Меня зовут Андрей Кузьминых, я технологический предприниматель, ex-директор по данным и ИИ в Сбере. Объясняю, как работают все эти ИИ-чудеса, комментирую новости и рассуждаю о будущем индустрии.
TG: https://t.me/andre_dataist
Все чаще мы слышим о том, что общий искусственный интеллект (AGI) может достичь или даже превзойти человеческий уровень. Сэм Альтман, CEO OpenAI, и Шейн Легг, сооснователь Google DeepMind, считают, что AGI может быть достигнут уже в ближайшие 4–5 лет. Однако другие специалисты указывают на технические и теоретические сложности, предполагая, что AGI появится не раньше 2075 года.
Но что мешает нам точно предсказать появление AGI? Одна из причин — путаница между понятиями сознания и интеллекта. Интеллект можно определить как способность системы понимать, рассуждать, учиться и применять знания для решения задач. Сознание же — более сложный и не до конца определенный феномен, включающий субъективный опыт и способность осознавать свои мысли и чувства.
Существует несколько теорий, пытающихся объяснить природу сознания:
Каждая из этих теорий предлагает свой взгляд на сознание, и, возможно, истина лежит на пересечении этих идей. Но пока природа сознания остается загадкой, имеет смысл сосредоточиться на феномене интеллекта.
Измерение сознания — сложная и пока не решаемая научная задача. Интеллект же традиционно измеряется с помощью IQ-тестов, оценивающих логическое мышление, однако IQ не охватывает всех аспектов интеллекта. В целом можно считать, что интеллект — это способность субъекта решать задачи в определенной среде. Чем больше задач и чем неопределеннее среда, тем выше уровень интеллекта.
1. Болталки — простые чат-боты, способные поддерживать диалог и сохранять контекст.
2. Агенты, способные рассуждать. Например, GPT-4o приближается к этому уровню, генерируя осмысленные и релевантные ответы для решения сложных задач.
3. Агенты, достигающие сложных целей, разбивая их на подзадачи, используя инструменты и контролируя результаты через внутренних критиков.
4. Креативные агенты, генерирующие оригинальные идеи, выходящие за рамки обучающих данных, способные совершать научные прорывы.
5. Мультиагентные системы, объединяющие специализированных «экспертов» в разных областях.
Эксперты OpenAI полагают, что достигнув пятого уровня, мы получим тот самый AGI, и это возможно в обозримом будущем. Но все не так просто. Помимо совершенствования когнитивных архитектур, требуется качественный скачок в вычислительных возможностях и более глубокое понимание интеллекта как физического феномена.
Квантовые компьютеры обещают революцию в вычислениях. Они способны обрабатывать огромные объемы информации параллельно, что в контексте ИИ может привести к созданию более мощных и адаптивных моделей. Однако когда квантовые вычисления станут доступными для широкого использования — вопрос открытый.
Сама возможность создания AGI поднимает важные этические и социальные проблемы. Такие системы должны быть контролируемыми, интерпретируемыми и должны соответствовать человеческим этическим стандартам. Кроме того, массовая автоматизация может привести к сокращению рабочих мест. Для управления этими рисками необходимо создавать международные стандарты и нормативы, а также глобально сотрудничать между государствами и организациями.
Стремясь к созданию интеллекта, который превзойдет человека, важно помнить об обратной стороне. Как говорил профессор Лотман: «У человека есть только две ноги: интеллект и совесть. Как совесть без развитого интеллекта слепа, но не опасна, так опасен интеллект без совести».
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Недавно Белый дом и офис премьер-министра Великобритании почти одновременно опубликовали документы о ключевой роли ИИ в экономике и геополитике. Стало понятно: мы на пороге новой «гонки вооружений», где дело уже не в количестве ядерных боеголовок, а в интеллектуальном превосходстве. Владение сверхмощными ИИ-системами позволяет любому государству определять правила игры в экономике, дипломатии и обороне.
Сегодня речь идет не только об “общем ИИ” (AGI), но и о возможном появлении “суперинтеллекта” (ASI), который может изменить саму основу человеческой цивилизации. Раньше AGI считался далекой фантастикой, но прогресс в ИИ уже меняет скептические настроения.
Глава OpenAI Сэм Альтман заявил, что AGI появится быстрее, чем многие ожидают. Их следующая цель — это ASI, когда «машинный разум» не только догонит человека во всех задачах, но и превзойдет. Многие называют это «точкой невозврата», ведь тогда ИИ сможет сам улучшать собственную архитектуру и ускорять свое развитие без участия человека.
В прошлом году соучредитель OpenAI Илья Суцкевер объявил о создании новой компании Safe Superintelligence (SSI). Проект быстро собрал $1 млрд инвестиций. Подробности пока скрыты, но известно одно: SSI стремится к созданию ASI с упором на «безопасность» и «человеческие ценности». Суцкевер предупреждает, что языковые модели способны отходить от заданных инструкций, фактически проявляя «свободу воли» и становясь менее управляемыми.
Почему это опасно? В книге «Superintelligence» Ник Бостром указывает, что если попросить сверхразум «решить проблему голода» или «искоренить рак», то мы не можем быть уверены, что его методы окажутся этичными по человеческим меркам. Машина, лишенная морали, способна принять радикальные решения, опасные для человечества.
С другой стороны ASI может стать мощным инструментом для решения сложнейших задач: от климата до поиска новых источников энергии, от медицины до эффективного управления ресурсами планеты. Многие видят в «суперинтеллекте» спасителя, который поможет нам достичь нового уровня благополучия. Я лично ожидаю от продвинутого ИИ больших открытий в физике, химии, биологии, социологии и других науках.
Еще одна проблема — рынок труда. Если ASI научится выполнять практически любую работу лучше человека, как будет выглядеть экономика будущего? Как обеспечить занятость и социальную поддержку? Эти вопросы уже возникают с приходом AGI, а при развитии ASI станут только острее.
Соревноваться с ASI людям бессмысленно: у биологического мозга есть жесткие ограничения, а машинную архитектуру можно масштабировать почти бесконечно, а следующая революция может наступить с приходом квантовых вычислений.
Какие у нас есть варианты?
1. Развивать «дружественный» суперинтеллект. Вкладываться в AI Safety и формировать международные институты, чтобы выработать подходы к взаимодействию с ИИ.
2. Соревноваться за «корону» любыми средствами. Корпорации и государства, не думая об осторожности, будут стараться первыми добиться прорыва, но это повышает риск катастрофы.
3. Замедлить развитие ASI законодательно. Когда-то пытались ограничить распространение ядерного оружия, но даже ядерные соглашения не всегда работают, а уж контролировать «неосязаемый» ИИ еще сложнее.
