Участие добровольцев в изучении редкой болезни Зика (Zika) с помощью распределенных вычислений
Команда OpenZika добавляет новые ресурсы для продолжения массивного анализа данных
Автор: исследовательская группа OpenZika
20 декабря 2018 г.
(Переведено с помощью гугл переводчик)
Резюме
Новые исследовательские модели, новый студент, новые публикации, новое сотрудничество и постоянный анализ данных - все это подробно описано в этом всеобъемлющем обновлении исследовательской группы OpenZika.
Текущая лабораторная работа
Исследовательская группа доктора Каролины Андраде, LabMol, работает над анализом данных, сгенерированных проектом OpenZika. Доктор Мелина Моттин ведет эту задачу.
Мы анализируем виртуальный экран от OpenZika против белка ZIKV NS5, ключевого вирусного фермента, который необходим для созревания вируса и формирования инфекционных вирусных частиц. Полноразмерный белок NS5 содержит два домена, представляющих две разные мишени: метилтрансферазу NS5 и полимеразу NS5. NS5 метилтрансферазный домен метилирует или присоединяет метильные (CH3) радикалы к структуре крышки РНК; и NS5-полимеразный домен синтезирует вирусную РНК и, таким образом, важен для выживания ZIKV и установления инфекции в клетках-хозяевах.
Нам помогают другие бразильские исследователи, которые помогают анализировать большие данные, генерируемые расчетами стыковки из World Community Grid. Профессор Рузвельт Алвес да Силва (Федеральный университет Гояс), д-р Жоао Х. Мартинс Сена (Фонд Освальдо Крус, FIOCRUZ) и доктор Педро Торрес (Кембриджский университет) помогают доктору Моттину и команде LabMol справиться с массовыми количество данных, которые мы генерировали. Кроме того, д-р Моттин обучает нашего нового магистра, Бруну Соуза. Она уже анализирует данные и готовит отчеты.
Кроме того, мы подготовили капсидные белки (из вирусов Зика, Денге и Западного Нила), чтобы «накормить зверя» (то есть, чтобы продолжать создавать рабочие места для стыковки, которые вы все нам интересуете), и выполнить расчеты по стыковке. Капсидные белки флавивируса не имеют ингибиторов, которые совместно кристаллизуются, поэтому мы выполнили предсказание связывания карманных структур капсидной структуры ZIKV. Были определены два обязательных кармана. Затем мы представили стыковочные работы, связанные с карманом 1 и 2 капсидного белка, с базой данных ZINC15 (содержащей 30,2 миллиона соединений).
Доктор Моттин посещает доктора Экинса
(Слева направо) Члены лаборатории фармацевтических препаратов Сотрудничества Кимберли Цорн и доктор Томас Лейн; Доктор Мелина Моттин из LabMol; и со-главный исследователь доктор Шон Экинс на фото в лаборатории Collaborations Pharmaceuticals в Северной Каролине
Доктор Моттин провел почти месяц в качестве приглашенного исследователя в лаборатории доктора Шона Экинса в Северной Каролине. Она работала над моделями Байеса и Случайного леса для Зики, денге и Эболы, используя общедоступные данные. Основная цель этой работы состояла в том, чтобы разработать и внедрить эти модели, чтобы помочь повысить эффективность окончательного выбора соединений для тестирования на вирусы. (Например, мы можем построить модель машинного обучения для Zika и связанных с ней флавивирусов, которая может помочь предсказать, какие соединения с большей вероятностью будут иметь активность целых клеток, что дополнит нашу целевую стыковку в OpenZika.) Модели теперь оптимизируются с помощью новые наборы данных, полученные из литературы и баз данных, таких как ChEMBL и PubChem, для создания новых и более надежных моделей машинного обучения для прогнозирования активности вирусов Зика и денге.
