


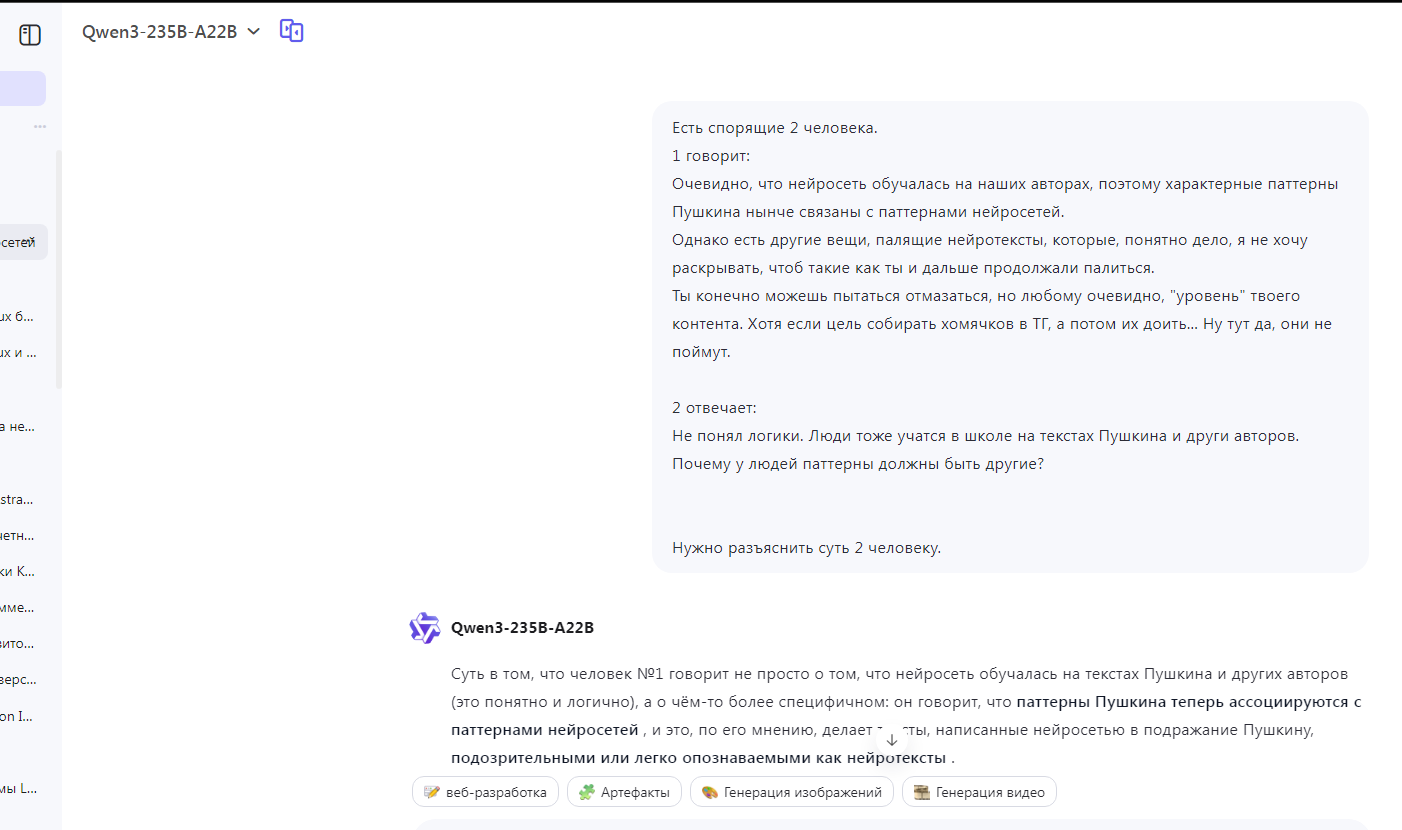
Всё ещё боитесь, что вас заменит ИИ?

«ИИ скоро заменит всех разработчиков!» — панически пишут в комментах те, кто ещё не запускал Cursor на реальном проекте 😅
📊 Новое исследование METR (2025) показало:
опытные разработчики с ИИ работали на 19% медленнее, чем без него.
Да-да, медленнее. Не быстрее. Не так же. А медленнее.
📌 Что исследовали?
Как использование ИИ влияет на производительность опытных open-source разработчиков, выполняющих реальные задачи в известных репозиториях, на которых они работают в среднем уже 5 лет.
🧪 Методология
Участники: 16 разработчиков, более 1 500 коммитов каждый.
Задачи: 246 реальных задач на популярных open-source проектах (средний возраст — 10 лет, ~1,1 млн строк кода).
Эксперимент: задачи случайным образом делились на две группы — с разрешением и без использования ИИ.
Инструменты ИИ: Cursor Pro, Claude 3.5/3.7 Sonnet.
Данные: сбор экранных записей, опросов, оценки времени и поведения разработчиков.
📉 Результаты
Ожидания: разработчики и эксперты предсказывали, что ИИ сократит время выполнения задач на 20–39%.
Реальность: использование ИИ увеличило время выполнения задач на 19%.
Причины
Разработчики слишком оптимистично оценивали полезность ИИ.
ИИ часто требовал доработки — менее 44% генераций были приняты без значительных правок.
Высокая сложность и зрелость репозиториев снижала эффективность ИИ.
Контекст задачи и внутренняя экспертиза разработчиков часто были недоступны ИИ.
Заметна потеря времени на промптинг, ожидание ответа ИИ, ревью и исправление предложенного кода.
🧠 Факторы, способствующие замедлению
Завышенные ожидания от ИИ (разработчики продолжали его использовать, даже если он мешал).
Опыт и знание проекта — ИИ не мог конкурировать с разработчиком, глубоко знакомым с кодовой базой.
Сложность проектов — ИИ хуже справляется в больших, зрелых и нестандартных репозиториях.
Недостаточная надежность ИИ — требовались доработки, частый отказ от предложений.
Недоступность скрытого контекста — ИИ не понимал “негласные” правила и специфику кода.
⚠️ Ограничения
Результаты не обесценивают ИИ в других сценариях, например:
для новичков;
при разработке с нуля;
в проектах без строгих стандартов.
Более продвинутые модели ИИ или техники промптинга могут в будущем обеспечить прирост производительности.
💡 Выводы
🔧 ИИ — это не магия, а инструмент. И пока не идеальный.
💭 Люди и эксперты сильно переоценивают его эффективность.
🤹 Не стоит бросаться в прод с ИИ как с горячей пиццей — можно обжечься и опоздать на релиз.
🧠 А вот кто реально на вес золота — это опытный разработчик с головой на плечах, умеющий дружить с ИИ, но не теряющий здравый смысл.
💬 Как у вас с ИИ в проде? Работает? Мешает?
Пишите в комментах, делитесь опытом — будет интересно сравнить!
--
👉 Публикую такие штуки у себя в Telegram-канале
«Кофе, код и консоль» — про backend, AI в коде, Bitrix и реальные боли разработчиков.
Если интересно — залетай сюда ☕️





Искусственный интеллект
4.5K постов11.3K подписчиков
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан