PG_HAZEL : Основная гипотеза корреляционного анализа ожиданий СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

Основа это самое главное.
Гипотеза
Сокращение периода, когда серверный процесс, обрабатывающий SQL-запрос к системе управления базами данных (СУБД), сталкивается с событием ожидания, напрямую влияет на скорость выполнения запроса. Чем меньше времени процесс простаивает в ожидании, тем быстрее завершается SQL-запрос.
При многократном повторении запросов, минимизация времени ожидания приводит к увеличению количества выполненных запросов за единицу времени. В конечном итоге, это позволяет предоставить клиенту больший объем полезной информации за тот же период. Таким образом, снижение задержек в обработке SQL-запросов ведет к повышению общей производительности системы.
Доказательство гипотезы
Общая основа для доказательства
Любой SQL-запрос, выполняемый серверным процессом СУБД, проходит через два типа фаз:
Активная обработка (CPU Bound): Процессор выполняет вычисления — парсинг запроса, построение плана выполнения, соединение таблиц, сортировку данных и т.д.
Ожидание (I/O Bound или Wait Events): Процесс приостанавливает выполнение и ждет наступления какого-либо события. Ключевые виды ожиданий:
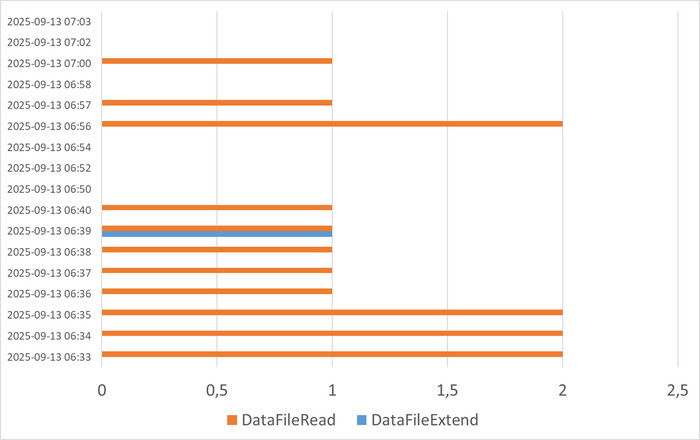
Дисковый ввод/вывод (I/O): Ожидание чтения данных с диска ( страницы с данными, индексы) или записи журналов (например, Transaction Log).
Блокировки (Locking): Ожидание, пока другая транзакция освободит нужную блокировку на строку или таблицу.
Сетевые задержки (Network): Ожидание получения следующего пакета данных от клиента или отправки ему результатов.
Ожидание ресурсов CPU (CPU Queue): Процесс готов к выполнению, но все ядра процессора заняты другими процессами.
Общее время выполнения запроса (T_total) можно выразить формулой:
T_total = T_active + T_wait
где:
T_active — совокупное время активной обработки на CPU.
T_wait — совокупное время всех событий ожидания.
Доказательство части 1: Влияние на скорость выполнения одного запроса
Утверждение: Сокращение периода ожидания напрямую влияет на скорость выполнения запроса.
Доказательство:
Логическое рассуждение:
Из формулы T_total = T_active + T_wait следует, что T_total является функцией от T_wait. Если значение T_wait уменьшается (при прочих равных условиях, т.е. T_active остается неизменным), то значение T_total также уменьшается. Уменьшение T_total и есть увеличение скорости выполнения запроса. Это прямое и линейное следствие.Математическая формализация:
Пусть T_total_1 = T_active + T_wait_1
После оптимизации (например, добавление индекса для уменьшения времени ожидания чтения с диска) время ожидания сокращается: T_wait_2 < T_wait_1
Время активной обработки может незначительно измениться (например, процессорное время на обход индекса может немного вырасти), но в большинстве сценариев оптимизации ожидания это изменение пренебрежимо мало или даже отрицательно (новый индекс эффективнее). Предположим, T_active ~ const.
Следовательно: T_total_2 = T_active + T_wait_2 < T_active + T_wait_1 = T_total_1
Вывод: Время выполнения запроса T_total_2 строго меньше T_total_1.Практическое подтверждение (Архитектура СУБД):
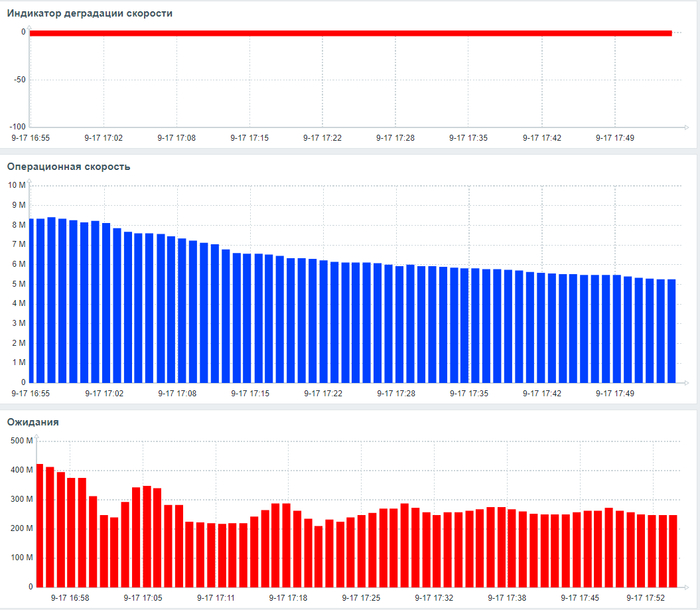
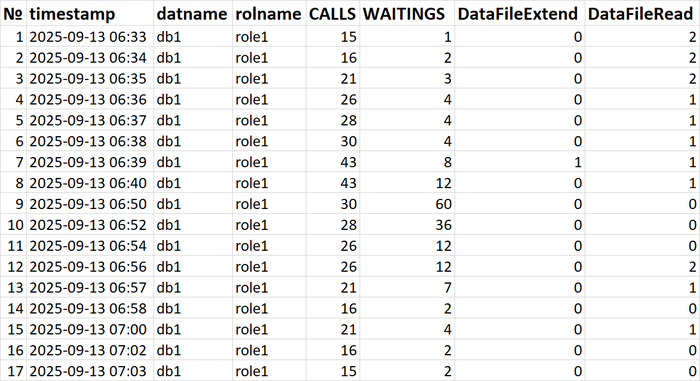
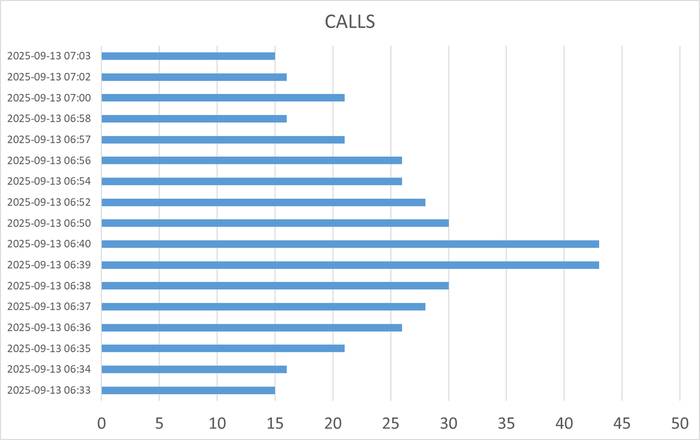
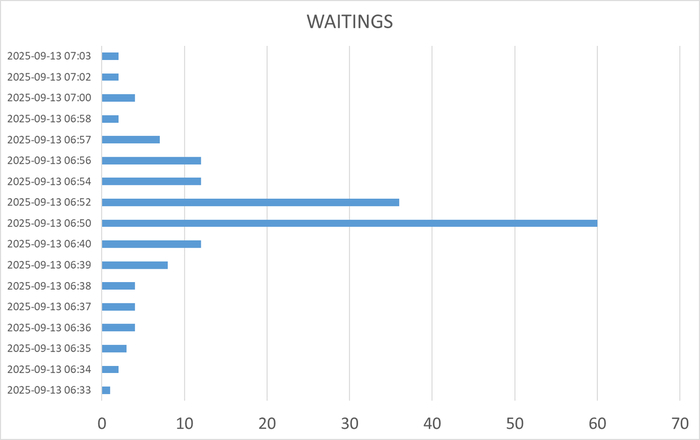
Все современные СУБД (Oracle, SQL Server, PostgreSQL, MySQL) имеют встроенные механизмы диагностики — Мониторинг ожиданий (Wait Event Statistics). Администраторы баз данных используют запросы к системным представлениям (например, sys.dm_os_wait_stats в SQL Server или pg_stat_activity в PostgreSQL), чтобы выявить основные wait events для медленных запросов.
Пример: Если главный тип ожидания — IO (ожидание чтения данных с диска), его сокращение путем добавления оперативной памяти (чтобы кэшировать данные) или добавления более быстрых SSD-дисков всегда приводит к ускорению выполнения целевого запроса. Это эмпирически проверяемый и доказуемый факт.
Заключение по части 1:
Гипотеза верна. Время ожидания является прямой аддитивной составляющей общего времени отклика запроса. Его сокращение напрямую уменьшает общее время выполнения.
Доказательство части 2: Влияние на пропускную способность (throughput)
Утверждение: Минимизация времени ожидания приводит к увеличению количества выполненных запросов за единицу времени.
Доказательство:
Логическое рассуждение и аналогия:
Представьте себе дорогу с единственной заправкой (единый ресурс — дисковая подсистема). Если одна машина (запрос) долго стоит на заправке (ждет I/O), она создает пробку. Машины сзади нее также вынуждены ждать. Если время заправки каждой машины сократить, пропускная способность заправки (диска) возрастет, и за час через пункт пропуска проедет больше машин (запросов).Математическая модель (Теория массового обслуживания):
Сервер БД можно смоделировать как систему массового обслуживания (СМО) с ограниченным числом каналов (работников — CPU ядер, дисковых контроллеров).
Производительность системы (Throughput) — количество успешно обслуженных заявок (запросов) в единицу времени.
Ключевой параметр, влияющий на производительность — Время обслуживания заявки, которое, как мы доказали в части 1, равно T_active + T_wait.
Формулы для СМО (например, для многоканальной системы с ожиданием) показывают, что пропускная способность напрямую зависит от времени обслуживания одной заявки. Чем меньше время обслуживания, тем выше пропускная способность системы.
Throughput ∝ 1 / T_total (Пропускная способность обратно пропорциональна времени выполнения запроса).Формализация:
Пусть N — количество идентичных запросов, которые необходимо выполнить.
Общее время на выполнение всех N запросов в системе без параллелизма: T_system = N * T_total = N * (T_active + T_wait)
Количество запросов, выполняемых в секунду (Throughput): R = N / T_system = 1 / (T_active + T_wait)
Если T_wait уменьшается, знаменатель уменьшается, а значение R (throughput) — увеличивается.
Следствие: За фиксированный промежуток времени T (например, 1 секунда), количество выполненных запросов будет равно R * T = T / (T_active + T_wait). Сокращение T_wait приводит к увеличению этого числа.Практическое подтверждение (Сценарий с блокировками):
Рассмотрим конкурентный доступ.
Было: Запрос A устанавливает эксклюзивную блокировку на строку и выполняет долгую операцию (T_wait для других запросов велико из-за ожидания LCK_M_X). Десятки других запросов, желающих прочитать эту строку, выстраиваются в очередь и ждут.
Стало: Запрос A оптимизирован и выполняется быстрее (сокращается его T_active и, что важно, время удержания блокировки). Он быстрее освобождает ресурс.
Результат: Время ожидания T_wait для каждого из запросов в очереди резко сокращается. Общая система справляется с той же рабочей нагрузкой за меньшее время, либо успевает обработать больше запросов за то же время. Клиент получает больший объем полезной информации за тот же период.
Заключение по части 2:
Гипотеза верна. Сокращение времени ожидания не только ускоряет один запрос, но и уменьшает contention (борьбу за ресурсы) в системе. Это высвобождает ресурсы (CPU, диски, блокировки) для обработки других запросов, что приводит к увеличению общей пропускной способности (throughput) системы.
Итоговое заключение
Обе части гипотезы являются не просто предположениями, а фундаментальными принципами устройства высокопроизводительных систем. Они доказываются через:
Аддитивность времени выполнения запроса.
Обратную зависимость пропускной способности от времени выполнения отдельной задачи.
Эмпирические данные, получаемые через инструменты мониторинга ожиданий СУБД.
Принципы теории массового обслуживания.
Таким образом, основная задача оптимизации производительности БД часто сводится именно к выявлению и сокращению ключевых событий ожидания (wait events).