Недавно обнаружены новые ингибиторы-кандидаты
Недавно мы закончили анализ виртуального экрана от OpenZika в отношении протеазы ZIKV NS2B / NS3, ключевого вирусного фермента, необходимого для созревания вируса и формирования инфекционных вирусных частиц. Приблизительно 6 миллионов соединений были состыкованы с протеазой ZIKV, за которыми следовали стыковочные фильтры на основе взаимодействия, чтобы найти соединения, которые, как было предсказано, хорошо пристыковались к аллостерическому сайту. Затем мы использовали модели машинного обучения в качестве фильтров (наш набор байесовских моделей, которые предсказывают микросомальную стабильность печени мыши, отсутствие цитотоксичности и растворимости). В конечном итоге мы визуально проверили способы связывания лучших 318 соединений и сузили их до 27 кандидатов. Эти кандидаты будут куплены и затем проанализированы нашими сотрудниками, чтобы определить их эффективность в ингибировании протеазы, а также их эффективность в клеточных анализах.
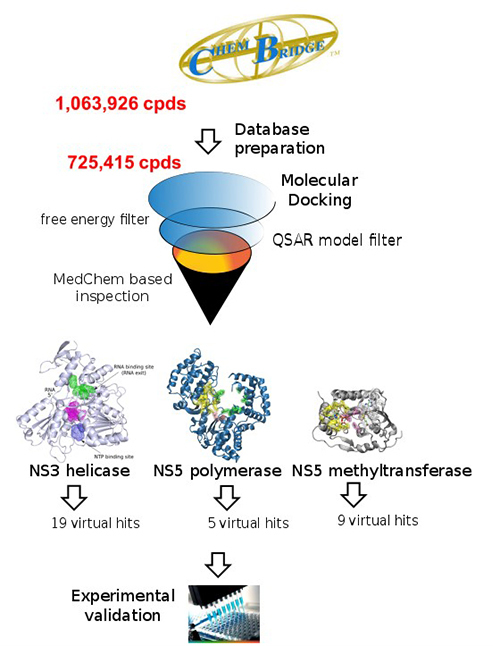
Мы также проанализировали результаты стыковки, касающиеся базы данных Chembridge (~ 1 млн. Соединений) против полимеразы NS5 (сайты РНК и NTP) и метилтрансферазы NS5 (активные сайты, SAM и GTP), а также геликазы NS3 (сайты ATP и РНК). Мы отфильтровали соединения с лучшим рейтингом по разработанным моделям ZIKV QSAR и провели медицинский химический осмотр отфильтрованных соединений, отобрав всего 33 соединения. Следующими шагами будет заказ этих соединений и их экспериментальное тестирование (Рисунок 1).
Рисунок 1. Рабочий процесс экспериментов по виртуальному скринингу, выполненных для геликазы NS3, полимеразы NS5 и метилтрансферазы NS5 с использованием базы данных ChemBridge (~ 1 миллион соединений)
Предстоящие и недавние публикации
Недавно мы опубликовали обзорный документ под названием «Вычисление лекарств для вируса Зика». Этот документ был опубликован в специальном выпуске Бразильского журнала фармацевтических наук. В этой статье мы кратко излагаем текущие усилия по поиску вычислительных лекарств и их применение для обнаружения лекарств против ZIKV. Мы также представляем успешные примеры использования вычислительных подходов к открытию лекарств ZIKV, включая наш проект OpenZika.
В ноябре мы опубликовали основной обзор под названием «A – Z of Zika», в журнале «Drug Discovery Today». Это всесторонний обзор недавних достижений в усилиях по открытию лекарств ZIKV, в которых подчеркивается репозиционирование лекарств и соединений с компьютерным контролем, включая недавно обнаруженные ингибиторы вируса и клетки-хозяина. Также описываются и обсуждаются перспективные молекулярные мишени ZIKV, а также мишени, принадлежащие клетке-хозяину, как новые возможности для открытия лекарств ZIKV. Все эти знания не только важны для продвижения борьбы с вирусом Зика и другими флавивирусами, но и помогут научному сообществу подготовиться к следующей возникающей вирусной вспышке, на которую нам придется реагировать.
Д-р Экинс, д-р Андраде и д-р Моттин вместе с другими исследователями недавно опубликовали обзорный документ «Высокая пропускная способность и вычислительная перепрофилирование для забытых болезней», принятый в журнале Pharmaceutical Research. В этой статье описываются усилия по перепрофилированию многих лекарств, предпринимаемые в разных лабораториях по всему миру в попытке найти способы лечения многих тропических болезней.
Результаты проекта OpenZika были представлены на 256-м Национальном собрании ACS 19-23 августа в Бостоне, штат Массачусетс, США. Д-р Моттин выступил с устной презентацией и представил плакат под названием «OpenZika: обнаружение новых противовирусных кандидатов против вируса Зика» на сессии «Хемоинформатические подходы для улучшения обнаружения лекарств на основе натуральных продуктов».
Доктор Моттин, представляя в ноябре
Д-р Моттин также выступил с устной презентацией «Применение молекулярной динамики для обнаружения лекарств от вируса Зика и Schistosoma mansoni» на встрече по инициативе Южной Америки по сотрудничеству в области молекулярного моделирования (SAIMS), которая состоялась в Институте Пастера, Монтевидео, Уругвай, 4 ноября. 7. Встреча была отличной возможностью для обмена опытом и сотрудничества с южноамериканскими исследователями, которые работают с Zika.
Прошлые публикации и пропаганда
Доктор Шон Экинс представил плакат на «Симпозиуме клеток: новые и вновь появляющиеся вирусы» 1-3 октября 2017 года в Арлингтоне, штат Вирджиния, США, на тему «OpenZika: открытие новых противовирусных кандидатов против вируса Зика».
20 октября 2016 года была опубликована наша статья о забытых тропических заболеваниях PLoS, «OpenZika: проект всемирного сетевого сообщества IBM для ускорения обнаружения вируса Зика», и ее уже просмотрели более 5200 раз. Любой может получить доступ и прочитать эту статью бесплатно. Другой исследовательский документ «Иллюстрирование и моделирование гомологии белков вируса Зика» был опубликован в F1000Research и просмотрен> 4200 раз.
Мы также опубликовали исследовательский документ под названием «Моделирование молекулярной динамики геликазы Zika Virus NS3: анализ активности сайтов связывания РНК» в октябре 2017 года в рамках специального выпуска по флавивирусам для журнала Biochemical and Biophysical Research Communications. Это исследование геликазной системы NS3 помогло нам узнать больше об этой многообещающей цели для блокирования репликации Zika. Результаты помогут нам проанализировать, как мы анализируем виртуальные экраны, которые мы выполняли на геликазе NS3, и моделирование молекулярной динамики создало новые конформации этой системы, которые мы использовали в качестве целей на новых виртуальных экранах, которые мы выполняли в рамках OpenZika.
Новые Сотрудничества
Эти статьи и презентации помогают привлечь дополнительное внимание к проекту и стимулируют формирование новых коллабораций.
Мы начали очень важное сотрудничество с Центром инноваций в области биоразнообразия и обнаружения наркотиков (CIBFar), координируемым профессором Glaucius Oliva, который находится в Университете Сан-Паулу (USP), Бразилия, Институт физики Сан-Карлоса (IFSC). Основной целью этого сотрудничества является тестирование наших соединений непосредственно в ферментных анализах с белками вируса Зика. Наши выбранные соединения проходят тестирование, чтобы определить, могут ли они связываться с геликазой NS3 с использованием метода дифференциальной сканирующей флуоресценции (DSF) и / или могут ли они ингибировать АТФазную активность этого белка.
Другое сотрудничество было начато с бразильской группой, работающей над полусинтетическими и натуральными продуктами, во главе с профессором Луисом Октавио Регасини из Департамента химии и наук об окружающей среде Государственного университета Сан-Паулу (UNESP) и профессором Аной Каролиной Гомеш Жардим из Институт биомедицинских наук, Федеральный университет Уберландии (UFU), эксперт-вирусолог в проведении фенотипических анализов (клеточных анализов) с вирусами. Они проверяют библиотеку природных и синтетических соединений, которые включают флавоноиды, алкалоиды и диариламины, чтобы оценить их противовирусный потенциал против инфекции ZIKV in vitro. Для обнаруженных экспериментальных хитов мы выполняем расчеты стыковки, используя AutoDock Vina с белками ZIKV, используя те же протоколы и модели, которые мы разработали в проекте OpenZika. Результаты этого сотрудничества записываются в исследовательской работе, которая вскоре будет передана в научный журнал для публикации.
