нынче каждому… как, увы, и фраза «Только не гуглоперевод», практически в обязательном порядке сопровождающая любой запрос на перевод на неспециализированном ресурсе (на специализированном про подобное никому и в голову не придет упоминать). Несмотря на то, что статистические переводчики стали немалым подспорьем тем, кому нужно быстро понять смысл большого объема текста на иностранном языке, качественного прорыва они обеспечить не смогли. Почему? Станислав Лем своим прозорливым взором сумел предвосхитить ответ и на этой вопрос:
Короче говоря: пособие для перевода – не догма, а руководство к действию. Два совершенно разных перевода могут быть признаны адекватными в зависимости от поставленной задачи, которая опять же проистекает из контекста, не сводящегося к тому или иному тексту.
И здесь исключительно важный момент: абсолютно те же самые рассуждения Лема применимы и к критике машинных переводчиков следующего поколения, которые «работают на нейросетях». Ключевой логической ошибкой тех, кто рассматривает нынешние нейросети как золотой ключик к переводам качественно нового уровня, заключается смешивание суждений «Нам неважно, как именно компьютер делает перевод - главное, чтобы нас устраивал результат» и «Мы не знаем точно, как нейросети будут делать перевод, потому что их работа не сводится к детерминированным алгоритмам», из чего получается «Мы не знаем точно, как нейросети будут делать перевод - главное, чтобы нас устраивал результат», причем почему-то подразумевается, что если нейросеть является для нас «черным ящиком», то результат будет нас устраивать, как устраивает он нас для многих других задач вроде модификации нейросетями фотографий "под картины Дали" или "под картины Шагала" – но применительно к переводу это как раз под очень большим вопросом. Вопрос вычленения смысла, как незначительный, здесь даже не ставится – ровно потому, что авторы подобных рассуждений, даже если они это на словах отрицают, неявно руководствуются некоторым «принципом биективного отображения», согласно которому возможно либо абсолютно однозначное соответствие по смыслу текстов на языках A и B, либо как минимум стремление к этому соответствию. Соответственно, «натравив» на тот или иной текст нейросеть (предварительно обработавшую некий большой массив параллельных текстов на двух языках), в которой прописана некая целевая функция, мы якобы получим в итоге определенный перевод хорошего уровня, удовлетворяющий этой целевой функции наподобие того, как получаются «обработанные нейросетью» оптимизированные по расходу материала конструктивные узлы, выглядящие как инопланетные конструкции.

Оставляя в стороне вопрос о том, нужны ли нам тексты переводов, выглядящие как инопланетный язык (отмечу только, что при таком подходе в получении подобного результата после работы нейросети не будет абсолютно ничего удивительного), мы сталкиваемся с тем, что «биективный подход», основанный на асимптотическом приближении к идеалу, к переводу, как верно замечает Лем, неприменим по причине отсутствия этого самого идеала. Поэтому, на мой взгляд, не будет чрезмерно пессимистичным следующее утверждение: без качественного скачка мощности, который требуется для перехода к пониманию смысла текста (для чего требуется как минимум наличие созданных человеком или самой нейросетью хранилищ данных со огромным количеством перекрестных связей + умение их обрабатывать) нынешние нейросети не выдадут ничего принципиально иного по сравнению с уже использующимися статистическими алгоритмами того же Гугла.
Потому что в чём, собственно, будет заключаться разница между нейросетями и статистическими методами, если и те, и другие будут заниматься исключительно тем, что сопоставлять огромные массивы параллельных текстов, только для статметодов сопоставление будет проводиться по правилам, заданным человеком, а нейросети смогут выработать свои собственные, неведомые нам и пусть даже просто чудовищные по эффективности методы сопоставления текстов, которые останутся нам неизвестными? Ведь в обоих случаях речь будет идти только о их механическом сопоставлении вне анализа той «почвы», откуда эти самые тексты «растут», и тут уже заложенная в нейросети вычислительная мощность не играет практически никакой роли, как не играла она её при переводе лексико-грамматическим методом.
Собственно, выше я упомянул про параллель между надеждами на «чудо-компьютеры» и «чудо-нейросети» с разницей в 50-60 лет. По идее, развитие техник перевода в этом плане должно идти в плане повышения степени «надсистемности» анализируемого информационного субстрата: 1) тексты – 2) массивы текстов (из которых берут начало все тексты) – 3) большая часть знаний, накопленных человечеством (потенциальный источник бесконечного количества текстов и массивов текстов), в виде единой структурированной базы данных с инструментарием для вычленения перекрестных связей. А поскольку нынешние нейросети, как и статметоды, остановились на втором уровне, качественного прорыва тут пока что не ожидается.
Кто-то, разумеется, вспомнит знаменитый «Watson», который сумел одолеть признанных чемпионов «Своей игры», причем умел анализировать вопросы, заданные на естественном языке, и вопросы такого рода, ответы на которые простым «поиском в Гугле» не найти. Вот только у компьютера «Watson» перекрестная база данных, о которой шла речь выше, как раз имелась – и составлена она была под руководством человека. Вопрос о создании подобных баз силами исключительно нейросетей (та работа по познанию мира, которую выполняет человеческий мозг, начиная с младенчества) на уровне нынешних вычислительных мощностей пока что, насколько мне известно, пока что не стоит.
Но вернёмся к теме «целевой функции нейросети» применительно к переводу. Кто-то может возразить: хорошо, перевод не является биективным отображением, но что мешает задать определенные параметры, которые позволяли получать перевод с теми или иными заданными критериями? Скажем, как в пресловутом "Промте" можно было задавать специализацию текста (компьютеры, авиация, нефтяная отрасль...) Задали одни критерии – получили такой-то перевод, другие – другой - скажем, так:
Перевод 66 сонета Шекспира.
1. Параметр «Пастернак» - 100%.
Измучась всем, я умереть хочу.
Тоска смотреть, как мается бедняк,
И как шутя живётся богачу,
И доверять, и попадать впросак…
2. Параметр «блатная феня» 100%.
Достатый в пень, готов я жать на стоп:
Мне жить в ломы, где пашут за ништяк;
Где мазу держит оборзевший жлоб,
Круть обувает влёгкую хиляк.
3. Параметр «Пастернак» 50%, параметр «блатная феня» 50%.
Измучась всем, я умереть готов.
Тоска смотреть, как мается бедняк,
Как мазу держит оборзевший жлоб,
Круть обувает влёгкую хиляк.
Что называется – «вы меня поняли». Увы, но попытка обойти проблему отсутствия биективности перевода умным словосочетанием «задание необходимых параметров» - пока что не более чем бессмысленное сотрясение воздуха. Ни копирование строчек из Пастернака в той или иной последовательности, ни даже копирование характерных для поэта синтаксических структур – не есть стихи Пастернака, это не более чем повод в очередной раз посмеяться над туповатым роботом, выдающим очередные "Яндекс-стихи". Проблема заключается в следующем: чтобы качественно формализовать, к примеру, параметр «Пастернак», нам надо, чтобы наша нейросеть умела воспринимать этот самый подаваемый на вход параметр как всю совокупность стоящих за ним смыслов, что означает, что нейросеть «понимает», что такое «Пастернак». Для этого ей необходимо знать о его жизни, о его эпохе, о его литературном воспитании, а это всё требует других перекрестных связей, в итоге приходим к условию, обозначенному выше: в нейросеть нужно загнать на «доступном для понимания» уровне чуть ли не всю историю человечества, что на нынышнем этапе развития абсолютно нереально.
Для того, чтобы дополнительно пояснить всё вышесказанное, я приведу список из 5 уровней эквивалентности исходного и переведенного текстов, которые выделяют некоторые теоретики перевода:
1. Уровень языковых знаков.
The bicycle was sold for 100 dollars. - Велосипед был продан за 100 долларов.
В этом типе эквивалентности сохраняется все, от цели коммуникации и смысла сообщения до синтаксиса и лексических единиц. Это максимально возможный уровень эквивалентности, но встречается он крайне редко.
2. Уровень структуры высказывания.
He is the best man to lead the party. - Он - лучший, кто может возглавить партию.
Здесь сохраняется все вышеперечисленное, включая часть синтаксических структур оригинала, но эквивалентности на уровне лексических единиц нет (man to lead the party - кто может возглавить партию).
3. Уровень высказывания.
Drinking makes me sick. - От выпивки меня тошнит.
В данном случае сохраняется цель коммуникации, описывается та же ситуация и сохраняются общие понятия, с помощью которых данная ситуация обозначена в оригинале, хотя ни синтаксис, ни лексика с использованными в оригинале не совпадают.
4. Уровень описания ситуации.
You have my ear! - Слушаю вас!
Break a leg! - Ни пуха ни пера!
В данном случае языковые средства оригинала и перевода несопоставимы, но отражают одну и ту же ситуацию, "покрываемую" соответствующим языковым шаблоном.
5. Уровень цели коммуникации (прагматический).
I live on the second floor. - Езжайте-езжайте! (Реплика человека, который проходит мимо другого человека, который придерживает лифт).
Цель коммуникации здесь заключается в доведении до собеседника информации, что ему не нужно держать лифт. Цель достигнута, хотя между высказываниями в оригинале и переводе нет абсолютно ничего общего.
Всё это было сказано вот к чему: отличие хорошего переводчика (не того, кто сидит со словарём и калькирует оригинал) от компьютерного заключается в том, что вне зависимости от того, насколько точно синтаксис исходного высказывания может совпадать с синтаксисом перевода, первым делом переводчик-человек строит для себя «иерархию перевода», начиная с высшего, пятого уровня (в каком контексте происходит действие?), через промежуточную стадию уровней 4 и 3 (что происходит?) спускаясь ниже на уровни соответствия синтаксических структур 2 и 1, и если синтаксис исходного высказывания не совпадает с тем, который построил у себя в голове переводчик – тем хуже для этого самого исходного синтаксиса.
Схема работы переводчика-человека:
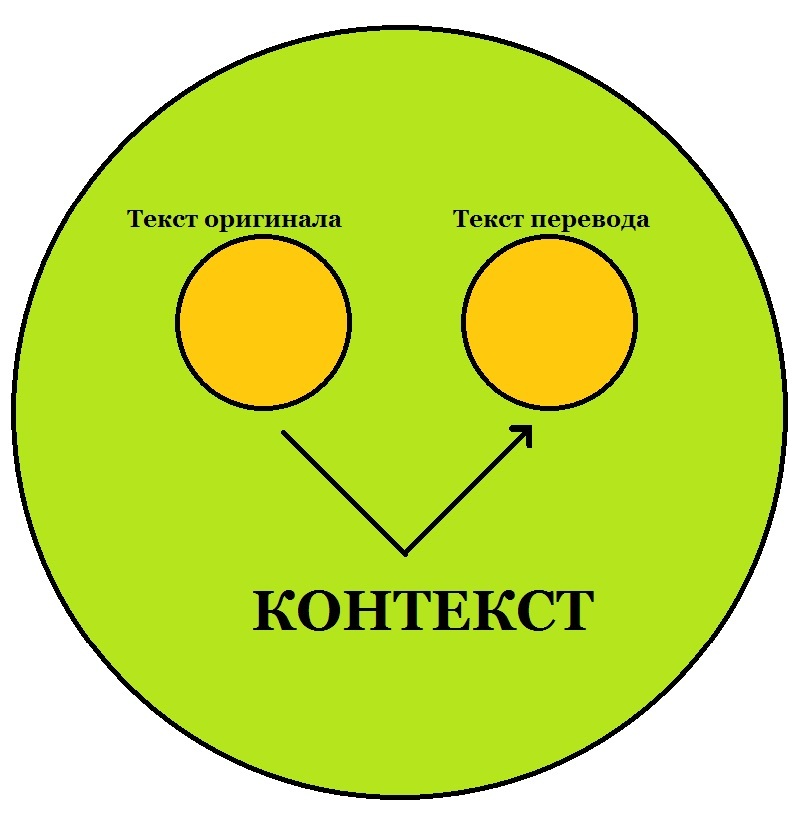
Компьютерные же переводчики, для которых уровень 5 пока что недостижим (причём перевод на уровнях 3 и 4 осуществим по большей части только на основе статистических методов), начинают идти в противоположном направлении - «снизу вверх». Это примерно то же самое, что разобрать на части, скажем, собранный из детского конструктора экскаватор на гайки, болты и пластины, а потом пробовать собрать из него что-то, что нам и самим непонятно, но что мы видели ранее на десятках просмотренных ранее чертежей конструктора (а там и кран, и автомобиль, и паровоз, и чего только нет). Но функции крана, автомобиля или паровоза не выводятся из свойств гаек, болтов и пластин, и если нам непонятно, ЧТО мы хотим собрать (применительно к переводу – отсутствие понимания смысла), то тупое подражание непонятно чему и даст на выходе непонятно что – и не кран, и не автомобиль, и не паровоз, и не экскаватор. Хороший же машинный переводчик будущего должен действовать аналогично человеку – воссоздавая смысл высказывания, спускаться с верхних уровней к нижним. Пока что до этого нам очень далеко.
Думаю, всего сказанного выше достаточно для понимания того, насколько сложен тот процесс, который в представлении некоторых энтузиастов машинного перевода так легко и просто отдать на откуп нейросетям, которые якобы завалят нас качественными переводами, просто-напросто как следует проанализировав огромный массив параллельных текстов.
В заключение рассмотрим примеры того, что гарантированно "сломает зубы" любому машинному переводчику, не достигшему уровня сильного ИИ. Список мог бы быть много больше, но думаю, что и этих примеров будем достаточно. Начнём с того, что и человеку даётся с большим трудом - тексты, перевод которых представляет собой в чистом виде творчество, а далее, спускаясь по уровням, покажем, что нетривиальной задачей для машинного переводчика могут оказаться и совершенно нетворческие тексты технического характера.
Однако этот "разбор полётов" пойдёт уже в следующем посте. Хотелось всё разместить в одном, но, к сожалению, пост оказался слишком большим и Пикабу его не пропустил. Так что
Окончание следует...
P.S. Если всё изложенное выше всё равно не убедило каких-то энтузиастов машинного перевода, у которых возникли возражения в духе "Автор просто не понимает, о чем говорит - все эти проблемы решаемы в ближайшие 5-10 лет, поскольку 1), 2), 3)..." - приглашаю высказываться в комментариях, ну или подождать окончания с примерами, после чтения которого станет ясно, что не всё так просто :-)
Перевод и переводчики
1.4K поста8.2K подписчика
Правила сообщества
В переводных постах обязательна ссылка на оригинал или прикрепленная картинка с оригиналом!
Разрешается:
- делиться интересными статьями, переводами, локализациями;
- просить о помощи с переводами;
- презентовать свою критику и предложения по исправлению перевода в постах.
Запрещается:
- создавать посты без ссылки на оригинал или картинки с источником;
- оскорблять комментаторов и ТС;
- создавать посты рекламного характера;
- создавать посты, не относящиеся к тематике.
Конструктивная критика приветствуется при наличии предлагаемых альтернативных вариантов перевода. Попытки провокаций будут пресекаться.