Как я разрабатывал @lifestyle_tracker_bot
3 поста
В данной статье мы рассмотрим применение речевых технологий, предоставленных компанией Яндекс в контексте распознавания аудиосообщений в Telegram – популярном мессенджере, объединяющем миллионы пользователей по всему миру.

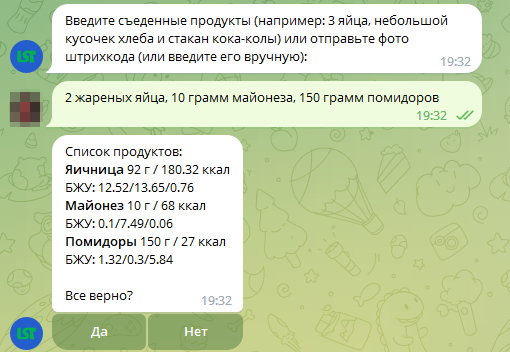
Изначально функционал получения текст из аудио мне нужен был для проекта, о котором я писал здесь и здесь, где я хотел реализовать ввод продуктов в дневник питания не только текстом но путем отправки аудиосообщения. Кому интересно - можете затестить данный функционал тут. Получилось довольно интересно:
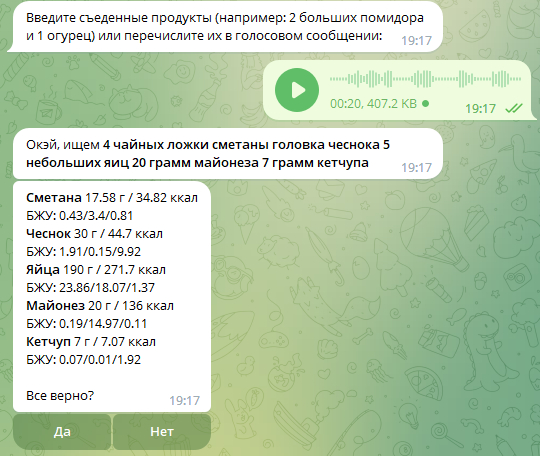
Данный функционал нам великодушно и альтруистично (почти) предоставила компания Яндекс на их сервисе Яндекс.Облако (Yandex.Cloud). На первый взгляд, название может напоминать о неком облачном хранилище для бесконечных потоков фотографий с телефона, но на самом деле все куда интереснее:
Яндекс.Облако - это сервис облачных вычислений, предоставляемый компанией Яндекс. Он позволяет людям и компаниям арендовать виртуальные серверы и ресурсы для хранения данных, запуска приложений и выполнения вычислений через интернет. Это как аренда виртуального пространства на компьютерах компании Яндекс, чтобы использовать их мощности для своих целей без необходимости покупки и поддержки собственного оборудования.
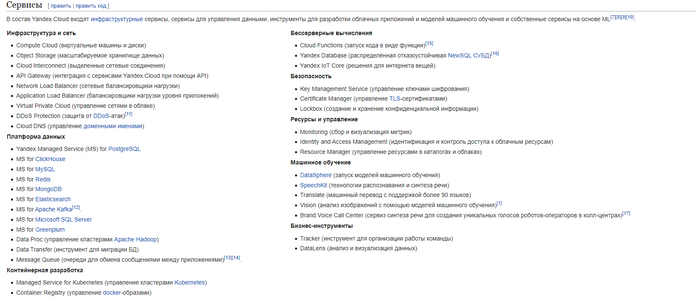
На Яндекс.Облаке можно найти кучу различных программистских интересностей - распознавание/генерация аудио, машинный перевод, нейросети, базы данных и т.д. Полный список актуальных решений можно посмотреть здесь или посмотреть их список, взятый из википедии ниже:
Да, каждый сервис платный, но их стоимость, в большинстве решений, не столь высока, да и Яндекс предоставляет тестовый период и грант для новых пользователей. Подробные условия их получения можно посмотреть здесь и здесь. Говоря кратко - если вы только зарегистрировались в Яндекс.Облаке, то нате 2 месяца бесплатного доступа, чтобы все затестить.
Переходим на Яндекс.Облако, авторизируемся и попадаем в консоль. После чего сразу создаем здесь платежный аккаунт. Если вы вошли сюда в первый раз, то получаем пробный период/грант или не заморачиваемся и пополняем счет на пару десятков рублей, привязав банковскую карту.
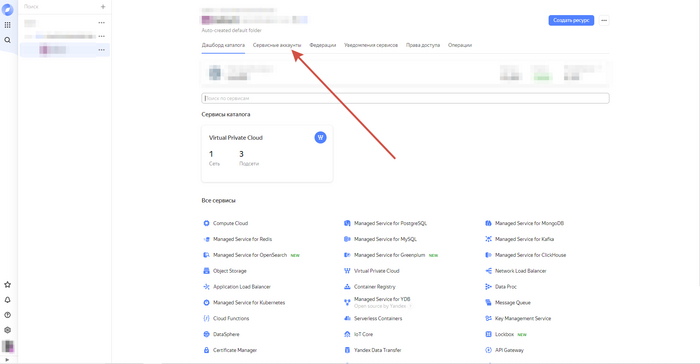
Следующее, что нам нужно сделать - это создать сервисный аккаунт. Сервисный аккаунт в Яндекс.Облаке - это как виртуальная личность для программы или сервиса, которую можно создать, чтобы позволить ей использовать ресурсы и функции облачных серверов без необходимости использовать личный аккаунт. Это позволяет приложениям и программам работать в облаке, делая их доступ более безопасным и удобным, и изолируя их от других пользователей.
Для этого переходим на данную вкладку:
Далее в данном разделе жмем на кнопку "Создать сервисный аккаунт". Вводим название и выбираем роль. В данном примере мы будем использовать функционал по распознавания аудио - Speech-To-Text (STT), поэтому в качестве роли выберем "ai.speechkit-stt.user".
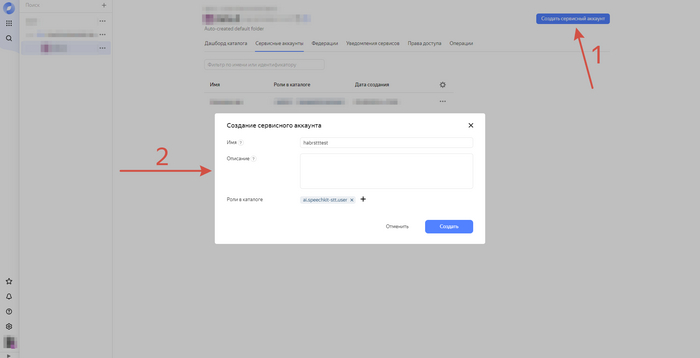
Жмем "Создать" и после недолгой прогрузки увидим новую строку в списке сервисных аккаунтов на этой же странице. Нажимаем на эту строчку и попадаем на новую страницу, где в правой верхней части экрана находим кнопку "Создать новый ключ", нажимаем и выбираем "API-ключ". Появится форма, в которой можно задать описание для данного ключа - нажимаем "Создать" и получаем свежий ключ:
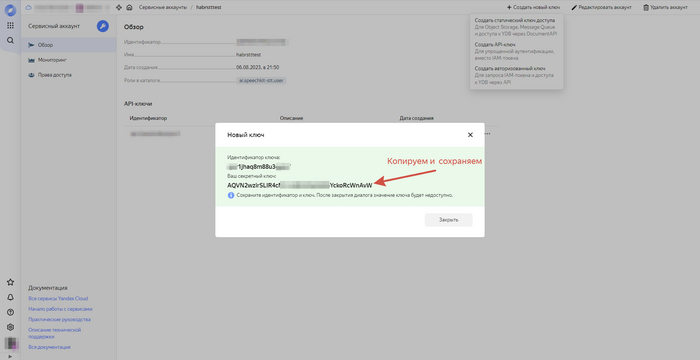
Готово! Сохраняем себе данный ключ или не закрываем данную форму, чтобы потом его скопировать в программу.
Чтобы затестить функционал сервиса давайте соберем простейшего чат-бота для Telegram, который будет расшифровывать аудиосообщения и присылать нам текст.
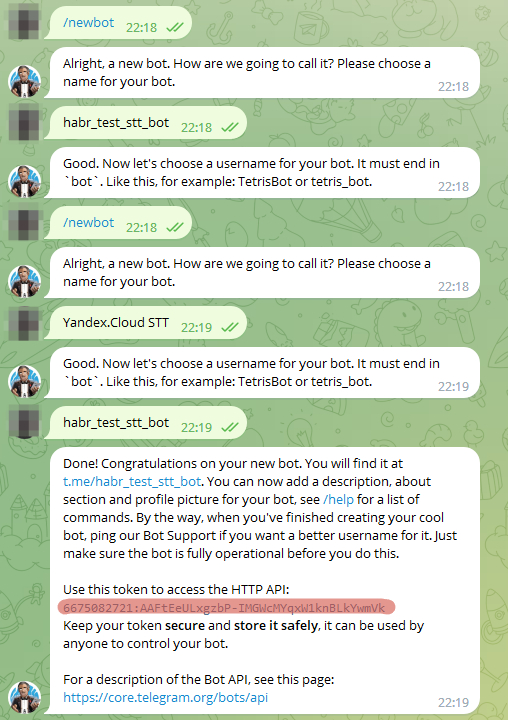
Для начала пойдем к BotFather и, склонив колено, попросим токен для нового чат-бота:
Запускаем бота BotFather
Вызываем команду /newbot
Вводим название для нового бота
Вводим его username
Получаем токен
Теперь перейдем к основной части представления и начнем писать код чат-бота.
Для создания чат-бота воспользуемся библиотекой telebot (или pyTelegramBotAPI), которую установим таким образом:
pip install pyTelegramBotAPI
Сперва создадим файл "config.py", где будем хранить все полученные ключи и экземпляр класса TeleBot (импортированный из библиотеки telebot), с помощью которого будут происходить все взаимодействия с чат-ботом. В конструктор данного класса передаем лишь только токен, который мы до этого получили и сохранили в переменную BOT_TOKEN.
from telebot import TeleBot
# Токен чат-бота
BOT_TOKEN = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
# Экземпляр класса TeleBot, через который будет происходить все взаимодействия
# с ботом
bot = TeleBot(BOT_TOKEN)
# API-ключ сервисного аккаунта из Yandex.Cloud
YC_STT_API_KEY = 'YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY'
Заменяем значения переменных BOT_TOKEN и YC_STT_API_KEY на свой токен и API-ключ соответственно. Далее создаем файл "main.py", где будет располагаться функционал самого чат-бота. В начале определим все импорты:
from config import bot
from telebot.types import Message
Здесь мы импортировали объект класса TeleBot из раннее созданного "config.py" и класс Message из подмодуля types библиотеки. Данный класс представляет собой сообщение, отправленное в чат и содержит всю исчерпывающую информацию о нем.
Первое, что должен уметь чат-бот - это реагировать на команду /start, которая как раз и вызывается при запуске бота:
# Используем декоратор из объекта класса TeleBot,
# в который передаем параметр commands - список команд,
# при вызове которых будет вызываться данная функция @bot.message_handler(commands=['start'])
# Определяем функцию для обработки команды /start, она принимает объект класса
# Message - сообщение
def start(message:Message):
# Отправляем новое сообщение, указав ID чата с пользователем и сам текст сообщения
bot.send_message(message.chat.id, "Йоу! Отправь мне аудиосообщение")
Здесь мы использовали декоратор из объекта bot, который даст нашей программе знать, что вот эту функцию start нужно вызывать только тогда, когда пользователь ввел команду /start.
Самая функция принимает лишь один аргумент - это экземпляр класса Message, то есть, в данном случае, это будет то самое сообщение с командой /start, которую юзер отправил сам или просто нажал "Запустить", войдя первый раз в нашего бота. В последнем случае она будет отправлена за него боту автоматически.
message_handler - это декоратор из библиотеки telebot, предназначенный для обработки входящих сообщений в чат-боте. Он позволяет задать функцию, которая будет вызываться автоматически, когда бот получает сообщение определенного типа или удовлетворяющее определенным условиям.
В самом конце файла размещаем следующий код, который запустит бот при запуске "main.py":
if __name__ == "__main__":
bot.polling(non_stop=True)
Итак, теперь наш бот реагирует на его запуск пользователем и выпрашивает аудиосообщение:

Раз уж просит, то давайте дадим ему такую возможность и напишем еще одну функцию которая будет реагировать на отправку голосового сообщения:
Сперва определим функцию с другим декоратором, который будет реагировать уже не на команду, а тип сообщения - а именно голосовое:
@bot.message_handler(content_types=['voice'])
def handle_voice(message:Message):
Давайте импортируем еще один класс из библиотеки, который будет представлять аудиосообщение:
from telebot.types import Voice
Теперь внутри функции нам нужно получить отправленное/пересланное аудиосообщение. Так как оно уже хранится на серверах Telegram, то мы можем просто получить путь к нему.
# Определяем объект класса Voice, который находится внутри параметра message
# (он же объект класса Message)
voice:Voice = message.voice
# Получаем из него ID файла аудиосообщения
file_id = voice.file_id # Получаем всю информацию о данном файле
voice_file = bot.get_file(file_id)
# А уже из нее достаем путь к файлу на сервере Телеграм в директории
# с файлами нашего бота
voice_path = voice_file.file_path
В данном случае переменная voice_path будет храниться в себе относительный путь к аудиофайлу, например: "voice/file_0.oga". То есть, есть сервер Telegram, а в нем директория со всеми файлами нашего бота - там есть папка voice где и лежит присланное аудиосообщение.
OGA - это расширение файла аудио, используемое на серверах Telegram. Этот формат, известный как Ogg Vorbis, обеспечивает хорошее качество звука и небольшие размеры файлов, что позволяет передавать голосовые сообщения в мессенджере с высокой четкостью и экономией трафика.
Однако, толку от такого пути для нас никакого. Давайте применим немного хитрости и получим абсолютный путь к сохраненному аудиосообщению. Для этого нам понадобится токен бота, который мы сохранили в "config.py":
from config import BOT_TOKEN
И относительный путь файла, хранящийся в переменной voice_path:
file_base_url = f"https://api.telegram.org/file/bot{BOT_TOKEN}/{voice_path}"
Таким образом мы получим абсолютный путь к аудиофайлу на сервере Telegram вида:
Теперь у нас есть ссылка на аудиофайл и мы можем отправить ее Яндекс.Облаку, который попытается получить из данного аудиофайла текст.
Создаем еще один файл, где мы будем взаимодействовать с сервисом Yandex.Cloud. Назовем его, к примеру "yandex_cloud.py". Мы могли бы использовать какие-нибудь готовые библиотеки для данной задачи, но для такого простого функционала легче написать взаимодействие при помощи классического модуля requests. Импортируем его и API-ключ от Яндекс.Облака из конфига:
import requests
from config import YC_STT_API_KEY
Определим переменную с адресом, на который будет идти запрос:
# URL для отправки аудиофайла на распознавание
STT_URL = 'https://stt.api.cloud.yandex.net/speech/v1/stt:recognize'
И создаем функцию, которая будет принимать в качестве аргумента адрес аудиофайла на серверах Telegram и возвращать распознанный из него текст:
def get_text_from_speech(file_url):
# Выполняем GET-запрос по ссылке на аудиофайл
response = requests.get(file_url)
# Если запрос к серверу Telegram не удался...
if response.status_code != 200:
return None
# Получаем из ответа запроса наш аудиофайл
audio_data = response.content
# Создам заголовок с API-ключом для Яндекс.Облака, который пошлем в запросе
headers = { 'Authorization': f'Api-Key {YC_STT_API_KEY}' }
# Отправляем POST-запрос на сервер Яндекс, который занимается расшифровкой
# аудио, передав его URL, заголовок и сам файл аудиосообщения
response = requests.post(STT_URL, headers=headers, data=audio_data)
# Если запрос к Яндекс.Облаку не удался...
if not response.ok:
return None
# Преобразуем JSON-ответ сервера в объект Python
result = response.json()
# Возвращаем текст аудиосообщения
return result.get('result')
Осталось только доработать функцию handle_voice из "main.py"
Вернемся к модулю main и импортируем созданную функцию:
from yandex_cloud import get_text_from_speech
Продолжим код функции handle_voice и добавим пару строчек:
# Сохраняем текст аудиосообщения в переменную
speech_text = get_text_from_speech(file_base_url)
# Посылаем его пользователю в виде нового сообщения bot.send_message(message.chat.id, speech_text)
Снова запускаем бота и, смотрим на результат:
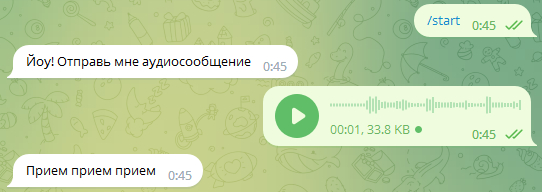
Готово!
Полный код бота можно скачать на GitHub:
Ссылка на 1 часть, где мы говорили о тренировках:

Теперь настало время поговорить о второй составляющей чат-бота - дневник питания (он же калькулятор калорий).
В отличие от БД с физическими упражнениями здесь есть из чего выбрать. Существует куча баз продуктов питания с доступом по API, к примеру:
FoodData Central от Министерства сельского хозяйства США + можно скачать саму БД
Остановиться было решено на... Nutritionix, так как она обладает одной интересной фишкой - распознавание всех продуктов из одного запроса. То есть, мы можем просто послать на сервис строку вида "3 вареных яйца и банка пива", а сервис выудит все перечисленные продукты их количество/вес/объем и отправит в ответе информацию по каждой позиции. Например:
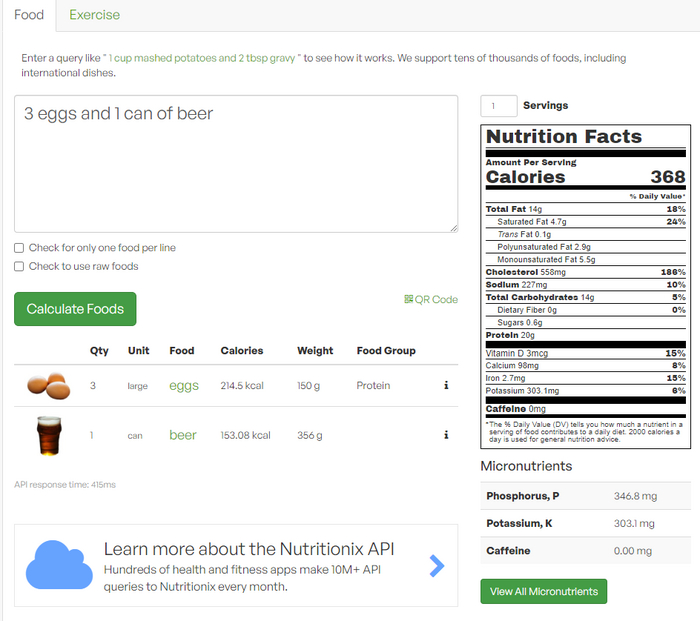
При этом если мы не укажем конкретный вес/объем продукта, то сервис просто возьмет стандартное значение: 1 вареное яйцо - 50 грамм или 1 кусочек хлеба - 29 грамм. Кому интересно - можете затестить данный функционал сервиса по ссылке ниже:
Кстати, подобный функционал у Nutritionix есть и для тренировок - ввел объем выполненного упражнения (например, пробежал 30 минут) и получил количество потраченных калорий, но, сейчас не об этом.
Помимо калорий, белков, жиров у углеводов сервис предоставляет и другие составляющие продукта - минералы, витамины, алкоголь, вода, соль, сахар и другие - всего 161 позиция.
Но, как вы заметили, сервис принимает запросы только на английском языке. Как это нас остановит? Никак. Что же тогда делать? Переводить...
Перевести простейшее предложение вида "2 помидора, ложка оливкового масла и зубчик чеснока" не будет сложной задачей для любого популярного переводчика, поэтому давайте воспользуемся функционалом одного из них. Для этого давайте выберем какой-нибудь онлайн-переводчик и Python-библиотеку под него, например googletrans для Google Переводчика.
Шаг 1. Устанавливаем библиотеку
pip install googletrans
Шаг 2. Переводим
from googletrans import Translator
def translate_from_rus_to_eng(text):
translator = Translator()
translated = translator.translate(text, src='ru', dest='en')
return translated.text
Итак, пользователь что-то ввел, мы это перевели, а теперь настало время отправить запрос к Nutritionix. Однако, для начала нам нужно получить парочку ключей для взаимодействия с сервисом. Для этого переходим по данной ссылке, регистрируемся и копируем Application ID и Application Key.