Доктор Шон Экинс продолжает сотрудничество с доктором Скоттом Ластером и доктором Фрэнком Шолле в Университете штата Северная Каролина для изучения флавивирусов. У них есть доступ к клеточным анализам на наличие бляшек для этих вирусов. Мы также оценивали несколько натуральных продуктов, которые они определили, чтобы предсказать потенциальные цели в Zika и оценить их экспериментально в лабораториях наших сотрудников, описанных выше.
Новый член студенческой команды
Как упоминалось выше, доктор Андраде нанял нового аспиранта Бруну Соуза для работы над проектом OpenZika. Она начала работать в лаборатории доктора Андраде в марте 2018 года, и она очень увлечена изучением и сотрудничеством в этом проекте. Она является волонтером проекта OpenZika с устройством Android и пригласила студентов и преподавателей аспирантуры, во время занятий и через ее личные социальные сети, принять участие в проекте. Она присоединяется к звонкам OpenZika с World Community Grid.
Бруна Соуза и ее автор в IX Школе молекулярного моделирования в биологических системах в Петрополисе, Рио-де-Жанейро, Бразилия
Она представила свои новые результаты в презентации, озаглавленной «Вычислительные и экспериментальные стратегии для идентификации протеазных и геликазных белков вирусов денге и вирусов Зика». Она была выбрана для участия в IX Школе молекулярного моделирования в биологических системах (IX EMMSB), 20-24 августа, в Национальной лаборатории научных вычислений (LNCC) в Петрополисе - Рио-де-Жанейро, Бразилия.
Бруна и ее вторая постерная презентация на XV Конгрессе исследований UFG, Гояния, Бразилия.
Она также представила плакат под названием «Исследования молекулярной стыковки нового соединения диариламина, активного против репликации вируса Зика». 15-17 октября она участвовала в XV Конгрессе исследований, преподавания и расширения Федерального университета Гояса (UFG), где она представила плакат под названием «Молекулярная стыковка производного антраниловой кислоты против белков Zika».
Состояние расчетов
В общей сложности мы представили почти 6,8 миллиарда рабочих мест для стыковки, в которых участвовало 427 различных целевых сайтов. На наших первых экранах использовалась более старая библиотека из 6 миллионов коммерчески доступных соединений, а в наших текущих экспериментах используется новая библиотека ZINC15 из 30,2 миллиона соединений. Мы уже получили примерно 6,3 миллиарда таких результатов на нашем сервере. (Напоминаем, что между выполнением расчетов на машинах нашего добровольца и получением результатов существует некоторая задержка, поскольку все результаты в «пакете» из примерно 10 000–50 000 различных стыковочных работ необходимо вернуть в World Сетка сообщества, реорганизованная, а затем сжатая перед отправкой на наш сервер.)
До настоящего времени,> 80 000 добровольцев, которые пожертвовали свои свободные вычислительные мощности OpenZika, дали нам расчеты на стыковку> 63 023 года ЦП, в настоящее время в среднем 66,3 года ЦП в день! Спасибо всем большое за помощь!
За исключением нескольких отставших, мы получили все результаты для наших экспериментов, которые включают стыковку 6 миллионов соединений против NS1, NS3 helicase (как сайта связывания РНК, так и сайта ATP), NS5 (как доменов РНК-полимеразы, так и доменов метилтрансферазы) NS2B / NS3 протеаза и капсид (связывающие карманы 1 и 2).
Спасибо всем волонтерам, которые отдают свое неиспользованное компьютерное время этому проекту! Мы ценим вашу помощь!
https://www.sciencedirect.com/topics/medicine-and-dentistry/...
http://www.scielo.br/pdf/bjps/v54nspe/2175-9790-bjps-54-spe-...
https://doi.org/10.1016/j.drudis.2018.06.014
http://www.acs.org/bostoninfo
http://www.cell-symposia.com/emerging-viruses-2017/
http://journals.plos.org/plosntds/article?id=10.1371%2Fjourn...
http://cibfar.ifsc.usp.br/english
http://www.researcherid.com/rid/http:/www.researcherid.com/r...
https://www.worldcommunitygrid.org/about_us/viewNewsArticle....