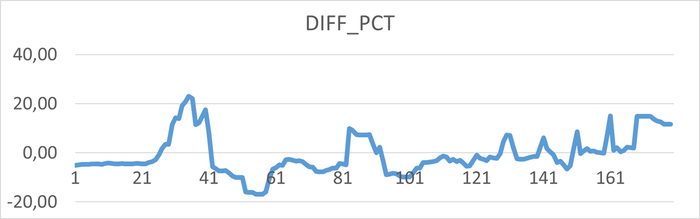
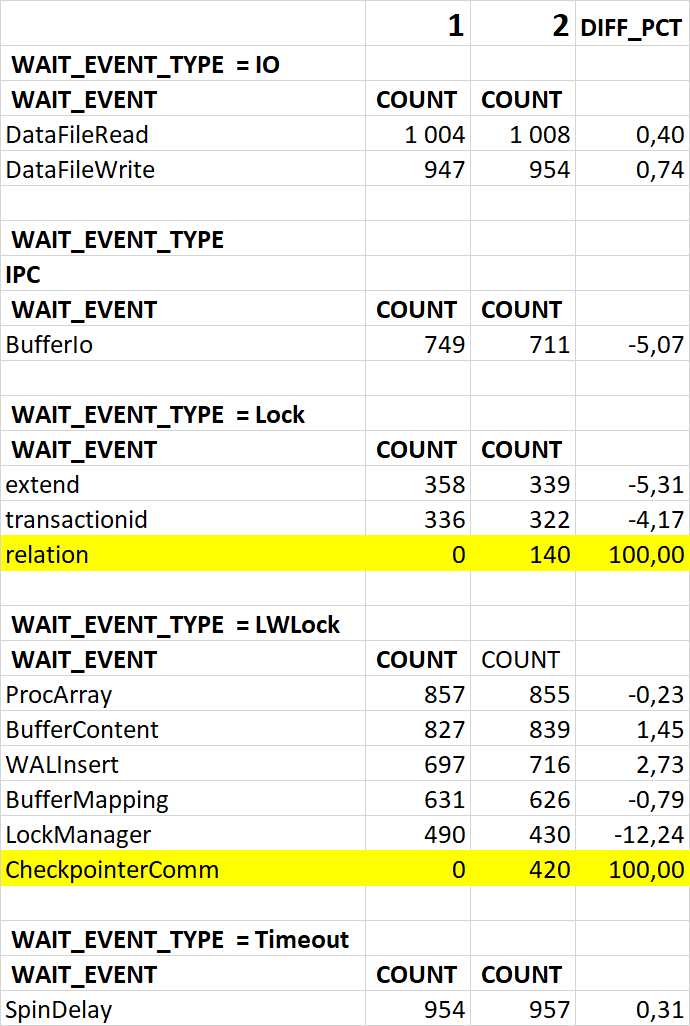
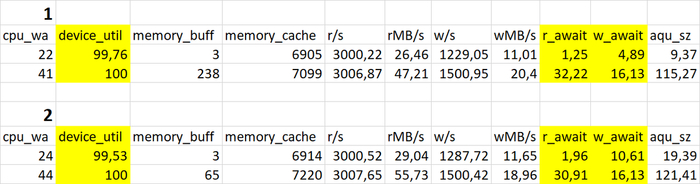
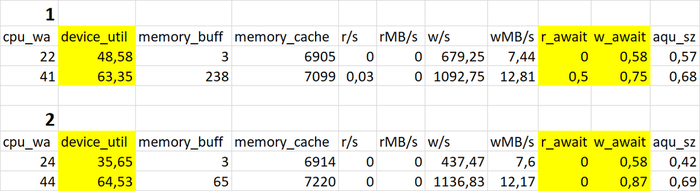
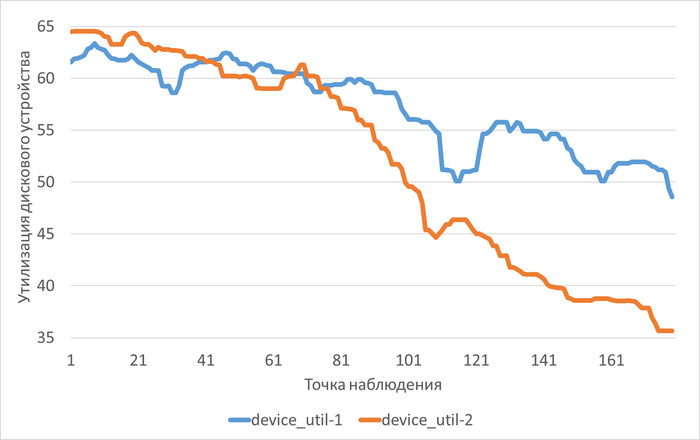
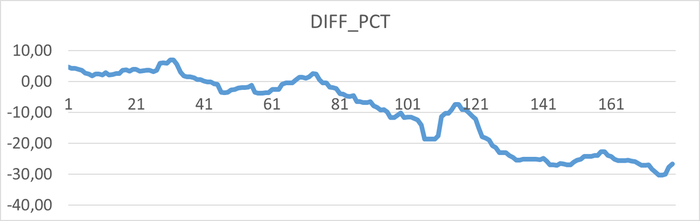
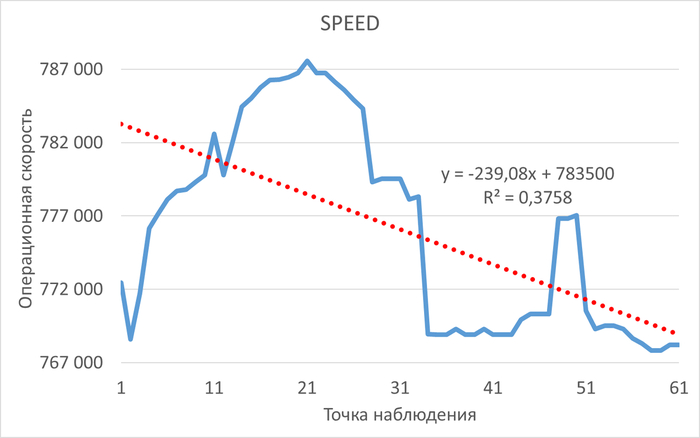
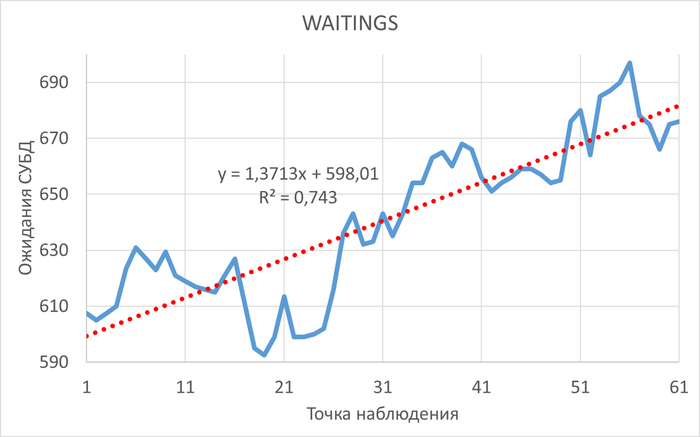
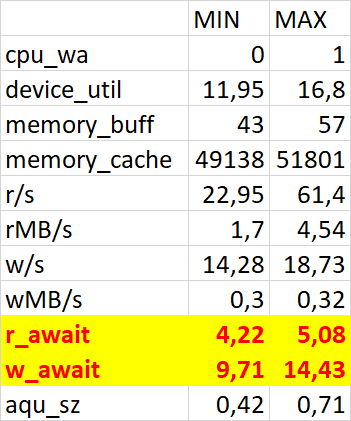
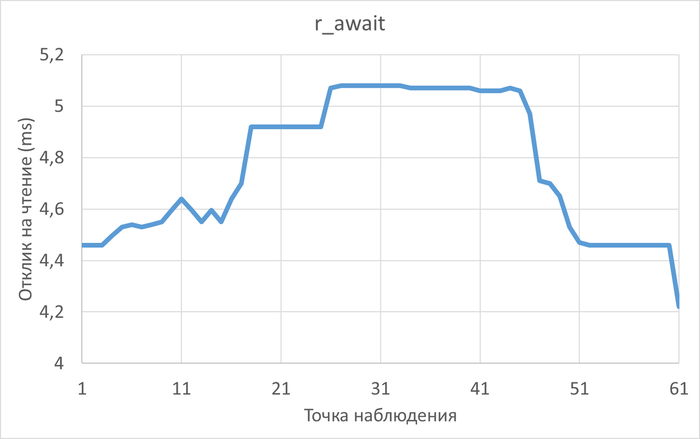
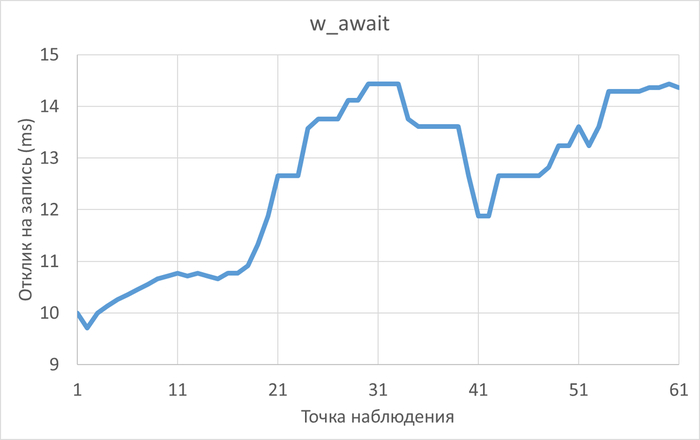
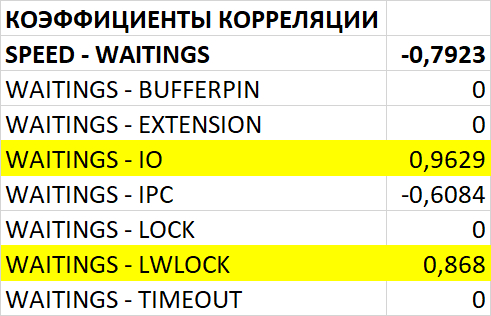
Использование семантического анализа (NLP) для анализа рекомендаций по оптимизации ожиданий СУБД и текстов SQL запросов
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Если нейросеть применять по прямому назначению не называя "искусственным интеллектом" - есть реальная польза.
Задача
Провести семантический анализ рекомендации по оптимизации события ожиданий СУБД .
Выделить ключевые паттерны рекомендаций по оптимизации событий ожидания по заданному типу ожидания.
Провести семантический анализ SQL запросов.
1. Семантический анализ рекомендаций по оптимизации ожиданий СУБД
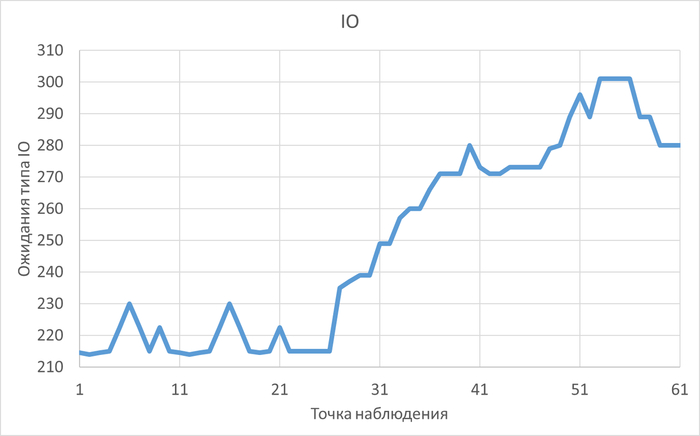
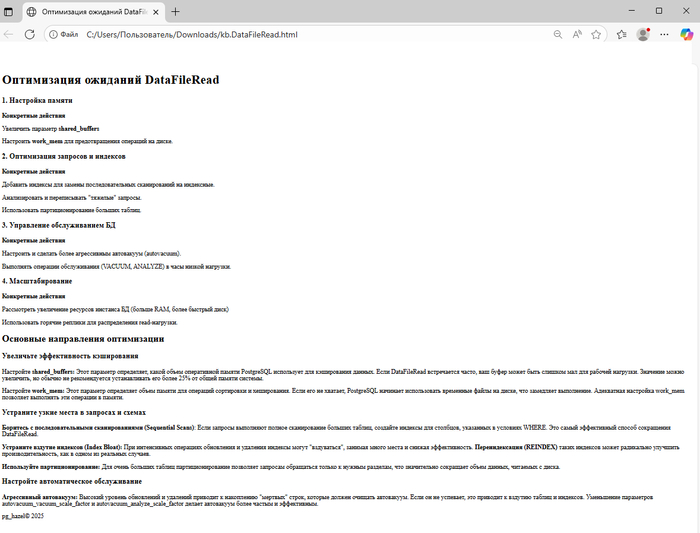
Анализируя текст об оптимизации ожиданий DataFileRead в PostgreSQL, можно выделить следующее семантическое ядро:
Центральная концепция
"Сокращение дисковых операций через эффективное использование памяти и оптимизацию доступа к данным"
Ключевые смысловые кластеры
1. Управление памятью и кэшированием
-- Ключевые параметры
shared_buffers -- кэширование данных
work_mem -- операции в памяти
Семантика: Предотвращение физического чтения с диска через эффективное кэширование
2. Оптимизация доступа к данным
Индексное сканирование vs Последовательное сканирование
Партиционирование больших таблиц
Переиндексация для борьбы с раздуванием
Семантика: Минимизация объема читаемых данных
3. Проактивное обслуживание
autovacuum -- автоматическая очистка
VACUUM -- ручная очистка
ANALYZE -- обновление статистики
REINDEX -- перестройка индексов
Семантика: Предотвращение деградации производительности
4. Архитектурное масштабирование
Вертикальное масштабирование: больше RAM, быстрые диски
Горизонтальное масштабирование: горячие реплики для read-нагрузки
Семантика: Распределение нагрузки и увеличение ресурсов
Семантические связи и иерархия
Причинно-следственные связи
Недостаток памяти → Дисковые операции → DataFileRead ожидания
Отсутствие индексов → Sequential Scans → Увеличение I/O
Нет обслуживания → Bloat → Неэффективные чтения
Таксономия решений
Проактивные (предотвращение):
├── Настройка памяти
├── Создание индексов
└── Партиционирование
Реактивные (исправление):
├── Переиндексация
├── Агрессивный autovacuum
└── Оптимизация запросов
Ключевые метрики и показатели
Эффективность кэширования (hit ratio)
Объем последовательных сканирований
Уровень раздувания индексов и таблиц
Частота операций autovacuum
Семантические паттерны оптимизации
Паттерн "Память вместо диска"
-- До: операции на диске
-- После: операции в памяти
work_mem = 4MB → work_mem = 64MB
Паттерн "Точечный доступ вместо полного сканирования"
-- До: SELECT * FROM large_table WHERE condition
-- После: CREATE INDEX idx_condition ON large_table(condition)
Паттерн "Разделяй и властвуй"
-- Партиционирование больших таблиц по датам/диапазонам
CREATE TABLE data_2024 PARTITION OF main_table FOR VALUES FROM...
Выводы о семантическом ядре
Текст построен вокруг трех фундаментальных принципов:
Профилактика - настройка памяти и индексов до возникновения проблем
Эффективность - минимизация избыточных операций ввода-вывода
Регулярность - систематическое обслуживание для поддержания производительности
Главная семантическая ось: Память → Кэш → Диск с акцентом на смещении операций влево по этой оси для максимальной производительности.
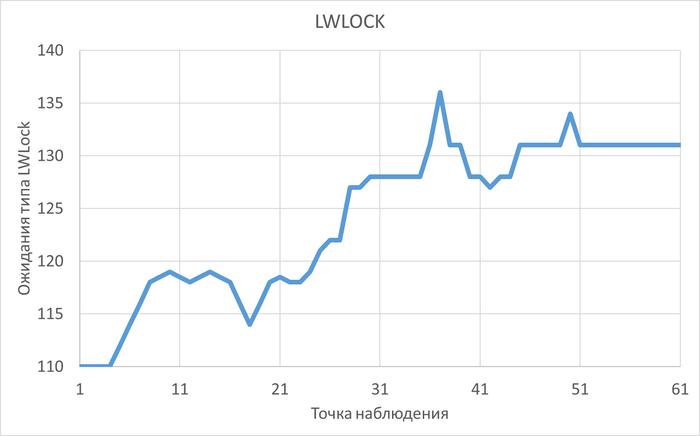
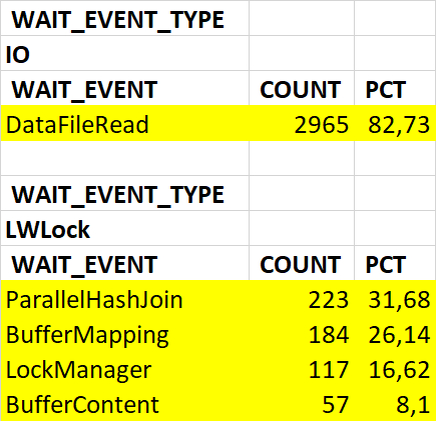
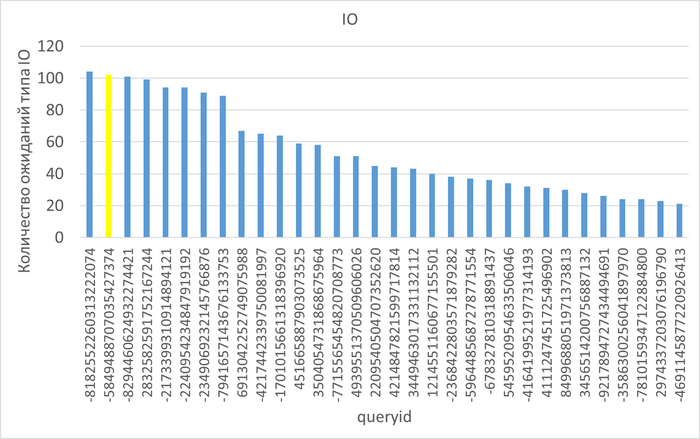
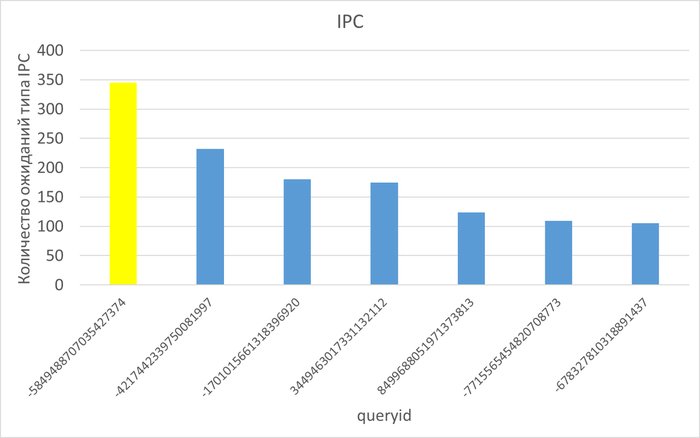
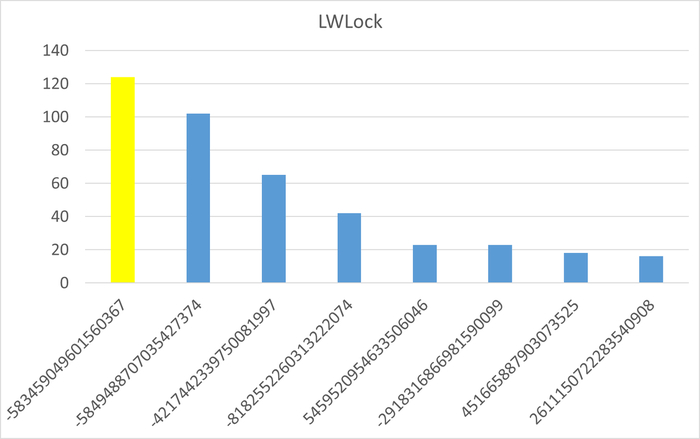
2. Ключевые паттерны рекомендаций по оптимизации событий ожидания по заданному типу ожидания.
1. Общие причины проблем производительности
Конкуренция за ресурсы
BufferContent: "конкуренция процессов за доступ к одним и тем же данным"
BufferMapping: "конкуренция за доступ к буферному кэшу"
LockManager: "общая проблема с большим количеством конкурентных блокировок"
ParallelHashJoin: "процессы координируют свою работу или ожидают друг друга"
Проблемы с памятью
BufferContent: "неэффективная работа с памятью", "данные не находятся в памяти"
BufferMapping: "частота замены буферов и операций ввода-вывода"
ParallelHashJoin: "нехватка оперативной памяти для построения хэш-таблиц"
2. Общие подходы к оптимизации
Настройка памяти
-- Общие параметры памяти :
BufferContent: shared_buffers
BufferMapping: shared_buffers
ParallelHashJoin: work_mem, hash_mem_multiplier
Борьба с раздуванием (Bloat)
BufferContent: "Боритесь с раздуванием", "VACUUM FULL", "pg_repack", "REINDEX"
BufferMapping: "Бороться с раздутостью (Bloat) таблиц и индексов"
ParallelHashJoin: "раздутые (bloated) индексы", "VACUUM и ANALYZE"
Оптимизация индексов
BufferContent: "Удалите неиспользуемые и дублирующиеся индексы", "Используйте частичные индексы"
BufferMapping: "оптимизировать индексы"
ParallelHashJoin: "Проверьте наличие адекватных индексов"
3. Общие методы диагностики
Мониторинг метрик
BufferContent: "Следите за метрикой BufferCacheHitRatio"
BufferMapping: "Мониторить blks_hit и blks_read"
ParallelHashJoin: "EXPLAIN ANALYZE", "EXPLAIN (ANALYZE, BUFFERS)"
Анализ рабочей нагрузки
Все тексты: необходимость анализа выполняемых запросов и выявления проблемных паттернов
4. Общие архитектурные рекомендации
Масштабирование ресурсов
BufferContent: "Масштабируйте вычислительные ресурсы", "увеличение размера экземпляра БД"
ParallelHashJoin: "Контролируйте уровень параллелизма", "max_parallel_workers"
Оптимизация приложения
BufferContent: "пересмотреть логику приложения" для "горячих" данных
LockManager: "пересмотр логики блокировок в приложении"
ParallelHashJoin: "пересмотрите необходимость параллелизма для конкретных запросов"
5. Общие философские принципы
Комплексный подход
Все тексты подчеркивают необходимость комплексного решения, а не точечных исправлений
Баланс ресурсов
ParallelHashJoin: "Помните о балансе: Увеличивая лимиты памяти для одного запроса, вы можете уменьшить доступную память для других"
Эта идея имплицитно присутствует во всех текстах
Смысловые совпадения и выводы
Память как ключевой ресурс - все проблемы так или иначе связаны с эффективным использованием памяти
Проактивное обслуживание - необходимость регулярного VACUUM, ANALYZE и мониторинга
Архитектурный подход - оптимизация требует изменений на всех уровнях: от параметров БД до логики приложения
Диагностика прежде оптимизации - везде подчеркивается важность анализа перед внесением изменений
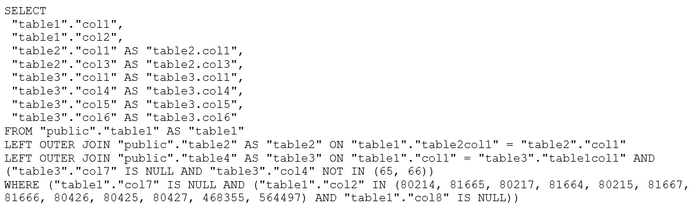
3. Cемантический анализ SQL запросов.
1. Структурные паттерны
Паттерн мягкого удаления (Soft Delete)
-- Во всех запросах присутствует:
"deleteDateTime" IS NULL
Запрос 1,2: "SuccessionPlan"."deleteDateTime" IS NULL, "successors"."deleteDateTime" IS NULL
Запрос 3: "ImprovementPlanGoalToCourse"."deleteDateTime" IS NULL
Паттерн JOIN с дополнительными условиями
-- LEFT JOIN с фильтрацией в условии соединения
LEFT OUTER JOIN ... ON ... AND ("successors"."deleteDateTime" IS NULL AND ...)
2. Паттерны проекции данных
Селекция конкретных полей с алиасами
-- Паттерн: table."column" AS "alias.table.column"
"riskLeaving"."id" AS "riskLeaving.id"
"successors"."workflowStatusId" AS "successors.workflowStatusId"
Вложенные связи через JOIN
-- Цепочка связей между таблицами
"goal->improvementPlan"."empCodeId" AS "goal.improvementPlan.empCodeId"
3. Паттерны фильтрации
Фильтрация по идентификаторам
-- IN с списками значений
"SuccessionPlan"."positionId" IN (871798)
"SuccessionPlan"."positionId" IN (80214, 81665, 80217, ...)
Исключающая фильтрация
-- NOT IN для исключения статусов
"successors"."workflowStatusId" NOT IN (65, 66)
4. Паттерны бизнес-логики
Управление состоянием через workflowStatusId
Во всех запросах присутствует работа со статусами (workflowStatusId, candidateStatusId)
Архивация и временные метки
-- Проверка на архивные записи
"SuccessionPlan"."archiveDate" IS NULL
Пагинация и упорядочивание
-- Запрос 3: ORDER BY ... LIMIT
ORDER BY "ImprovementPlanGoalToCourse"."id" ASC LIMIT 200
5. Смысловые совпадения по доменной модели
Управление кадровыми процессами
Преемственность: successionPlan, successor, readinessId
Развитие сотрудников: ImprovementPlanGoalToCourse, courseSession
Оценка компетенций: participationResult, score, passed
Workflow и статусы
-- Общая система статусов
workflowStatusId, candidateStatusId, readinessId
applicantListType, participation_result
Временные жизненные циклы
recordingDateTime, sessionBeginDate, sessionEndDate, update_date_time
6. Архитектурные паттерны
Нормализация данных
Множество связанных таблиц с внешними ключами
Разделение сущностей на основные и справочные
Гибкая система расширений
Использование типа applicantListType
Поддержка миграций через migration_code
Выводы и рекомендации
Единая архитектура: Все запросы следуют одним принципам проектирования
Консистентность: Единый подход к мягкому удалению и архивации
Масштабируемость: Использование пагинации для больших наборов данных
Бизнес-логика: Система ориентирована на управление HR-процессами
Оптимизационные возможности:
Индексы по deleteDateTime, workflowStatusId
Составные индексы для частых JOIN условий
Оптимизация запросов с IN для больших списков
Эти паттерны показывают зрелую систему с продуманной архитектурой и последовательным подходом к проектированию запросов.