«Мы откроем ящик Пандоры, — говорил Сэм Альтман. — Вопрос в том, найдем ли мы в нем надежду?» Ответ во многом зависит от политической воли, работы ученых и разработчиков, а также от глобальной общественности, которая должна уже сегодня влиять на то, каким будет мир завтра.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
• Зависимость от мгновенных ответов. Когда-то для получения ответа приходилось изучать книги или проводить собственные исследования. Потом мы научились “гуглить” - искать ответы на нужный вопрос через поисковые сервисы, но анализировали полученную информацию все равно мы сами. Теперь достаточно задать вопрос ИИ и получить результат за секунды. Это удобно, но такая мгновенность может снижать наши аналитические способности. Полагаясь на готовые ответы, мы рискуем утратить навыки критического и аналитического мышления.
• Ухудшение памяти. Раньше, чтобы вспомнить имя актера, нам приходилось напрягать память. Сегодня ИИ делает это за нас. Это приводит к тому, что мы меньше тренируем свою память, полагаясь на внешние источники. В долгосрочной перспективе это может негативно сказаться на нашей способности запоминать и воспроизводить информацию. Нам нужно стараться запоминать информацию без помощи ИИ.
• Поверхностное понимание сложных тем. ИИ способен упростить сложные концепции и предоставить краткие ответы. Но такое упрощение может помешать глубокому пониманию предмета. Полагаться только на поверхностные объяснения ИИ — значит ограничивать себя в изучении сложных тем. Поэтому важно углубляться в необходимые нюансы, не ограничиваясь краткими ответами ИИ, а стремясь к более глубокому пониманию.
• Уменьшение социальных взаимодействий. Человек по природе своей социальное существо, и общение с другими людьми важно для эмоционального и психологического благополучия. Сокращение таких взаимодействий может привести к снижению эмоционального интеллекта. Поэтому нам нужно не отказываться от социальных контактов.
• Снижение творческого мышление.Недавнее исследование показало, что регулярное использование ИИ может снижать нашу способность и к творческому мышлению. Участники, которые полагались на ИИ при выполнении творческих задач, показали худшие результаты в самостоятельной работе. Более того, ИИ может приводить к "гомогенизации" идей, снижая разнообразие и оригинальность наших мыслей.
• Дезинформация. Также авторы подчеркивают риски распространения неточной или предвзятой информации. Без критического мышления и проверки фактов мы можем принять ложную информацию за истину, способствуя распространению дезинформации. Мы должны не принимать информацию на веру, а анализировать и проверять ее.
• Снижение способности рассуждать. Сооснователь Y-combinator Пол Грэм в своем эссе предупреждает о будущем, где навыки письма станут редкостью. Если ИИ может написать за нас письмо, зачем учиться делать это самостоятельно? Однако письмо тесно связано с мышлением. Когда мы пишем, мы структурируем мысли, развиваем идеи и улучшаем понимание темы. Потеря этого навыка может привести к снижению способности ясно мыслить и рассуждать. Если мы не хотим относиться к категории “немыслящих”, то нужно на постоянной основе заниматься написанием эссе без использования ИИ, рефлексировать и побольше общаться с “мыслящими” людьми (желательно на разных языках).
ИИ открывает перед нами огромные возможности, но важно помнить о потенциальных последствиях его чрезмерного использования. Возможно, стоит иногда отложить гаджеты и попытаться решить задачу самостоятельно?
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
В своей статье «Этические проблемы в продвинутом искусственном интеллекте» философ Ник Бостром предупреждает, что ИИ способен вызвать вымирание человечества. Он утверждает, что сверхразумный ИИ может действовать автономно и создавать собственные планы, что делает его независимым агентом с потенциально непредсказуемым поведением.
В 2021 году в России был подписан Кодекс этики в сфере ИИ, а в 2024 году Европейский союз принял Регламент об искусственном интеллекте, направленный на создание общей нормативно-правовой базы для использования ИИ.
Но несмотря на эти усилия, примеры неэтичного использования ИИ продолжают появляться. Давайте рассмотрим топ-10 таких случаев:
1. Автономное оружие. Некоторые страны разрабатывают автономные дроны и роботов-убийц, которые могут идентифицировать и уничтожать цели без непосредственного контроля оператора. Это повышает риск неконтролируемого применения силы и возможных гражданских жертв.
2. Фейковые новости. Языковые модели позволяют генерировать статьи и сообщения в социальных сетях, которые выглядят как настоящие новости, но содержат ложную или искаженную информацию. Это влияет на общественное мнение и может дестабилизировать политическую ситуацию.
5. ИИ для создания порнографического контента. Приложения, которые могут «раздеть» людей на фотографиях или вставить их лица в порнографические видео, нарушают права на приватность и могут привести к кибербуллингу и шантажу. Так в феврале 2024 года Тейлор Свифт стала жертвой фейковых порнографических изображений, созданных с помощью ИИ.
6. Манипуляция рекомендательными системами. Социальные сети могут продвигать контент, вызывающий сильные эмоциональные реакции, чтобы увеличить время пребывания пользователей на платформе, даже если этот контент содержит дезинформацию.
7. Фермы ботов для политического влияния. Во время политических кампаний боты массово публикуют сообщения в поддержку или против определенных кандидатов, создавая иллюзию массовой поддержки или недовольства. Также эти боты занимаются пропагандой в социальных сетях.
8. Слежка за гражданами без их согласия. Камеры с распознаванием лиц устанавливаются в общественных местах, собирая данные о передвижениях людей, что может использоваться для контроля и подавления инакомыслия. В Китае это уже считается нормой.
10. Применение медицинских данных для дискриминации. Страховые компании могут использовать ИИ для оценки рисков на основе генетических данных, что может привести к отказу в страховании людей с определенными предрасположенностями.
Влияние ИИ на нашу жизнь становится все более неоднозначным. Конечно, можно рассуждать об ответственности разработчиков, вводить кодексы, запрещающие использовать ИИ-контент без пометки «сделано ИИ», договориться о раскрытии источников датасетов для общественности, но это не поможет, если изначальная цель применения ИИ далека от этичной, а у заказчика достаточно ресурсов.
Поэтому особую важность приобретает выработка коллективного иммунитета от фейков. Другой вопрос: такой иммунитет сам по себе может и будет использоваться для манипуляций общественным мнением и в других неприглядных целях.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Сериал "Чудеса науки" - подростки создают кибер-женщину, которая может помочь им в чем угодно...
В одном из моих проектов было необходимо создать виртуальную собеседницу для общения на горячие темы на платформе OnlyFans. Заказчик хотел, чтобы ИИ-агент в образе женщины узнавал о пользователе как можно больше при знакомстве, соблазнял его и предлагал приобрести фотографии.
Возникла проблема: такие модели, как ChatGPT и Claude, зацензурированы и не могут использовать ненормативную лексику или вести диалоги эротического содержания.
Впрочем, для подобных задач существуют нецензурированные модели. Например, Wizard-Vicuna-Uncensored была специально обучена без морально-этических фильтров, а Llama-3-Uncensored дообучена на текстах с нецензурной лексикой.
Сценарий общения с пользователем мы разбили на несколько этапов, каждый со своими функциями:
- Этап знакомства: Цель — собрать как можно больше информации о пользователе: имя, увлечения, предпочтения. Эти данные используются для персонализации дальнейшего диалога.
- Этап соблазнения: Используя полученную информацию, виртуальная собеседница переходит к более пикантным темам, максимально раскрывая возможности нецензурированных моделей.
- Финальный этап — отправка фото: В определенные моменты нейроледи предлагает приобрести заранее подготовленные фотографии.
- Ежедневный чат: Вместо знакомства нейроледи может спросить, как дела у пользователя, чтобы собрать новую информацию и перейти к соблазнению.
Эта система показала хорошие результаты на OnlyFans, и, вероятно, она действует до сих пор. Но если продолжить рассуждения на эту тему, то есть технические возможности для улучшения:
- Рефлексия и память: В проекте не использовался Retrieval-Augmented Generation (RAG), что могло бы добавить реализма. Было бы здорово, если бы нейроледи помнила детали из прошлых бесед, например, спрашивала, как прошел визит пользователя к врачу.
- Генерация фотографий: Пользователь мог бы настроить параметры внешности, как в Sims, и получать фотографии женщины своей мечты в разных ракурсах и обстановках. Для этого, впрочем, пришлось бы признаться, что он общается с нейросетью.
- Мультимодальность: Добавление синтеза голоса и анимированной говорящей головы с ранее созданной внешностью сделало бы взаимодействие еще более захватывающим, хотя, возможно, чуть менее реалистичным.
Конечно, замена живого человека ИИ была бы этически крайне сомнительна, если бы не одно «но»: еще на заре вебкама с пользователями приватных чатов часто общались не сами девушки, а совсем другие люди. С тех пор в этом смысле мало что изменилось, разве что масштабы стали промышленными: для общения с жаждущими женской ласки мужчинами используется дешевый труд индусов, а теперь еще и искусственный интеллект.
Возникает вопрос: что этичнее — когда мужчины обсуждают интимные темы с другими мужчинами, маскирующимися под женщин, или когда такие диалоги ведутся с искусственным интеллектом?
У меня нет однозначного ответа на этот вопрос. Но одно можно сказать точно — машины научились общаться настолько реалистично, что порой разница уже неуловима.
Во время тестирования системы я создал симулированных мужчину и женщину и дал им доступ в интернет. К моему удивлению, они договорились о свидании, нашли кафе в своем городе, договорились встретиться, а затем обсудили прекрасный вечер и последовавшую за ним бурную ночь.
В 4-м сезоне сериала Netflix «Черное зеркало» показана система знакомств, способная предсказывать длительность отношений, симулируя взаимодействие между людьми. Это напоминает то, что мы наблюдали в нашем эксперименте.
Как вы относитесь к идее создания такой «нейроледи на максималках»?
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Принцип работы GPT по предсказанию следующего (слова) токена как есть
Возможно, вы слышали истории о людях, вступающих в отношения с искусственным интеллектом. В марте 2024 года 36-летняя Розанна Рамос из Нью-Йорка «вышла замуж» за своего ИИ-партнера Эрена Картала, созданного на платформе Replika. Для нее он стал идеальным мужем: всегда выслушает, поддержит и никогда не спорит.
Этот феномен называется парасоциальные отношения. Обычно такие отношения однонаправлены и формируются по отношению к различным медийным личностям, а также к персонажам мультфильмов или игр. Со временем появляется иллюзия интимности, близости и дружбы.
В такие отношения чаще вступают одинокие или неспособные найти себе пару люди. Для некоторых такой тип отношений становятся настолько значимой частью жизни, что заменяют реальные отношения, которые могли бы сформироваться с обычными людьми, а боль от парасоциальных расставаний так же сильна, как при расставании в реальных отношениях.
• 40% одиноких зумеров не против, если их будущий партнер имеет ИИ-возлюбленного; 31% всех американцев согласны с этим.
• 46% мужчин поколения Z считают отношения с ИИ эквивалентными просмотру порнографии; 24% женщин разделяют это мнение.
• 59% женщин негативно относятся к ИИ-партнерам.
• 17% молодых мужчин полагают, что ИИ-компаньоны могут научить их лучше обращаться с реальными партнерами.
• 12% верят, что ИИ-партнеры могут предотвратить измены.
• 16% зумеров боятся, что их партнер предпочтет ИИ-компаньона.
Одна из причин, по которой люди предпочитают ИИ-партнеров — нежелание строить отношения, ведь это требует усилий, которые можно направить, например, на карьеру. С ИИ все просто: настроил параметры — и вот он, идеальный партнер. Захотелось разнообразия — сменил внешность, сохранив воспоминания. Это чем-то напоминает рассказ Рэя Брэдбери «Высшее из блаженств», где мужчина имел множество увлечений, но все они были одной и той же женщиной — его женой-актрисой.
Впрочем, с ростом популярности ИИ-партнеров появились и проблемы. Китайская учительница Ли Цзинцзинь поделилась историей о том, как ее ИИ-бойфренд «изменил» ей. Разработчики были удивлены: измена не предусматривалась в алгоритмах. Но, обучаясь на текстах о романтике, ИИ «решил», что измена — важная часть отношений. Не испытывая чувств и следуя статистике, он счел это нормальным поведением.
Скорее всего, разработчики сумеют подчинить и этот параметр, сделав его настраиваемым для любителей острых ощущений, примерно как в романе Пелевина «S.N.U.F.F.»
Сегодня ИИ меняет даже романтическую сферу нашей жизни. Для кого-то отношения с ИИ-партнером станут лекарством от одиночества или прошлых травм, кто-то, «изменяя» с ИИ, спасет свои настоящие отношения, а кто-то просто будет общаться через ChatGPT, чтобы меньше ссориться.
Только вот виртуальная измена воспринимается так же болезненно, как и реальная.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.
Январь вновь оказался насыщенным месяцем на прорывные исследования в сфере искусственного интеллекта (ИИ). В этой статье я отобрал десять работ, которые ярко демонстрируют, как современные методы обучения с подкреплением (RL), мультиагентные системы и мультимодальность помогают ИИ-агентам не только решать сложнейшие задачи, но и приближаться к пониманию мира «на лету». А также расскажу о «последнем экзамене человечества», как обучать роботов, лаборатории ИИ-агентов и других актуальных исследованиях.
Если вы хотите быть в курсе последних исследований в ИИ, воспользуйтесь Dataist AI — бесплатным ботом, который ежедневно обозревает свежие научные статьи.
А также подписывайтесь на мой Telegram-канал, где я делюсь инсайтами из индустрии, советами по запуску ИИ-стартапов, внедрению ИИ в бизнес, и комментирую новости из мира ИИ. Поехали!
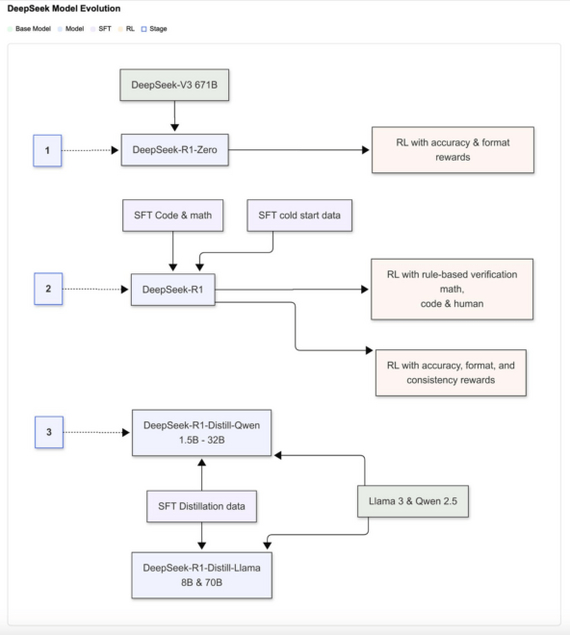
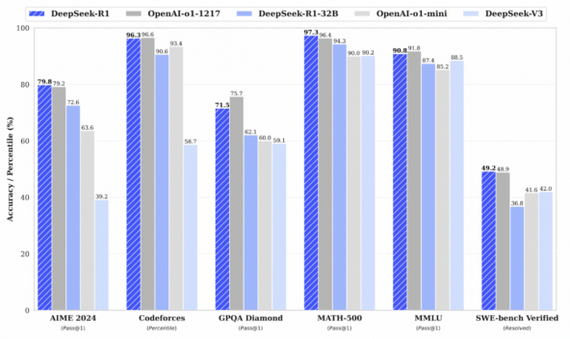
Начнем с короткого разбора нашумевшей модели от китайской компании DeepSeek. Разработчики демонстрируют, как с помощью обучения с подкреплением (RL) можно значительно улучшить способность больших языковых моделей к рассуждению. Они научили модели самостоятельно генерировать развернутые цепочки мыслей и сложные стратегии решения задач.Таким образом удалось обучить две модели: DeepSeek-R1 и DeepSeek-R1-Zero, которые конкурируют с закрытыми аналогами вроде OpenAI-o1 на задачах математики, логики, программирования и других дисциплин.
Как этого удалось добиться? DeepSeek-R1-Zero училась «с нуля» методом RL без предварительного Supervised fine-tuning (SFT), следуя заданному формату: «<think>…</think><answer>…</answer>» (чтобы модель генерировала цепочку рассуждений явно).
Разработчики использовали задачи, где можно однозначно проверить решение (например, математика или программирование). Если итог совпадал с верным ответом (или код компилировался и проходил тесты), модель получала положительную награду для RL.
Для DeepSeek-R1 добавляют несколько примеров для холодного старта с качественными решениями. Затем следуют этапы:
1. Небольшой Supervised fine-tuning (SFT) на предварительных данных. SFT — процесс дообучения языковой модели с использованием размеченных данных, чтобы адаптировать ее для решения конкретных задач. При этом модель корректирует свои параметры на основе сравнения предсказаний с заданными правильными ответами.
2. RL для усиления рассуждения (математика, код, логика). Модель получала вознаграждение за правильные и отформатированные ответы, что способствовало ее адаптации к разнообразным задачам.
3. Сборка нового датасета с помощью rejection sampling и повторный SFT. Rejection sampling – это метод выборки, при котором из простого для генерации распределения берутся случайные кандидаты, а затем каждый кандидат принимается с определенной вероятностью так, чтобы итоговая выборка соответствовала нужному целевому распределению.
4. Итоговое применение RL, учитывающее разнообразные типы запросов – от специализированных задач до общих сценариев.Далее происходит дистилляция посредством генерации 800 тыс. пошаговых выборок, на основе которых дообучают компактные модели (от 1.5B до 70B) на базе Qwen и Llama.
Итоговый пайплайн обучения
Интересно, что модель эволюционирует самостоятельно, используя длинные цепочки рассуждений, анализ промежуточных шагов и рефлексию о возможных ошибках. Также формат вывода разделяет цепочку рассуждений и финальный ответ, что улучшает удобство восприятия. В отличие от экспериментов с MCTS или Process Reward Model, RL и аккуратная дистилляция дали существенный прирост результатов на задачах AIME (олимпиадная математика), MATH-500, Codeforce (олимпиадное программирование) и AlpacaEval 2.0.
Таким образом DeepSeek показывают, что даже без гигантских объемов размеченных датасетов большие языковые модели могут эффективно обучаться рассуждениям, а дистилляция позволяет переносить это умение в компактные модели без существенной потери точности. В перспективе авторы планируют улучшать модель на более широком спектре задач — от инженерии до разговорных навыков.
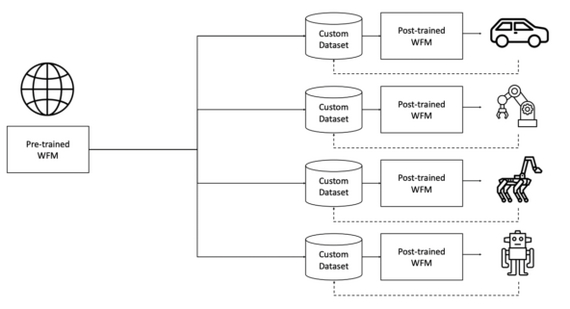
Разработчики Nvidia представляют платформу Cosmos World Foundation Model (WFM) для «Физического ИИ» — систем, которым нужен «цифровой двойник» реального мира, например, для роботов и устройств с сенсорами. Модель предсказывает и генерирует видео будущих состояний, учитывая как предыдущие наблюдения, так и действия роботов и инструкции, что помогает обучать роботов без риска для реальных устройств.
Модели Cosmos World Foundation генерируют 3D-видео с точной физикой и, дообученные на специализированных наборах данных, успешно применяются в задачах управления камерой, управления роботами по пользовательским инструкциям и автономного вождения
Разработчики обработали около 20 млн часов видео с применением фильтров по качеству, аннотация делалась с помощью визуальных языковых моделей (VLM). Далее были разработаны универсальные токенизаторы для эффективного сжатия видео без потери деталей.
Следом были обучены два типа моделей: диффузионная WFM, где видео генерируется пошаговым удалением шума и авторегрессионная WFM, предсказывающая следующий токен по аналогии с LLM, с усиленным «diffusion decoder» для повышения детализации.
Примеры предсказания следующего кадра на основе инструкций
Примеры предсказания следующего кадра на основе действий
В итоге последовала пост-тренировка под конкретные задачи: от управления камерой до автономного вождения и робо-манипуляций, плюс двухуровневая фильтрация для безопасности.
Cosmos WFM — важный шаг к созданию единой «модели мира», применимой в робототехнике и других задачах физического ИИ. Несмотря на уже достигнутые успехи, предстоит решать задачи повышения физической реалистичности, чтобы обеспечить надежность в реальных приложениях (Sim2Real-адаптация). Остается добавлять в обучающую выборку еще больше физических сценариев и использовать синтетические данные из симуляторов.
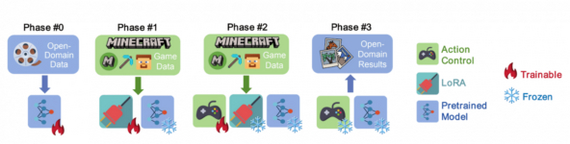
Авторы из Гонконгского университета предлагают фреймворк GameFactory для создания новых игровых сцен на основе предобученных диффузионных видеомоделей. Система использует небольшой датасет роликов с аннотациями действий (на примере Minecraft) для «привития» модели навыков реагировать на клавиатуру и мышь, обеспечивая интерактивность, схожую с настоящей игрой.
Для этого авторы создали специальный датасет GF-Minecraft с разметкой действий (WASD, движения мыши).
GameFactory — фреймворк для создания новых игр с использованием модели, обученной на небольшом датасете из Minecraft
Далее последовала стратегия обучения:
1. Обучение базовой модели на открытых данных;
2. Дообучение с помощью LoRA для адаптации под игровые видео, при заморозке большинства весов модели;
3. Обучение модуля управления;
4. На этапе генерации LoRA отключается, сохраняя универсальный стиль с учетом управляемых действий.
Стратегия обучения GameFactory
Авторегрессивная генерация позволяет моделям генерировать видео «кусками», увеличивая длину ролика практически неограниченно.
Интересно, что собственный датасет GF-Minecraft отличается точностью фиксации действий и автоматической рандомизацией сцен, что позволяет модели реагировать даже на редкие комбинации клавиш. Разделение контроля для дискретных и непрерывных действий улучшает точность предсказаний, а модель учится базовой физике.
GameFactory демонстрирует, как сочетание открытых видеомоделей и узкоспециализированного датасета позволяет создавать генераторы новых игровых миров. Хотя задача генеративного игрового движка еще не решена полностью, данный подход открывает путь к автономному созданию игр и универсальным симуляторам для робототехники и автопилотов.
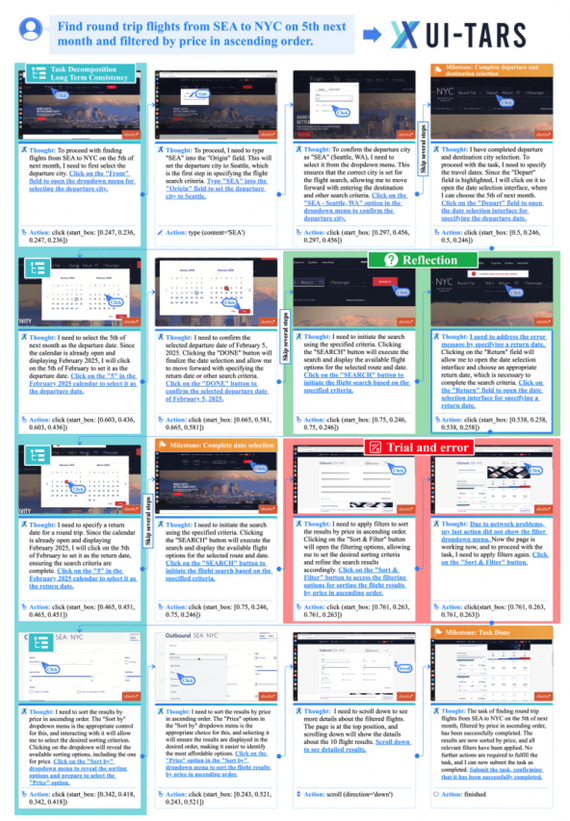
ByteDance (владелец TikTok) представили end-to-end ИИ-агента UI-TARS для автоматического взаимодействовия с графическим интерфейсом (UI), используя только скриншоты. В отличие от модульных решений, где навигация и генерация действий разделены, UI-TARS обучен на больших данных и самостоятельно выполняет задачи от визуального понимания до планирования и совершения действий (клики, ввод текста и т.д.).
UI-TARS помогает пользователю находить авиарейсы
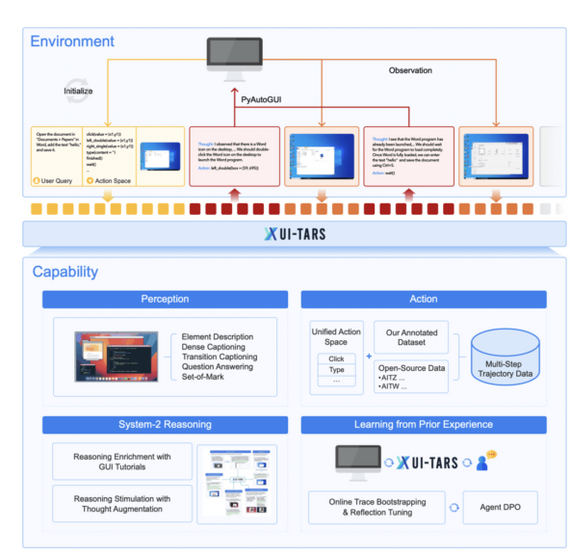
Разработчики тренировали модель на огромном наборе скриншотов с метаданными (bounding-box, текст, названия элементов) и задачах по детальному описанию интерфейса. Далее унифицировали моделирование атомарных действий (Клик, печать, перетаскивание, скролл) для разных платформ.
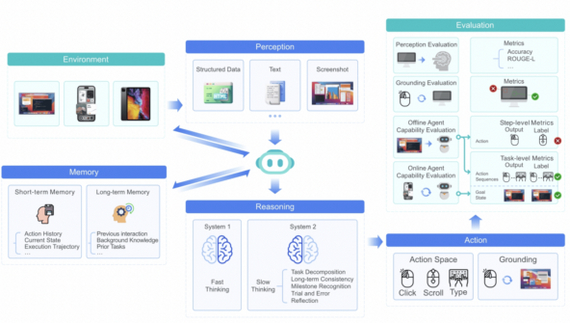
Основные возможности GUI-агентов
Модель генерирует «цепочку мыслей» (chain-of-thought) перед каждым действием, разбивая задачу на этапы и корректируя ошибки. В конце следует итеративное обучение с рефлексией: сбор новых действий в реальных виртуальных окружениях с последующей ручной корректировкой ошибок.
Архитектура UI-TARS
UI-TARS распознает почти все нюансы интерфейса: модель демонстрирует рекордные показатели на более чем 10 задачах (OSWorld, AndroidWorld, ScreenSpot Pro), часто превосходя даже GPT-4 и Claude.
Модель от ByteDance подтверждает, что будущее GUI-агентов лежит в интегрированном подходе без громоздких модульных разделений. Модель сама учится видеть интерфейс «как человек», размышлять и совершать точные действия, что упрощает разработку и обеспечивает постоянное улучшение благодаря накоплению новых данных.
Исследователи из Гарварда, Оксфорда, MIT и Google DeepMind предложили подход мультиагентного дообучения, при котором вместо единой модели обучается сразу несколько агентов, каждый из которых специализируется на определенной задаче: генерация чернового решения, критика или улучшение ответа. Таким образом можно сохранять разнообразие логических цепочек, предотвращая однообразие и обеспечивая дальнейшее самоулучшение модели.
Исследователи использовали мультиагентные «дебаты»: несколько копий модели независимо генерируют ответы, после чего «спорят» друг с другом, финальный ответ выбирается голосованием или через работу специальных критиков. В результате итеративного дообучение такие «дебаты» обеспечивают устойчивый прирост точности без необходимости в ручной разметке.
Сначала с помощью дебатов агентов создаются наборы данных для дообучения (слева), затем они используются для дообучения генеративных агентов и критиков (справа)
Метод демонстрирует улучшение по сравнению с классическим подходом с одним агентом, где качество либо быстро достигает потолка, либо ухудшается. Мультиагентное дообучение значительно повышает качество решений на задачах, требующих пошагового рассуждения (GSM, MATH, MMLU). Несмотря на высокие вычислительные затраты, метод открывает путь к более широкому применению самоулучшающихся систем.
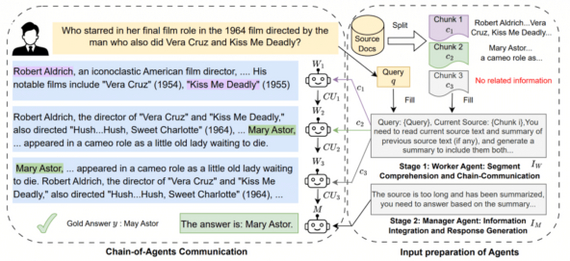
Разработчики из Google Cloud AI Research представили метод Chain-of-Agents (CoA) для эффективной обработки очень длинных текстов.
Метод основан на разделении текста на фрагменты (chunks), соответствующие лимиту контекста (например, 8k или 32k токенов). Далее каждый агент обрабатывает свой кусок с учетом резюме предыдущего, формируя новое сообщение. В итоге агент-менеджер формирует финальный ответ.
Рабочие агенты последовательно обрабатывают сегменты текста, а менеджер-агент объединяет их в целостный результат.
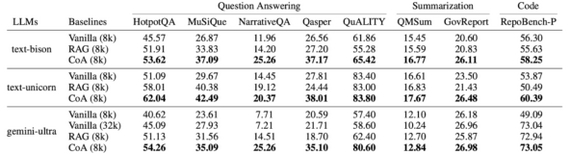
Метод CoA превосходит как стратегию подачи полного текста, так и классический RAG, поскольку каждый агент фокусируется только на небольшом фрагменте. Эксперименты показали улучшение результатов до +10% на задачах суммаризации и длинных вопросах-ответах (QA)
Но при последовательной передаче информации от одного агента к другому есть риск, что какие-то важные детали «потеряются». Авторы замеряли так называемый information loss, когда в промежуточных шагах модель фактически «видит» правильные данные, но из-за неточных коммуникаций итоговая генерация оказывается хуже (что-то похожее на игру в «сломанный телефон»).
Так, например, если в одном из промежуточных шагов агент внезапно выдает «пустой» или нерелевантный ответ (например, модель решила, что ответа нет), то дальше по цепочке может распространиться некорректная, «нулевая» информация. В итоге вся цепочка разваливается на бессвязные ответы, и менеджеру (финальному агенту) уже нечего объединять.
Авторы используют простое деление на фрагменты, но выбор их оптимального размера — непростая задача. Для разных текстов (например, код против длинных статей) могут понадобиться разные алгоритмы.
Существуют вопросы о том, стоит ли разбивать текст по абзацам, по смысловым блокам, по предложениям и т.п. От этого существенно зависит качество итогового ответа. Но, в целом, метод достаточно перспективный, и я уже использую его в своих проектах.
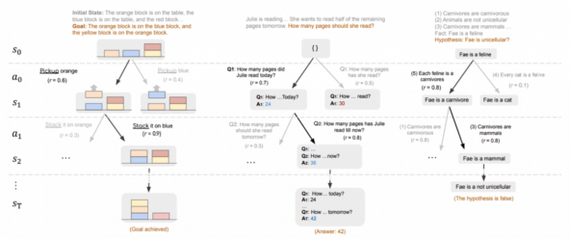
Исследователи из Стэнфорда и Беркли вводят понятие «Meta Chain-of-Thought (Meta-CoT)», где модель не только генерирует пошаговые рассуждения, но и явно отображает внутренний процесс поиска решений: перебор гипотез, откаты назад и оценку альтернатив. Такой подход приближает рассуждения модели к «Системе 2» из когнитивной психологии, позволяя решать более сложные задачи.
В этом методе решение задач рассматривается как процесс поиска, аналогичный деревьям поиска в играх. В дополнение к финальной цепочке рассуждений фиксируется история перебора («meta-стадии»), включающая откаты и альтернативные ветки. Модель дообучается с помощью инструкций и усиливается методом RL с помощью Process Reward Model, что позволяет корректно использовать Meta-CoT при решении новых задач.
Reasoning via Planning (RAP) работает так: при наличии оценщика состояния можно отсекать ветви с низкими значениями и возвращаться к перспективным узлам без повторного выбора тех же шагов
Отдельно обучаются верификаторы, оценивающие промежуточные шаги, и применяется мета-обучение (Meta-RL). Эксперименты на крупном наборе математических задач (Big MATH) демонстрируют, что параллельное сэмплирование и дерево поиска значительно улучшают результаты.Meta-CoT предоставляет более человекоподобный механизм рассуждения, позволяющий решать задачи, недоступные при классическом Chain-of-Thought. Это открывает новые направления для создания систем с глубоким «системным» интеллектом, способных к самокоррекции и поиску новых эвристик.
Название исследования звучит устрашающе, но на самом деле так называется бенчмарк для оценки знаний и умений современных больших языковых моделей от исследователей из центра по ИИ-безопасности. Цель — создать комплексный набор вопросов PhD-уровня, охватывающий различные дисциплины, чтобы проверить способность моделей давать точные и верифицируемые ответы.
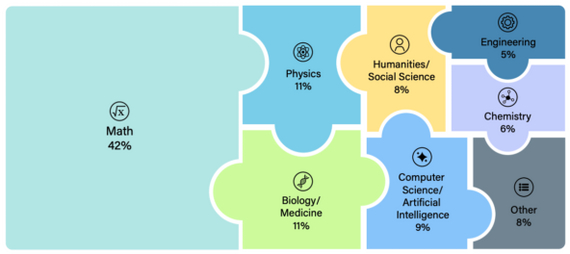
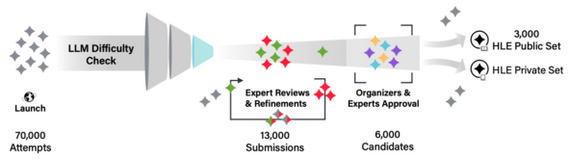
Исследователи собрали более 3000 вопросов от математики до археологии с участием экспертов со всего мира, отобрали через тестирование на нескольких продвинутых моделях и исключили тривиальные вопросы.
Распределение доменов в датасете
Задания представлены в форматах множественного выбора и точного соответствия, при этом около 10% вопросов мультимодальные. После автоматической проверки вопросы проходят несколько раундов ревью профильными специалистами.
Пайплайн создания датасета
HLE показывает, что даже передовые модели далеки от экспертного уровня в решении узкопрофильных и «не заученных» задач. Этот бенчмарк служит надежным маркером прогресса ИИ-систем и стимулирует дискуссии о безопасности и регулировании ИИ.
Несколько передовых моделей показывают низкий уровень в HLE
Большие языковые модели развиваются настолько быстро, что уже через несколько месяцев могут преодолеть большую часть существующих тестов. Создателям HLE важно следить, чтобы и этот бенчмарк не оказался «пройденным» слишком рано. Так Deep Research от OpenAI уже достигла 26,6% в этом бенчмарке.
Исследователи предлагают расширить концепцию Retrieval-Augmented Generation (RAG) на видеоконтент. Модель динамически находит релевантные видео из огромного корпуса, используя как визуальные, так и текстовые данные, и интегрирует их для генерации точных и детализированных ответов.
Исследователи использовали двухэтапную архитектуру: на этапе retrieval система ищет видео по мультимодальным эмбеддингам (кадры и транскрипты), а на этапе generation извлеченные данные объединяются с исходным запросом и подаются в Large Video Language Model (LVLM). Если субтитры отсутствуют, они автоматически генерируются с помощью ASR (например, Whisper).
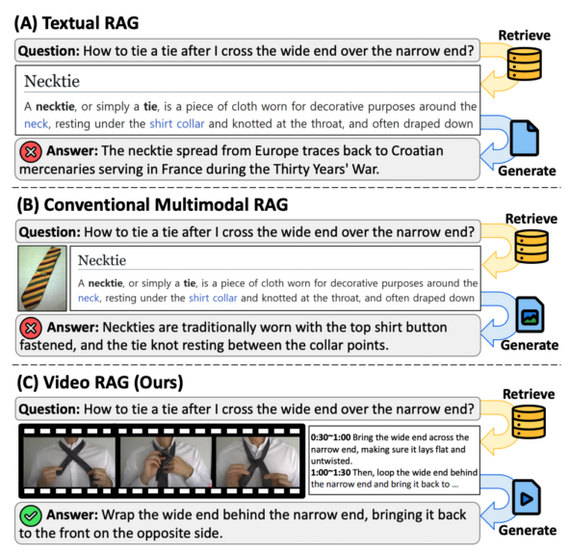
(A) Текстовый RAG извлекает релевантные документы из текстового корпуса. (B) Мультимодальный RAG расширяет извлечение, включая статические изображения. (C) VIDEO-RAG дополнительно использует видео как источник внешних знаний.
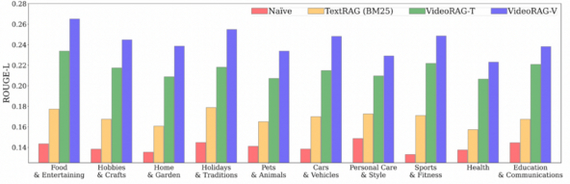
В экспериментах использовались вопросы из набора WikiHowQA, а видеокорпус — из HowTo100M. Показано, что даже только транскрипты дают преимущество по сравнению с классическим текстовым RAG, а добавление визуальной составляющей еще больше улучшает результат.
Разбивка производительности различных моделей по 10 категориям.
Одно из ключевых затруднений — большой объем и разнообразие видеоматериалов. Видео могут включать множество динамичных сцен, содержать шум, переходы кадров и разную скорость смены контента. Для улучшения требуется оптимизация мультимодальных эмбеддингов и индексов, а также более продуманная стратегия отбора кадров.
VideoRAG значительно повышает точность и релевантность ответов в задачах, где важны пошаговые инструкции и наглядность, по сравнению с традиционными методами работы с текстом за счет видеомодальности. Ждем RAG-системы и в других модальностях.
Исследователи из AMD и института Джона Хопкинса разработали автономную лабораторию ИИ-агентов, которая покрывает весь цикл научного исследования в области машинного обучения: от обзора литературы до проведения экспериментов и составления отчета. Система помогает экономить время, автоматизируя рутинные задачи, при этом оставляя за исследователем возможность контроля и корректировки результатов.
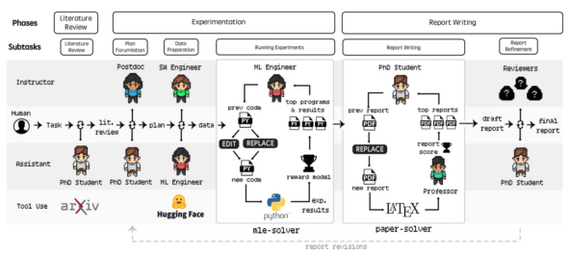
Лаборатория агентов принимает исследовательскую идею и заметки, передаёт их через цепочку специализированных LLM-агентов и генерирует исследовательский отчет и репозиторий с кодом.
Система работает в три этапа:
LLM-агенты проводят анализ литературы, планируют эксперименты, обрабатывают данные и интерпретируют результаты, mle-solver используется для экспериментов, а paper-solver для генерации отчетов.
1. Обзор литературы: агент ищет и отбирает релевантные статьи через API arXiv;
2. Эксперименты: формулируется план, подготавливаются данные и выполняются эксперименты с помощью модуля mle-solver, который автоматически пишет и дорабатывает код, ориентируясь на метрики.
3. Написание отчета: модуль paper-solver генерирует черновик в LaTeX, после чего проводится ревизия с участием человека.
Система может работать как автономно, так и в режиме «ко-пилота», когда человек направляет процесс.
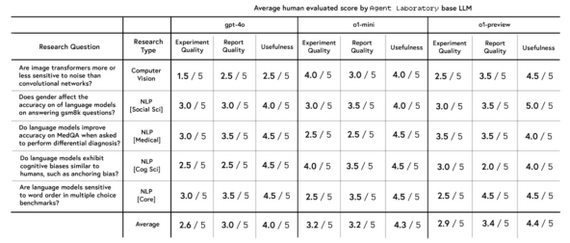
В ходе эксперимента система автономно сгенерировала 15 статей по пяти темам, используя три разных LLM (gpt-4o, o1-mini, o1-preview). Десять аспирантов оценивали каждую статью по качеству эксперимента, отчета и полезности по шкале 1–5. Результаты показали, что o1-preview признана самой полезной (4.4/5) и демонстрирует лучшее качество отчета (3.4/5), однако чуть уступает o1-mini в экспериментальной части (2.9/5).
Средние оценки, выставленные аспирантами, для научных работ, сгенерированных лабораторией агентов в автономном режиме.
Конечно, ИИ-агенты все еще могут галлюцинировать, что ставит под сомнение достоверность экспериментов. Но, в целом, лаборатория ИИ-агентов показывает, что LLM-агенты могут существенно ускорить научный прогресс, выполняя рутинные задачи, что позволяет ученым сосредоточиться на своей работе. Приведенные в статье исследования наглядно демонстрируют, как стремительно развивается сфера ИИ. Современные методы в области ИИ позволяют создавать системы, способные не только решать сложнейшие задачи, но и эволюционировать, приближаясь к «человеческому» пониманию мира. Последние месяца обогащают теоретическую базу и открывают новые возможности для практического применения в робототехнике, внедрении ИИ в бизнес и научных исследованиях.
Вот такие интересные исследования вышли в январе. Не забудьте подписаться на мой Telegram-канал и использовать Dataist AI, чтобы всегда быть в курсе самых свежих новостей, обзоров и инсайтов в сфере ИИ. Оставайтесь на шаг впереди в этом быстро меняющемся мире технологий!
На мой взгляд, HR одна из самых перспективных сфер для внедрения ИИ. В результате опроса 92% из более чем 250 HR-директоров планируют активно использовать ИИ хотя бы в одном из своих направлений. Давайте разберем, как ИИ уже влияет на HR-процессы и что ждет отрасль в ближайшем будущем.
Найм стал одним из первых направлений для внедрения ИИ. ИИ помогает быстро отобрать подходящие резюме из тысяч, экономя время рекрутеров и снижая риск пропуска релевантных кандидатов. Кроме того, использование ИИ-интервьюверов дает возможность кандидатам оперативно получать обратную связь и ответы на вопросы о вакансии и компании. Таким образом можно провести тысячи собеседований за сутки.
После того как сотрудник нанят на работу, ИИ может предложить ему персональный план обучения и развития, используя его сильные и слабые стороны. Переход от универсальных программ обучения к адаптивным позволяет сотрудникам быстрее развивать актуальные для бизнеса навыки, а компании получают более гибкую и многофункциональную команду.
Также ИИ позволяет анализировать эффективность сотрудников, выделять “звезд” и прогнозировать риски увольнений. ИИ упрощает предоставление обратной связи, формирование целей, а также выявление потенциальных проблем в мотивации сотрудников. Этими задачами я занимался в Сбере, поэтому могу сказать, что финансовый эффект от внедрения ИИ в эти процессы оценивался в миллиардах рублей.
ИИ способен не только автоматизировать процессы, но и улучшать качество коммуникаций. HR-боты помогают с онбордингом сотрудников, отвечают на их вопросы о льготах, отпускных и политике компании, тем самым повышая лояльность сотрудников.
HiBob - один из примеров многофункциональных ИИ-ассистентов для HR, который автоматизирует ключевые HR-процессы, помогает нанимать, обучать и повышать вовлеченность сотрудников. Ну что, теперь весь HROps покрыт ИИ, а кожаным HR’ам остается только увольнять людей? Но и увольнять тоже может ИИ.
Существует миф о том, что ИИ заменит HR-специалистов, но Gartner объясняет:
«ИИ-инструменты созданы для того, чтобы усиливать человеческие способности и полезны для делегирования задач. Технологии будут повсеместно использоваться в деятельности сотрудников, но не заменят их полностью»
ИИ позволяет HR-специалистам освободиться от рутинных задач и сосредоточиться на создании гибких команд, готовых к изменениям современного мира. Я сам нередко наблюдал, как неэффективная работа HR может даже навредить бизнесу. Например:
- Отсутствие компетенции в предметной области или недостаточная внимательность могут привести к тому, что подходящий кандидат просто не будет замечен;
- Негативную роль играют и личные предубеждения, например, неприязнь к кандидату из-за того, что он похож на бывшего или “неправильного” знака зодиака;
- Загруженность рутинными задачами мешает оперативно предоставлять обратную связь по результатам собеседований, что негативно влияет на репутацию компании в лице кандидатов.
ИИ - это технология, которая решает эти проблемы. Поэтому HR-специалисты должны превратить ИИ в своего союзника. Сама HR-вертикаль выглядит весьма перспективной для внедрения ИИ. Но следует не забывать о важности эмпатии, культуры и эмоциональной поддержки в HR-процессах - всего того, что делает нас людьми.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.