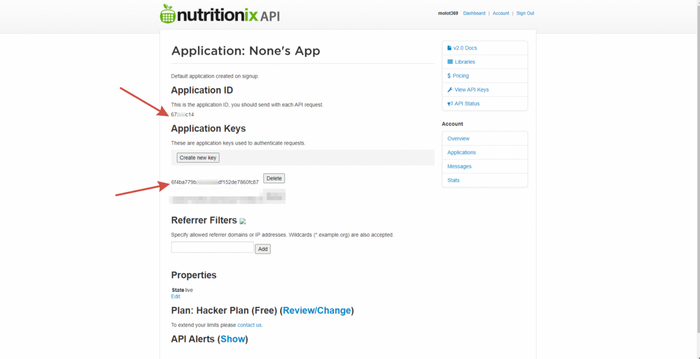
У нас есть д̶в̶а̶ ̶п̶а̶к̶е̶т̶и̶к̶а̶ ̶т̶р̶а̶в̶ы̶,̶ ̶с̶е̶м̶ь̶д̶е̶с̶я̶т̶ ̶п̶я̶т̶ь̶ ̶а̶м̶п̶у̶л̶ ̶м̶е̶с̶к̶а̶л̶и̶н̶а̶,̶ ̶5̶ ̶п̶а̶к̶е̶т̶и̶к̶о̶в̶ ̶д̶и̶э̶т̶и̶л̶а̶м̶и̶д̶а̶ ̶л̶и̶з̶е̶р̶г̶и̶н̶о̶в̶о̶й̶ ̶к̶и̶с̶л̶о̶т̶ы̶ ̶и̶л̶и̶ ̶Л̶С̶Д̶,̶ ̶с̶о̶л̶о̶н̶к̶а̶,̶ ̶н̶а̶п̶о̶л̶о̶в̶и̶н̶у̶ ̶н̶а̶п̶о̶л̶н̶е̶н̶н̶а̶я̶ ̶к̶о̶к̶а̶и̶н̶о̶м̶,̶ ̶и̶ ̶ц̶е̶л̶о̶е̶ ̶м̶о̶р̶е̶ ̶р̶а̶з̶н̶о̶ц̶в̶е̶т̶н̶ы̶х̶ ̶а̶м̶ф̶е̶т̶а̶м̶и̶н̶о̶в̶,̶ ̶б̶а̶р̶б̶и̶т̶у̶р̶а̶т̶о̶в̶ ̶и̶ ̶т̶р̶а̶н̶к̶в̶и̶л̶и̶з̶а̶т̶о̶р̶о̶в̶,̶ ̶а̶ ̶т̶а̶к̶ ̶ж̶е̶ ̶л̶и̶т̶р̶ ̶т̶е̶к̶и̶л̶ы̶,̶ ̶л̶и̶т̶р̶ ̶р̶о̶м̶а̶,̶ ̶я̶щ̶и̶к̶ ̶«̶Б̶а̶д̶в̶а̶й̶з̶е̶р̶а̶»̶,̶ ̶п̶и̶н̶т̶а̶ ̶ч̶и̶с̶т̶о̶г̶о̶ ̶э̶ф̶и̶р̶а̶,̶ ̶и̶ ̶1̶2̶ ̶п̶у̶з̶ы̶р̶ь̶к̶о̶в̶ ̶а̶м̶и̶л̶н̶и̶т̶р̶и̶т̶а̶ 2 ключа для API и переведенный запрос, так что - давайте кодить.
Все запросы (POST) будем посылать на следующий URL, сохранив его в переменную:
natural_url = https://trackapi.nutritionix.com/v2/natural/nutrients
В начале подключаем библиотеку requests и собираем заголовки из Content-Type, Application ID и Application Key:
import requests
# Заголовки
headers = { "Content-Type": "application/json",
"x-app-id": '672c6c24',
"x-app-key": '6f4ba779b23cefe6adf151de7860fc87' }
Собираем тело запроса, который включает переведенный запрос и параметра timezone (оставим по дефолту US/Eastern, пока это неважно):
# Тело запроса
body = { "query": query,
"timezone": "US/Eastern" }
3. Отсылаем POST-запрос на сервер Nutritionix, куда включаем URL, заголовки и тело запроса, а его ответ сохраняем в переменную response:
# Выполнение POST-запроса
response = requests.post(natural_url, json=body, headers=headers)
4. Проверяем что запрос удался и вернул код 200 (OK), переводим его в JSON и получаем значение по ключу 'foods', где как раз и лежит список словарей с информацией по каждому продукту:
if response.status_code == 200:
data = response.json() foods = data["foods"]
Для большего удобного я создал класс, который представляет каждый продукт, полученный из запроса. В его конструктор мы просто передаем словарь из списка словарей и заполняем атрибуты:
class NutritionixFood: def __init__(self, food:dict) -> None:
self.food_name = food.get('food_name')
self.brand_name = food.get('brand_name') self.serving_qty = food.get('serving_qty')
self.serving_weight_grams = food.get('serving_weight_grams')
self.nf_calories = food.get('nf_calories')
self.nf_total_fat = food.get('nf_total_fat')
self.nf_saturated_fat = food.get('nf_saturated_fat')
self.nf_cholesterol = food.get('nf_cholesterol')
self.nf_total_carbohydrate = food.get('nf_total_carbohydrate')
self.nf_dietary_fiber = food.get('nf_dietary_fiber')
self.nf_sugars = food.get('nf_sugars')
self.nf_protein = food.get('nf_protein')
self.nf_potassium = food.get('nf_potassium')
self.nf_p = food.get('nf_p')
self.full_nutrients = food.get('full_nutrients')
self.photo_url = food.get('photo', {}).get('highres')
self.barcode = food.get('upc')
5. Осталось только воспользоваться генератором списка и передать каждый словарь из списка словарей в конструктор класса NutritionixFood. В итоге мы получим список объектов данного класса.
result = [NutritionixFood(food) for food in foods]
Готово! Весь код можете просмотреть на гитхаб:
Теперь осталось только объединить это с библиотекой telebot:
Запросить ввод текста с перечислением съеденного
Перевести текст на английский
Отправить текст через API Nutritionix
Получить ответ сервера
"Конвертировать" ответ сервера в список объектов класса NutritionixFood
Вывести список продуктов пользователю, переведя названия продуктов с английского на русский:
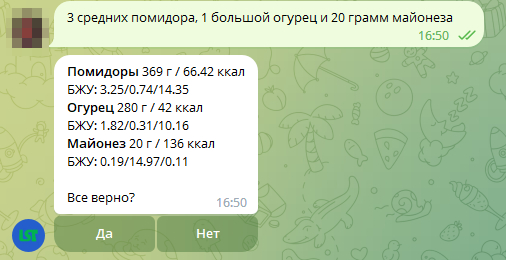
Как я говорил выше, кроме основных составляющих пищи, которые в основном нас и интересуют (КБЖУ), данный сервис предоставляет еще кучу других. Некоторые из них, например сахар или калий, хранятся в атрибутах класса в готовом виде (nf_sugars и nf_potassium соответственно), но основная часть содержится в атрибуте full_nutrients со списком словарей, каждый из которых имеет следующие ключи:
ID нутриента
Его количество
Например, для запроса "3 boiled eggs" мы получим следующее:
[ {"attr_id": 203, "value": 18.87}, {"attr_id": 204, "value": 15.915}, {"attr_id": 205, "value": 1.68}, {"attr_id": 207, "value": 1.62}, {"attr_id": 208, "value": 232.5}, {"attr_id": 221, "value": 0}, {"attr_id": 255, "value": 111.93}, {"attr_id": 262, "value": 0}, {"attr_id": 263, "value": 0}, {"attr_id": 268, "value": 973.5}, {"attr_id": 269, "value": 1.68}, {"attr_id": 291, "value": 0}, {"attr_id": 301, "value": 75}, {"attr_id": 303, "value": 1.785}, {"attr_id": 304, "value": 15}, {"attr_id": 305, "value": 258}, {"attr_id": 306, "value": 189}, {"attr_id": 307, "value": 186}, {"attr_id": 309, "value": 1.575}, {"attr_id": 312, "value": 0.0195}, {"attr_id": 313, "value": 7.2}, {"attr_id": 315, "value": 0.039}, {"attr_id": 317, "value": 46.2}, {"attr_id": 318, "value": 780}, {"attr_id": 319, "value": 222}, {"attr_id": 320, "value": 223.5}, {"attr_id": 321, "value": 16.5}, {"attr_id": 322, "value": 0}, {"attr_id": 323, "value": 1.545}, {"attr_id": 324, "value": 130.5}, {"attr_id": 326, "value": 3.3}, {"attr_id": 328, "value": 3.3}, {"attr_id": 334, "value": 15}, {"attr_id": 337, "value": 0}, {"attr_id": 338, "value": 529.5}, {"attr_id": 401, "value": 0}, {"attr_id": 404, "value": 0.099}, {"attr_id": 405, "value": 0.7695}, {"attr_id": 406, "value": 0.096}, {"attr_id": 410, "value": 2.097}, {"attr_id": 415, "value": 0.1815}, {"attr_id": 417, "value": 66}, {"attr_id": 418, "value": 1.665}, {"attr_id": 421, "value": 440.7}, {"attr_id": 430, "value": 0.45}, {"attr_id": 431, "value": 0}, {"attr_id": 432, "value": 66}, {"attr_id": 435, "value": 66}, {"attr_id": 454, "value": 0.9}, {"attr_id": 501, "value": 0.2295}, {"attr_id": 502, "value": 0.906}, {"attr_id": 503, "value": 1.029}, {"attr_id": 504, "value": 1.6125}, {"attr_id": 505, "value": 1.356}, {"attr_id": 506, "value": 0.588}, {"attr_id": 507, "value": 0.438}, {"attr_id": 508, "value": 1.002}, {"attr_id": 509, "value": 0.7695}, {"attr_id": 510, "value": 1.1505}, {"attr_id": 511, "value": 1.1325}, {"attr_id": 512, "value": 0.447}, {"attr_id": 513, "value": 1.05}, {"attr_id": 514, "value": 1.896}, {"attr_id": 515, "value": 2.466}, {"attr_id": 516, "value": 0.6345}, {"attr_id": 517, "value": 0.7515}, {"attr_id": 518, "value": 1.404}, {"attr_id": 601, "value": 559.5}, {"attr_id": 606, "value": 4.9005}, {"attr_id": 607, "value": 0}, {"attr_id": 608, "value": 0}, {"attr_id": 609, "value": 0.0045}, {"attr_id": 610, "value": 0.0045}, {"attr_id": 611, "value": 0.0045}, {"attr_id": 612, "value": 0.0525}, {"attr_id": 613, "value": 3.5235}, {"attr_id": 614, "value": 1.242}, {"attr_id": 617, "value": 5.5875}, {"attr_id": 618, "value": 1.782}, {"attr_id": 619, "value": 0.0525}, {"attr_id": 620, "value": 0.2235}, {"attr_id": 621, "value": 0.057}, {"attr_id": 626, "value": 0.465}, {"attr_id": 627, "value": 0}, {"attr_id": 628, "value": 0.045}, {"attr_id": 629, "value": 0.0075}, {"attr_id": 630, "value": 0.0045}, {"attr_id": 631, "value": 0}, {"attr_id": 645, "value": 6.1155}, {"attr_id": 646, "value": 2.121}, ]
Чтобы сопоставить attr_id с реальным "веществом" необходимо обратиться к справочной таблице:
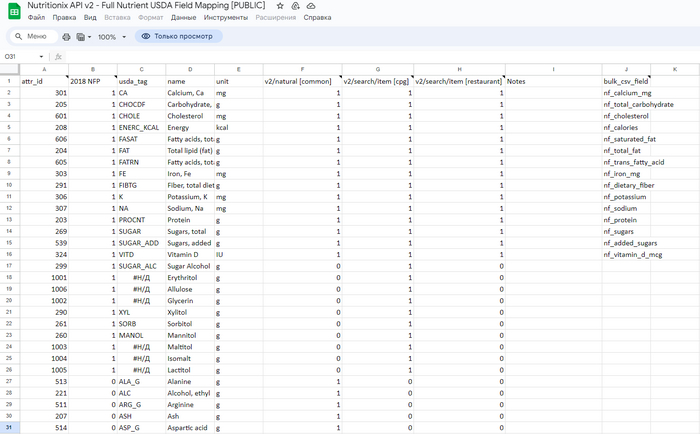
Здесь нас интересуют лишь самые основные колонки: A (ID), D (Название) и E (единица измерения). Для простоты взаимодействия можно скопировать данную таблицу в Excel, а уже из него спарсить все это дело в таблицу БД. На всякий случай оставил тег USDA (может когда-то пригодится) и добавил колонку ru_name, в которую потом можно будет "запихнуть" русское название нутриента, прогнав колонку name, к примеру, через тот же самый googletrans.
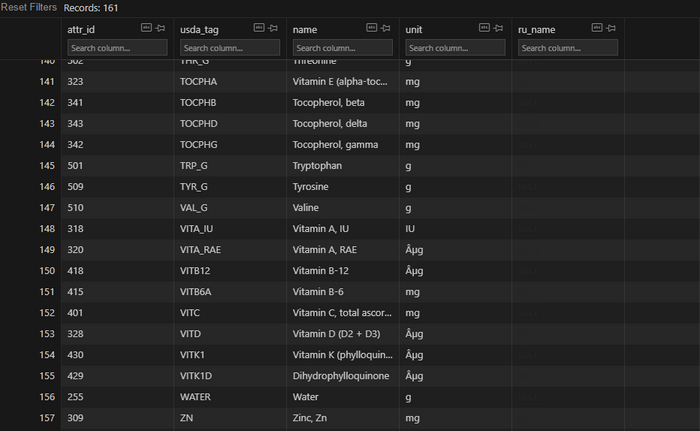
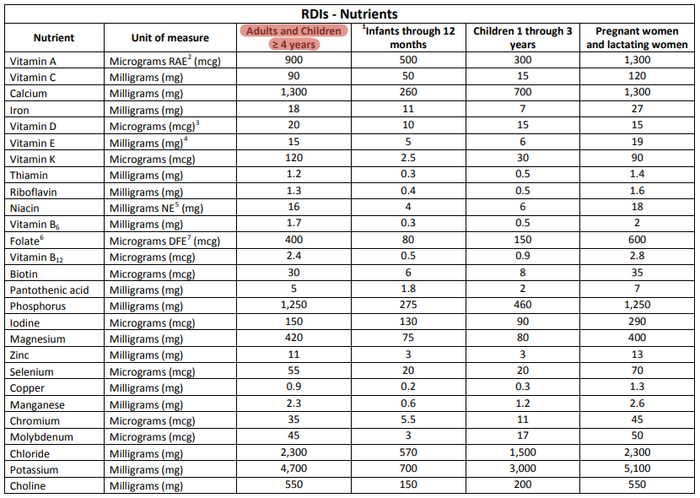
Кстати, в этой же справочной таблице на 2 листе есть ссылка на документ от FDA (Агентство Министерства здравоохранения и социальных служб США), где прописаны нормы потребления нутриентов. Здесь в основном нас интересует колонка 3 (взрослые и дети >= 4 лет),ну а кого-то 6 (беременные и кормящие женщины).
