Что такое векторизация текста в NLP и какая она бывает: One-hot encoding, Bag of words, TF-IDF, Word2Vec, BERT и другие
Привет, Пикабу! Меня зовут Александр Троицкий, я автор канала AI для чайников, и в этой статье я расскажу про разные способы векторизации текстов.
Всем привет! Вдохновившись прикольной и понятной статьей на английском языке, и не найдя сходу чего-то похожего в русскоязычном сегменте интернета, решил написать о том, как обрабатывается текст перед тем, как на нем начинают применять разные модели ИИ. Эту статью я напишу нетехническим языком, потому что сам не технарь и не математик. Надеюсь, что она поможет узнать о NLP тем, кто не сталкивается с AI в продуктах на ежедневной основе.
О чем эта статья:
Что такое векторизация текста и как она развивалась
Зачем она нужна и где применяется
Какие бывают методы векторизации и какие у них преимущества и недостатки
Что такое векторизация (и немного истории)
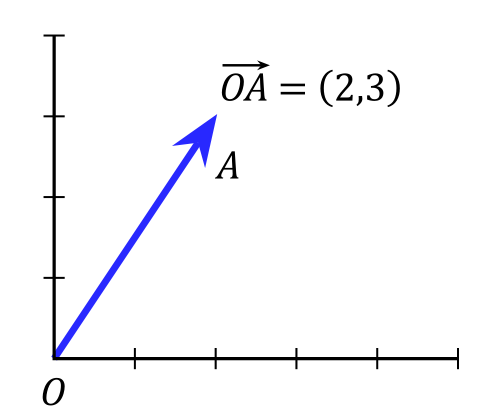
Векторизация текста — это процесс преобразования текста в числовой формат, который могут понимать и обрабатывать алгоритмы машинного обучения. Текстовые данные по своей природе являются категориальными и неструктурированными, из-за этого обучать модели ИИ прямо на тексте - нельзя, их надо векторизовать.
Векторизация текста как концепция начала развиваться после Второй Мировой войны и использовалась в основном для поиска информации и перевода текста.
Один из ключевых моментов в развитии технологии векторизации текста — создание модели векторного пространства (vector space model, VSM) в 1970-х годах, которая позволяла представлять текстовые документы как векторы в многомерном пространстве. Эта модель стала основой для многих методов информационного поиска и начала использоваться для анализа и сравнения документов.
С появлением интернета и увеличением доступных текстовых данных в 1990-х и 2000-х годах, интерес к векторизации текста и развитию методов NLP значительно вырос. Это привело к разработке более продвинутых методов, таких как TF-IDF (Term Frequency-Inverse Document Frequency), который позволяет лучше учитывать контекст и семантическое значение слов.
Почти все современные векторайзеры текста были изобретены внутри компании Google - это Word2Vec и BERT. Они умеют преобразовывать слова в цифры, которые отлично описывают значения и контекст использования этих слов.
Где применяются векторайзеры?
Ответ простой - почти везде, где текст встречается с ИИ. У всех текстовых моделей есть так называемые "тело" и "голова". Если говорить очень упрощённо, то тело - это векторизация, а голова - это обучение какой-то модели на результатах тела.
Именно поэтому векторайзеры очень важны - чем лучше вы передадите суть слова в числовом выражении, тем лучше потом обучится модель.
Если говорить о бизнес применении, то вот небольшой список из примеров где используется NLP, а значит и векторизация:
Анализ настроений и обработка отзывов клиентов: Компании анализируют отзывы и комментарии клиентов в социальных сетях, на форумах и сайтах отзывов для понимания их настроений по отношению к продуктам, услугам или бренду. Это помогает улучшить качество обслуживания и адаптировать продукты под нужды потребителей.
Системы рекомендаций: Векторизация текста используется для анализа предпочтений пользователей и их интересов на основе их поисковых запросов, просмотренного контента и написанных отзывов. Это позволяет создавать персонализированные рекомендации, например, в онлайн-ритейле или на стриминговых сервисах.
Классификация и сортировка документов: Векторизация текста применяется для автоматизации классификации и сортировки больших объемов документов, таких как электронные письма, договоры или резюме.
Поисковые системы и SEO: Поисковые алгоритмы используют векторизацию текста для улучшения релевантности и точности результатов поиска.
Чат-боты и виртуальные ассистенты: Векторизация текста лежит в основе разработки чат-ботов и виртуальных ассистентов, которые используются в обслуживании клиентов, автоматизации ответов на частые вопросы и в ведении персонализированных диалогов.
Анализ рынка и конкурентной среды: Компании используют векторизацию для мониторинга новостей, публикаций и отчетов конкурентов для получения ценной информации о рыночных тенденциях и стратегиях конкурентов.
Предотвращение мошенничества и безопасность: Векторизация текста используется в алгоритмах для распознавания подозрительных сообщений, фишинговых писем или недобросовестной рекламы, что помогает защитить бизнес и клиентов от мошенничества.
Разбираемся в том какие бывают методы векторизации текста
Давайте попробуем на примерах разобраться в том, как работают разные методы векторизации на примере двух предложений:
Лодка села на мель
Девушка села на стул
One-hot encoding
Самый просто и примитивный метод, результатом которого является матрица с единицами и нулями внутри. 1 говорит о том, что какой-то текстовый элемент встречается в предложении (или документе). 0 говорит о том, что элемент не встречается в предложении. Давайте разберемся на примере двух предложений выше:
Сначала нужно получить список всех слов, встречаемых в наших предложениях. В нашем случае это ['Лодка', 'Девушка', 'села', 'на', 'мель', 'стул']
Составляем матрицы для каждого предложения.


Собственно эти матрицы - это и есть векторизованное значение этих предложений. Как вы видите, чтобы описать всего 4 слова, у нас получились довольно большие и разряженные матрицы (разряженные значит, что внутри больше нулей, чем единиц). Каждая такая матрица занимает много места, поэтому для больших текстов этот метод становится неэффективным.
Кроме того, метод не описывает:
Как часто встречается слово.
Контекст этого слова.
Bag of words
По сути это тот же самый one-hot encoding, но тут матрицы схлопываются и каждое предложение будет представлять из себя одну строку, а не большую матрицу. Таким образом Bag of words имеет те же минусы, что one-hot encoding, но занимает меньше места. Чтобы получить Bag of words можно сложить столбики каждой матрицы из one-hot encoding в одну строку, получится:

TF-IDF
TF-IDF - это уже более сложная штука, чем bag of words или one-hot encoding, но всё еще относится к тому, что можно описать простой экселькой. Состоит этот метод векторизации из двух компонентов: Term Frequency (частотность слова в документе) и Inverse Document Frequency (инверсия частоты документа). В TF-IDF редкие слова и слова, которые встречаются в большинстве документов (в нашем случае предложений), несут мало информации, а значит им дается небольшой вес внутри вектора.
TF-IDF = TF * IDF
TF = количество раз когда слово встретилось в предложении или документе / количество слов (токенов) в предложении или документе
IDF = натуральный логарифм от количества документов деленное на количество документов с каким-то словом.
Давайте разберем пример с нашими двумя предложениями:

И в итоге получаем векторы у каждого предложения. В данном примере метод посчитал слова "Лодка", "мель" значимыми в первом предложении, и слова "Девушка", "стул" значимыми во втором преложении. Словам "села", "на" был присвоен нулевой вес, потому что они встречались в обоих предложениях.

Как я писал ранее, этот метод векторизации всё ещё считается относительно простым. Применять его можно как baseline при решении какой-то NLP задачи, а также для простых задач бинарной классификации. Например, он вполне может подойти для поиска негатива в отзывах. Также у TF-IDF есть настраиваемые параметры длины анализируемой части предложения и вместо слов "Девушка" и "села" можно сразу искать в тексте словосочетание "Девушка села", тогда TF-IDF будет худо-бедно воспринимать контекст. Но все равно базово он воспринимает контекст хуже, чем методы векторизации, о которых мы будем говорить далее.
Word Embeddings (Word2Vec)
Word2Vec - это изобретение компании Google, которое представили широкой публике в 2013 году. Суть его заключается в том, что нейронная сетка переваривает большое количество текста и на основании него создает векторы для каждого слова. Эти векторы - это на самом деле веса обученной нейронной сетки, которая либо берет на вход какое-то слово и пытается предсказать ближайшие окружающие его слова (это называется Skip-Gram), либо наоборот: берет на вход окружающие слова, а на выходе предсказывает загаданное слово.
Если взять веса этой нейронки, привести в двухмерное пространство и разместить на графике разные рандомные слова, то окажется, что "пёс" и "собака" будут стоять рядом. А кошка будет ближе ко льву. То же самое с глаголами.
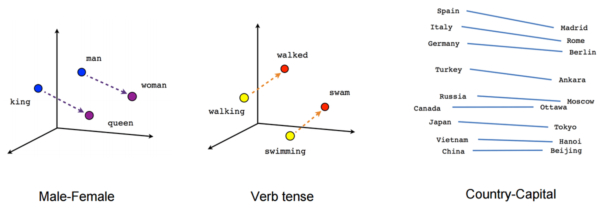
На выходе у Word2Vec каждое слово имеет какой-то длинный вектор чисел, что-то типа [0.12, -0.54, 0.84, ...*ещё 200 чисел*..., 0.99]. Вектор чисел каждого слова не зависит от контекста этого слова - вектор фиксирован. Именно это недоразумение исправили исследовали Google через 5 лет после обнародования Word2Vec, когда опубликовали...
BERT
На самом деле BERT, как и Word2Vec, это лишь один из методов векторизации текста за счет нейронных сетей. Все вместе эти методы называются трансформерами, и их довольно много.
Суть BERTa та же, что у Word2Vec, однако он намного сложнее и более гибкий относительно контекста, в котором употребляется слово. Нейронная сетка BERTа состоит из множества слоёв, в отличие от классического Word2Vec с одним слоем, поэтому BERT долго и сложно обучается на очень большом количестве данных.

Особенно интересен последний пункт про контекст. Давайте рассмотрим его на примере двух предложений:
Он взял лук и пошел на охоту
Он добавил нарезанный лук в картошку
Несмотря на то, что в обоих предложениях мы употребляем слово "лук", его смысл абсолютно разный и отображает разные предметы. Именно тут BERT поймет разницу между двумя луками, а Word2Vec - нет, и даст один и тот же вектор для двух луков.

Изначальный BERT обучался на большом датасете из примерно 3 млрд слов (англоязычная Википедия и Toronto Book Corpus). Впоследствии большая часть дата саенс сообщества либо использует уже готовый BERT, либо переобучает последние слои этой нейронки, чтобы она лучше учитывала контекст какой-то конкретной ситуации, для этого не требуется очень много вычислительных мощностей или данных.
Заключение
Мы ответили на основные вопросы о том, что такое векторизация, как и где она применяется и чем различаются её основные методы. Если вам интересно знать про ИИ и машинное обучение больше, чем рядовой человек, но меньше, чем data scientist, то подписывайтесь на мой канал в Телеграм. Я пишу редко, но по делу: AI для чайников. Подписывайтесь!