Вернемся к коду и создадим класс, представляющий каждый нутриент:
class NutritionixNutrient: def __init__(self, usda_tag, name, unit, ru_name) -> None:
self.usda_tag = usda_tag
self.name = name
self.ru_name = ru_name
self.unit = unit self.value = None
И начинаем проходиться по тому самому списку словарей
[ {"attr_id": 203, "value": 18.87}, {"attr_id": 204, "value": 15.915}, {"attr_id": 205, "value": 1.68}, {"attr_id": 207, "value": 1.62}, {"attr_id": 208, "value": 232.5}, ... ]
Подобным образом:
# Получаем список словарей из объекта NutritionixFood
full_nutrients = food.get('full_nutrients')
# Создаем пустой список для объектов NutritionixNutrient
food_nutrients = []
# Проходимся по каждому словарю из списка словарей
for nutrient in full_nutrients:
# Получаем из БД инфо о нутриенте по attr_id и пихаем ее в конструктор класса #NutritionixNutrient food_nutrient=NutritionixNutrient(db.get_nutritionix_nutrient_info(nutrient_info.get('attr_id')))
# Отдельно устанавливаем количество нутриента
food_nutrient.value = nutrient_info.get('value')
# Добавляем объект класса NutritionixNutrient в список
food_nutrients.append(food_nutrient)
# А тут проводим какие-либо манипуляции с food_nutrients
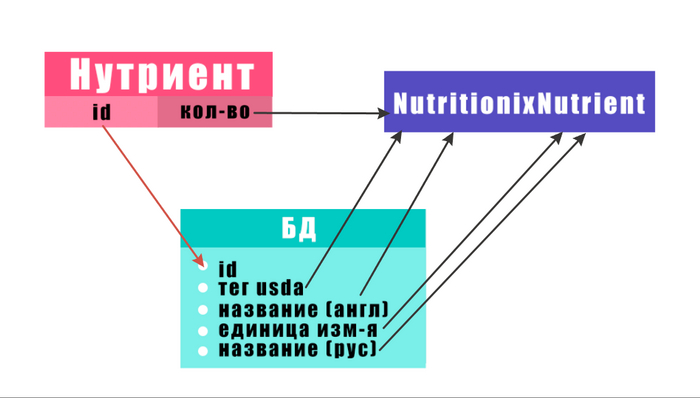
В итоге получим список объектов класса NutritionixNutrient, каждый из которых содержит информацию о конкретном нутриенте из продукта. А имея информацию обо всех нутриентах, потребленных в течение определенного периода уже можно сделать выводы о его диете (много соли, мало витамина B и т.д.) и дать соответствующие рекомендации, опираясь на вышеописанные нормы FDA или национальные.
Затестить функционал по добавлению продуктов питания можете в данном чат-боте совершенно бесплатно.
Кстати, а почему бы не облегчить жизнь пользователю и дать ему возможность просто записать голосовое сообщение со всем съеденным? Поговорим об это в части №3...

Если не можешь найти дорогу, иди туда, где её нет, и оставь след - Ральф Уолдо Эмерсон
Попользовавшись множеством приложений вида «калькулятор калорий» и «трекер тренировок», пришел к выводу, что функционал подобных приложений не так широк, как этого бы хотелось, а доступ к более‑менее продвинутому функционалу стоит несоразмерно много для российского кошелька. Философия популярных приложений часто такова: вот, отслеживай съеденные калории, но чтобы контролировать соотношение БЖУ, отслеживать потребление воды и т. д. — плати деньгу. С вас 20 баксов в месяц, но только сегодня всего за 199$ можешь получить доступ на год. Ну что, пробиваем? (*утрированно*)
Касательно скудного функционала: есть прекрасные калькуляторы калорий (дневники питания), которые хоть и за дорого, но справляются со своей основной задачей — калькулировать эти самые калории + БЖУ. Про микроэлементы или хотя бы клетчатку как-нибудь промолчим. Но что касается физической активности, то она в подобных приложениях идет, как кажется, в небольшой довесок к основному функционалу, без какой-либо глубокой проработанности. Еще один пример: есть список видов физической активности — можешь их добавить, указав продолжительность, мы примерно рассчитаем, сколько калорий ты потратил и запишем в дневник тренировок. (Хотя такие расчеты очень примерны и мало отражают действительность, в принципе, как и расчет калорий, который потребил организм, но сейчас не об этом). Хочешь программу тренировок? Отслеживать каждый подход? Получить подробную статистику и рекомендации? — сори, у вас документов нету, такого функционала не подвезли.
Еще один неудобный момент — отсутствие кроссплатформенности. Лично мне не всегда удобно пользоваться приложением на телефоне. Если я взял какую-то еду и сел за компьютер, мне не очень комфортно лезть в телефон и заносить ее в приложение. Куда удобнее было бы работать, не отрываясь, на том же ПК, открыв, например, сайт того же самого сервиса. Однако, популярные калькуляторы калорий в основном базируются лишь на одном устройстве. Хотя, если вы стоите на кухне и что-то готовите, то заносить продукты на телефоне — самый удобный вариант.
— Почему чат‑бот?
Я не замечал чат-ботов схожего функционала, поэтому пришла идея сделать свой (может быть, плохо искал). Встречал боты со всякими калькуляторами для расчета КБЖУ и всего такого, однако такой скудный функционал нам неинтересен. Мне было нужно что-то единое, где в одной «пачке» — дневники питания и тренировок.
Также здесь мы сразу обрубаем на корню проблему с кроссплатформенностью, так как приложение Telegram можно открыть на телефоне, компьютере или же использовать веб-версию в браузере.
Единственный весомый минус при таком подходе заключается в том, что мы ограничены в плане интерфейса. Какой функционал нам дал ТГ, тем и пользуемся: 2 вида кнопок, команды, сообщения и т. д. Однако, несмотря на это, даже в таком случае возможно сделать что-то максимально удобное для пользователя.
А вот весомый плюс — легкость и быстрота разработки. Есть готовый интерфейс, а тебе остается только определить кнопки, команды и сообщения, который будет слать и принимать бот. Быстро, дешево и сердито.
— Почему Telegram?
Во-первых, до этого я уже имел опыт создания ботов различной по сложности логики, да и просто пользоваться мне им приятнее, чем тем же Вконтакте . Хотя ничто не мешает в будущем расшириться и создать бота еще и под данную соцсеть.
"Перед тем как начать писать код, давайте ответим на вопрос: «А что же мы собираемся сделать?»" - GPT-3.5
Начальной задачей, как это и должно быть в любом деле, было необходимо сделать минимально жизнеспособный продукт — чат-бот, который содержит лишь самый основной функционал дневника питания и дневника тренировок, а также минимально необходимую статистику по каждому из них.
Что касается монетизации, то было решено сделать классическую систему подписок по периодам: неделя, месяц и т. д. Но перед тем как её купить, юзер может получить бесплатные 7 дней, а потом уже решать — надо это ему или нет. Цены решено было выбрать достаточно демократичные, чтобы стоимость подписки была не более той, которую пользователь привык тратить на другие сервисы для просмотра фильмов или прослушивания музыки. То есть должна получиться эдакая «бытовая» трата, которую человеку не жалко отдать за полезный продукт — 200-300 рублей в месяц.
Для реализации данного функционала решено было выбрать API ЮMoney (бывшие Яндекс. Деньги), взаимодействие с которым велось посредством библиотеки yoomoney от Алексея Коршука.
В начале было решено сконцентрироваться на дневнике тренировок, а уже после переходить к дневнику питания (он же калькулятор калорий), так как реализация последнего виделась более трудной (оказалось, не так чтобы очень сильно) .
Чтобы юзер смог занести какую-либо физическую активность, нужно где-то достать список ее видов, а это оказалось не так просто, так как нормальных готовых баз на русском языке, по всей видимости, просто нет. Поэтому пришлось строить ее самостоятельно, а так как делать это очень долго, нужно процесс автоматизировать. При этом в сети куча сайтов с каталогами физических упражнений, а это значит — заводим свой Selenium и начинаем парсить. В качестве цели был выбран не топовый, но более-менее популярный сервис DailyFit, где страницы упражнений сжатые, без воды и лишь с основной информацией, которая нам нужна на этапе создания МЖП:
Название
Целевая группа мышц
Дополнительные группы мышц
Вид упражнения (силовое, кардио, растяжка или плиометрическое)
Тип упражнения (базовое, изолирующее) — только для силовых упражнений
Необходимое оборудование (штанга, гиря и т. д.)
Уровень сложности
Также на каждой странице есть симпотишные фото выполнения каждого упражнения, при этом в 2 вариантах: мужское исполнение и женское. Все фото мы парсим тоже, и оба вида — потом будем показывать фото соответственно полу пользователя. При этом нам не нужно никуда сохранять каждое фото, достаточно только ссылки на него.
Всего на момент парсинга каталог упражнений содержал 594 позиции, что довольно прилично и охватывает, наверное, почти все возможные виды, которые может искать пользователь. Теперь наша БД (в моем случае на SQLite ) заполнена кучей упражнений, да еще и по несколько фото к каждому (целых 2582 штуки). Все ссылки на фото хранятся в отдельной таблице и каждое из них имеет колонку с идентификатором пола (male или female) и ID упражнения, к которому оно относится. Ниже можете просмотреть, какие у нас получились таблицы:
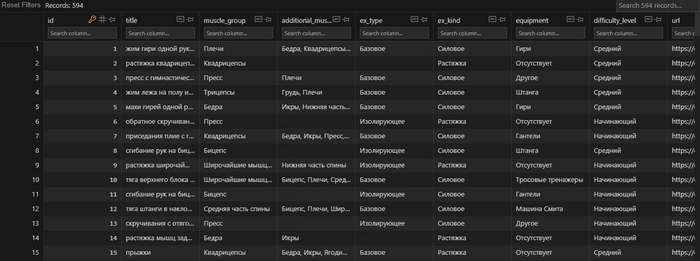
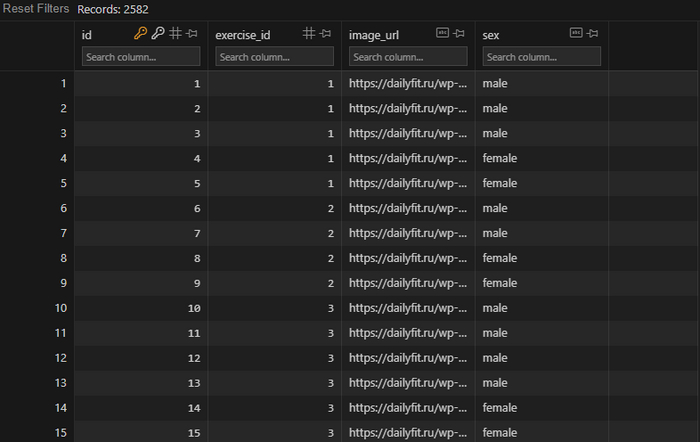
Если вдруг кому понадобится парсер, можете найти его ниже. Хотя это сделанный быстро и на коленке код, но вполне рабочий.
Не ручаюсь за точность характеристик каждого упражнения на данном сервисе, но для начала этого будет достаточно.
Теперь юзеру будет из чего выбрать, осталось только ему их правильно предложить. Об этом и поговорим далее…
База данных готова, осталось определить, как пользователь будет искать то самое упражнение из общей кучи. Самое простое, что можно сделать — это реализовать механизм поиска по названию. Ввел пользователь запрос «жим», а мы ему:
И еще 70 видов физических упражнений из нашей БД, в которой есть слово «жим». Сделать такую выборку очень просто, используя простейший функционал нашей СУБД SQLite3, а именно при помощи оператора LIKE:
SELECT * FROM available_exercises WHERE title LIKE '%жим%';
Этот оператор осуществляет поиск по подстроке, а это значит, что к списку выше прибавятся различные отжимания. Также данного вида поиск чувствителен к окончаниям слова, то есть если мы введем «разгибания», то мы не получим в результате упражнений наподобие «Разгибание на трицепс на верхнем блоке».
Простыми словами, подстрока — это небольшая часть строки, которая содержится внутри этой строки. Когда мы говорим о строках, подстрока представляет собой набор символов, которые находятся внутри другой, более длинной строки.
Это простейший вариант поиска, который несложен в исполнении, но неудобен для пользователя, так как приходится долго искать нужное упражнение в огромном списке. Также стоит учитывать ограничение Телеграма на длину сообщения, ведь если по запросу придет большой список упражнений, и вы попытаетесь его отправить, это вызовет ошибку.
Нужно было как-то улучшить релевантность поиска, чтобы сверху списка оказались те упражнения, которые, скорее всего, и нужны пользователю. Для этого пришлось по-быстрому разработать несложный алгоритм из нескольких шагов, который показал себя вполне годно:
Перед тем как что-то искать, необходимо удостовериться в том, что юзер написал запрос корректно и без ошибок («жим», а не «жым»). Для этого воспользуемся сервисом Яндекс.Спеллер, который исправляет в тексте орфографические ошибки. Для взаимодействия с API данного сервиса нам поможет библиотека pyaspeller.
Теперь решаем проблему с окончаниями, о которой говорилось выше. Что для этого нужно сделать? Правильно — попросту убрать окончания, получив основу слова (или же нескольких слов), то есть провести стемминг. В этом нам поможет библиотека nltk. Теперь, если юзер ввел «разгибание гантелей», то в запросе будет «разгибан гантел».
Теперь можно начать сам поиск по БД. Здесь без изменений — используем тот же оператор LIKE. Если в запросе несколько слов, используем оператор AND, тогда в выдаче получим только те упражнения, где в названии есть сразу обе подстроки (и «разгибан» и «гантел» сразу).
Теперь в ход идут метрики, по которым мы поднимаем наверх те упражнения, которые с большей вероятностью интересны пользователю. Первый из них — это коэффициент Жаккара (насколько название упражнения приближено к запросу пользователя). К примеру, юзер ввел «жим штанги лежа» и благодаря использованию этого коэффициента список упражнений будет таким:
Жим штанги лежа
Жим штанги лежа узким хватом
Жим штанги лежа широким хватом
Следующая метрика — «популярность» упражнения, которая складывается из количества просмотров и количества фактических выполнений упражнения другими пользователями. Как можно полагать, количество выполнений является более приоритетной цифрой, поэтому число просмотров и число выполнений должны иметь разный вес. В качестве теста было распределить его так: просмотры — 0.3, а выполнения — 0.7.
Теперь осталось провести сортировку списка упражнений по 2 метрикам:
search_results.sort(key=lambda ex: (ex.popularity, ex.similarity), reverse=True)
На заключительном этапе нужно проверить, что длина сообщения с упражнением не будет выходить за допустимые пределы. В моем случае каждая строка с упражнением состоит из id упражнения в БД с косой чертой (чтобы можно было нажать на него и выбрать упражнение, а не вводить вручную) и его названия. Соответственно, нам нужно получить длину каждой строки упражнения по следующей формуле: длина id + длина названия + 2 (косая черта и пробел между ID и названием). Далее складываем длину всех строк и проверяем, будет ли длина сообщения выше допустимого предела (4 096 символов) и если больше — убираем последнюю строку и далее по кругу, пока длина не впишется в лимит. Если в сообщении помимо списка есть еще текст — учитываем и его длину.
На этом все, осталось только послать сообщение со списком упражнений пользователю. Например, такое:
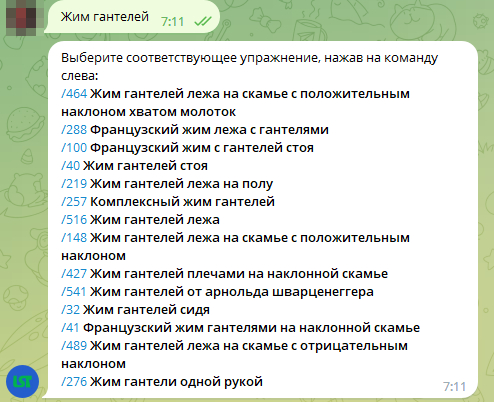
Косые черты рядом с ID упражнения в данном случае помогают сделать команду, которая при нажатии автоматически отправляется боту. Далее, получив ID упражнения в БД, мы можем вывести его подробную информацию. К примеру, такую:
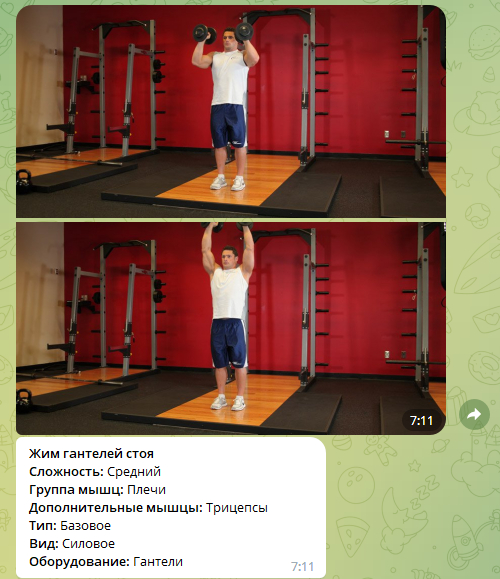
С поиском нужного упражнения мы закончили, теперь давайте поговорим о том, как в принципе строится дневник тренировок.
Здесь все относительно просто: пользователь начинает тренировку, выбирает упражнения и вносит подходы по каждому упражнению. Соответственно, нам нужно создать 3 таблицы в нашей базе данных: Тренировки, Упражнения и Подходы. При этом упражнение хранит ID тренировки, а подход — ID упражнения в ее рамках.
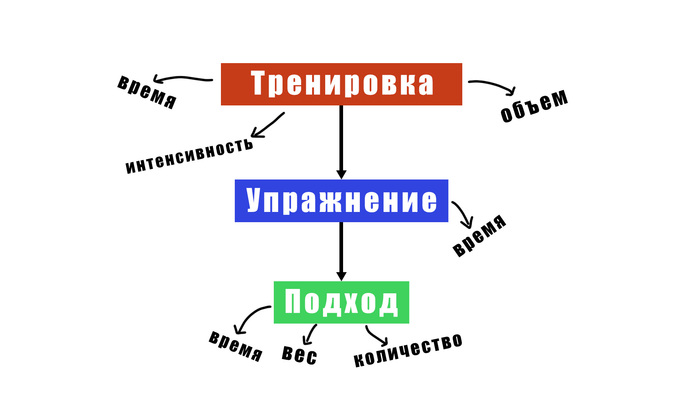
В рамках упражнения имеется сообщение с всеми подходами: вес отягощения, количество повторений и время выполнения (не уверен, что оно будет многим интересно).

А в сводке по всей тренировке выводим все упражнения, количество подходов и время выполнения всего упражнения (немного поинтереснее):

По окончании тренировки можем просмотреть краткую сводку по ее длительности объему, интенсивности и количеству упражнений:

Не так интересно отслеживать отдельную тренировку, как просмотреть статистику по всем и оценить общий прогресс.
На первое время было решено сделать статистику по 3 метрикам, которые как раз и есть в сводке по окончании тренировки: объем, интенсивность и длительность.
Просматривать статистику в виде текста не так интересно, куда лучше смотреть на график, где сразу понятно, что куда катится. В этом нам поможет библиотека matplotlib. Вот то, что мы получаем на выходе:
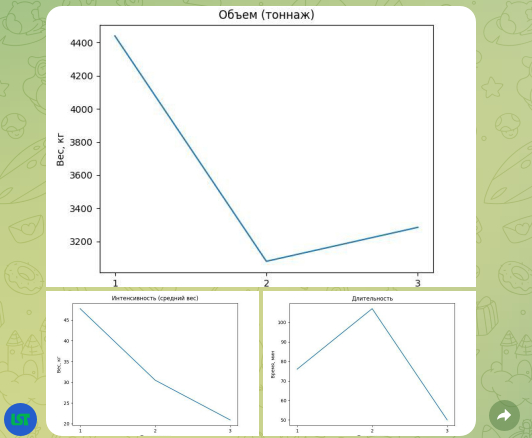
На этом первая часть материала подошла к концу. Здесь я описал лишь личный опыт, без претензий на что-либо. Не стесняйтесь и расскажите в комментариях, какие моменты и как стоит улучшить.
Можете затестить функционал чат-бота совершенно бесплатно, подписка не нужна.
В следующей статье рассмотрим организацию дневника питания и его интересные фишки. Например, такие: