PG_HAZEL : Комплексный анализ инцидента производительности СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

СУБД это сложная система взаимосвязанных компонент и подсистем.
Задача
Провести комплексный анализ инцидента производительности СУБД:
Чек-лист инфраструктуры
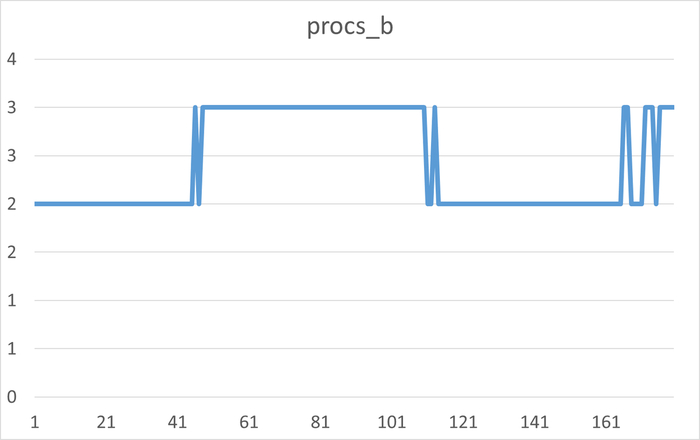
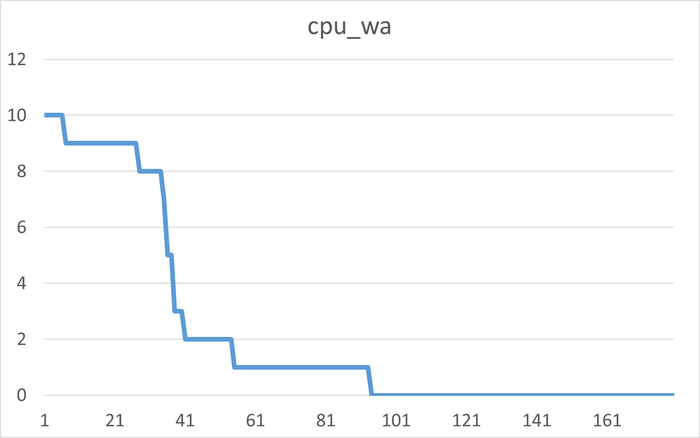
Корреляционный анализ ожиданий СУБД
SQL- запросы - кандидаты для оптимизации
Инцидент производительности СУБД

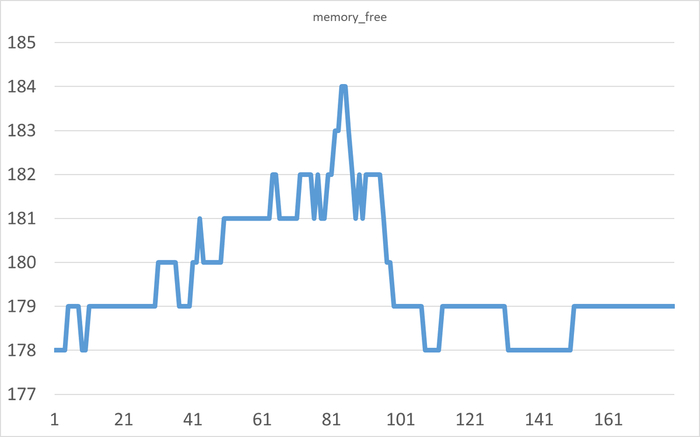
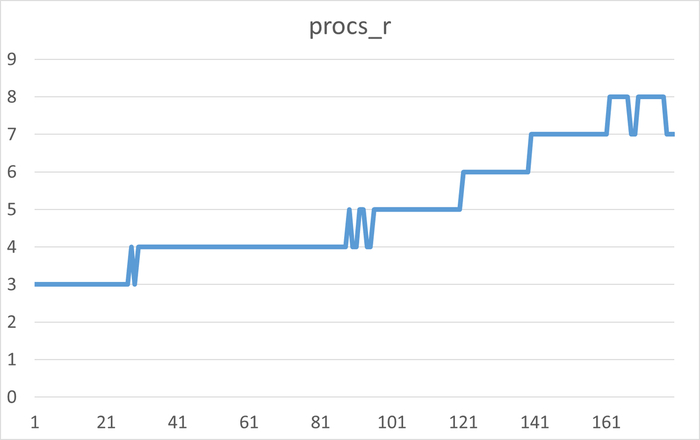
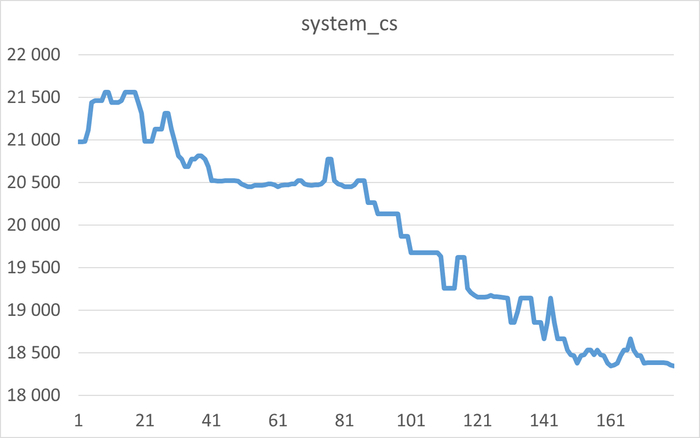
Дашборд панели мониторинга Zabbix
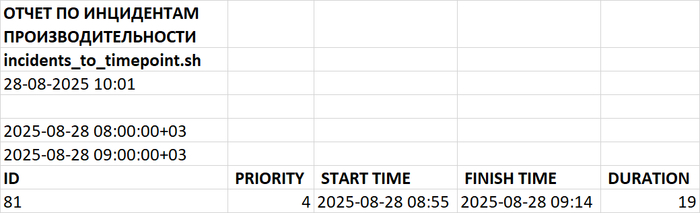
Отчет по инцидентам производительности СУБД
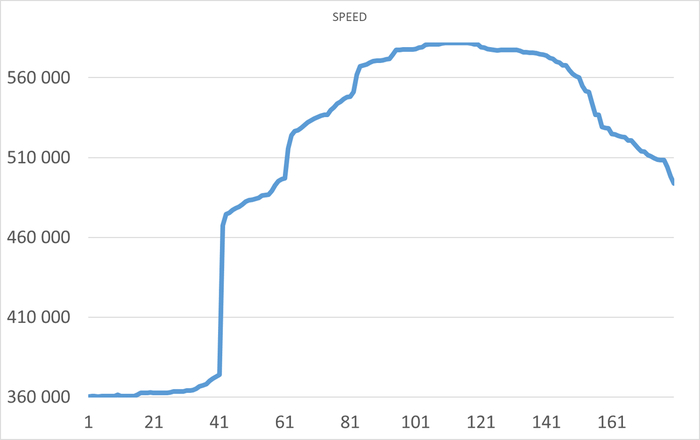
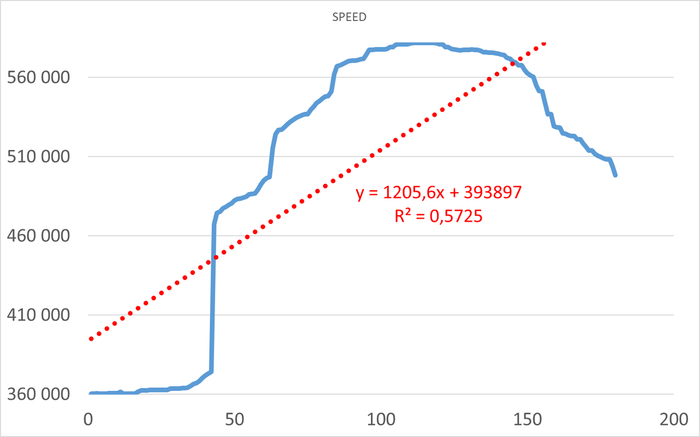
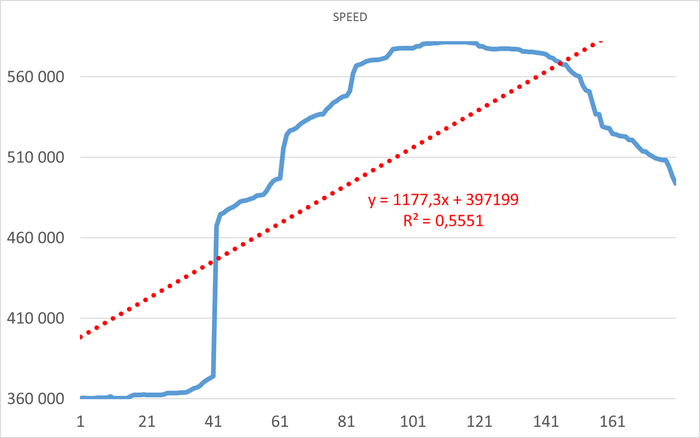
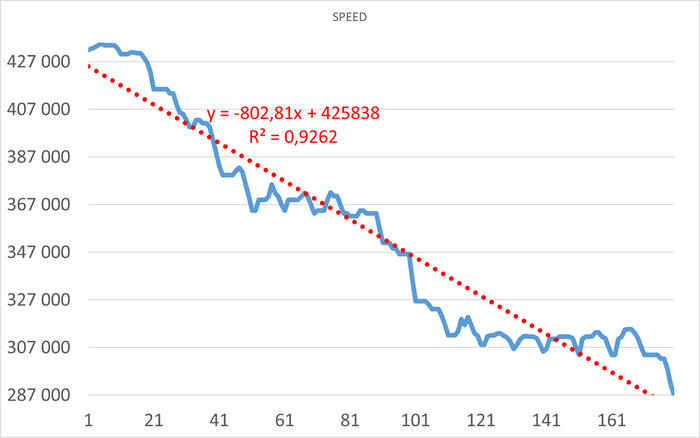
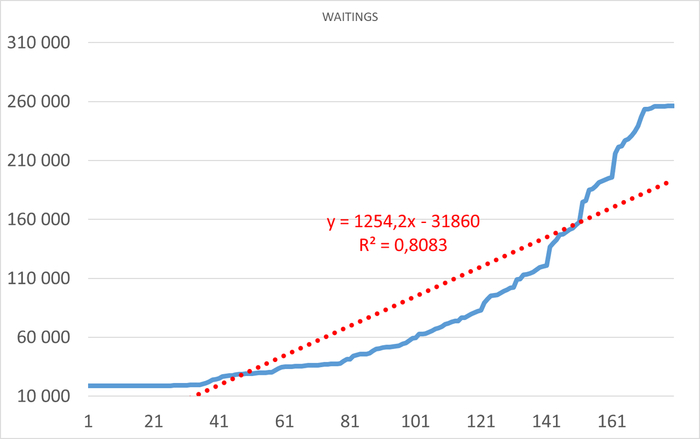
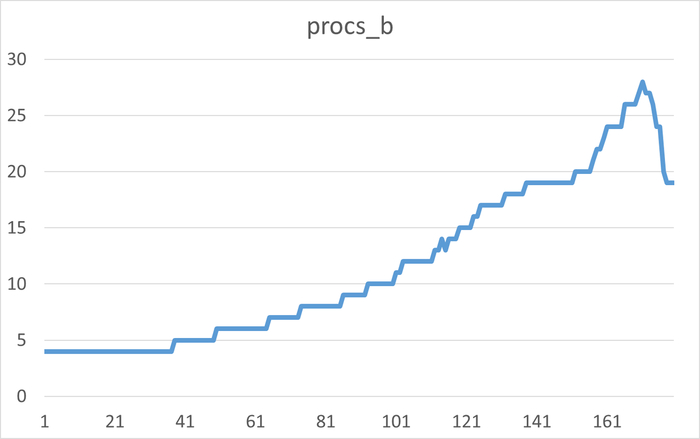
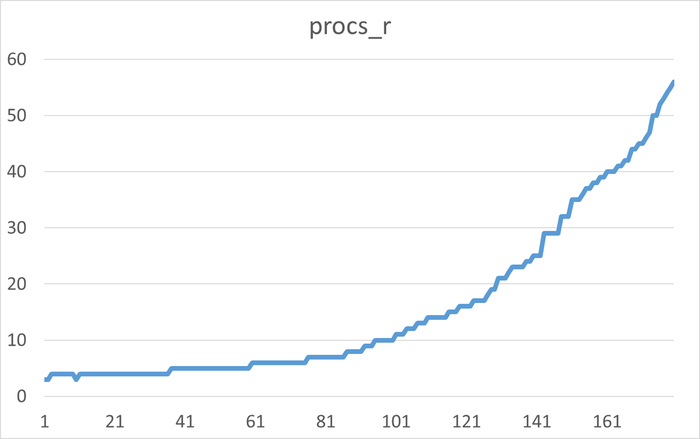
Операционная скорость в течении 1 часа до начала инцидента
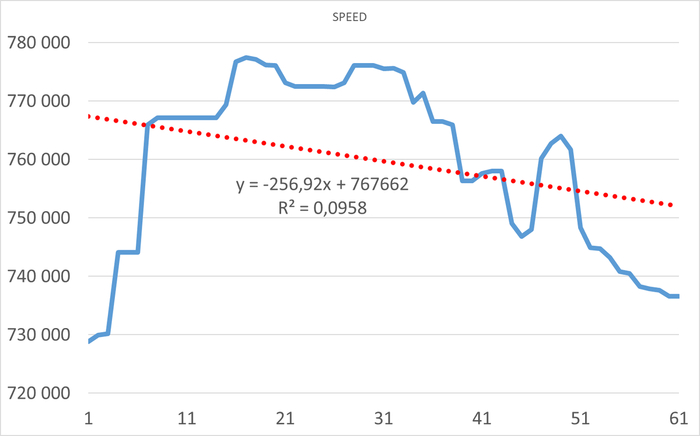
Ось X - точка наблюдения. Ось Y - Операционная скорость . Красный график - Линия регрессии
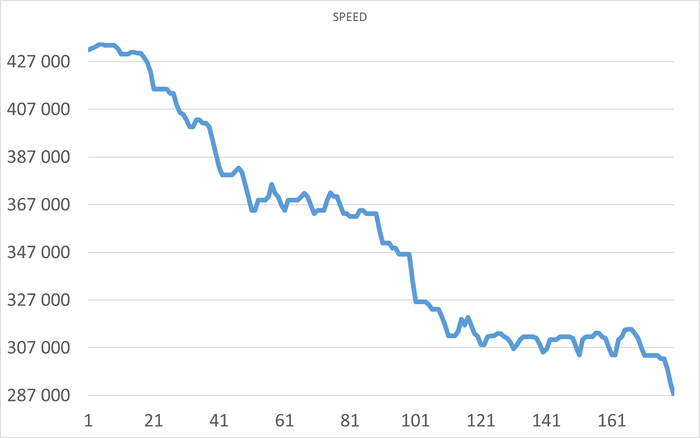
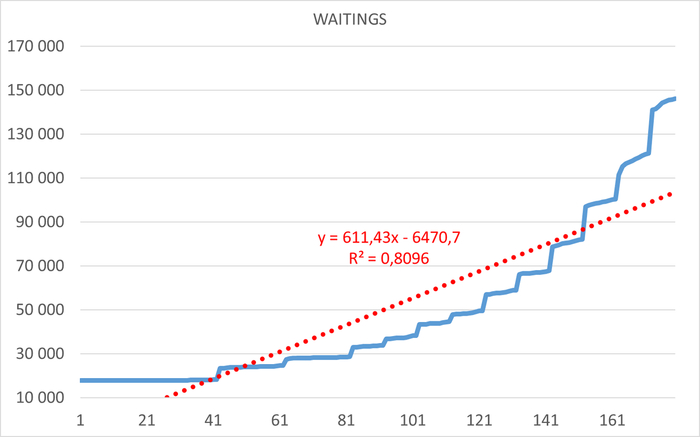
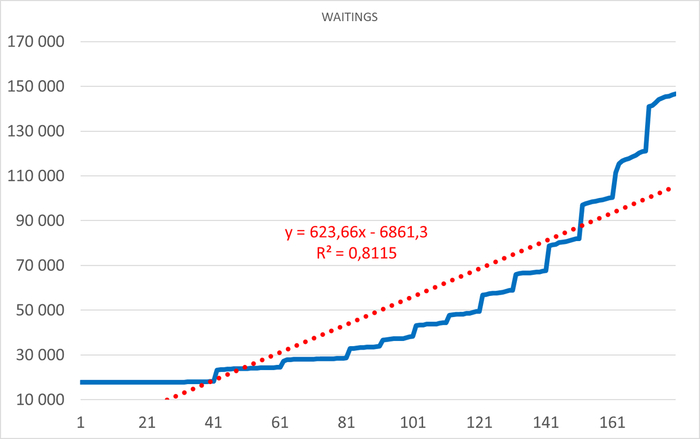
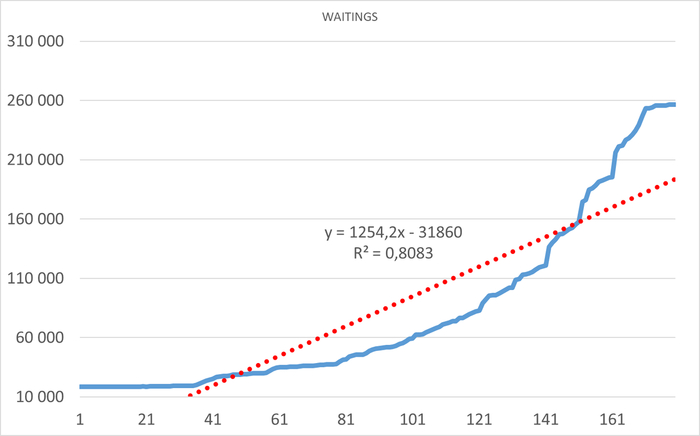
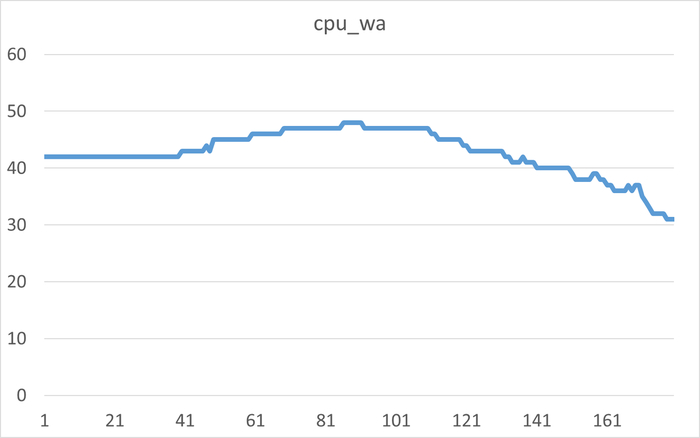
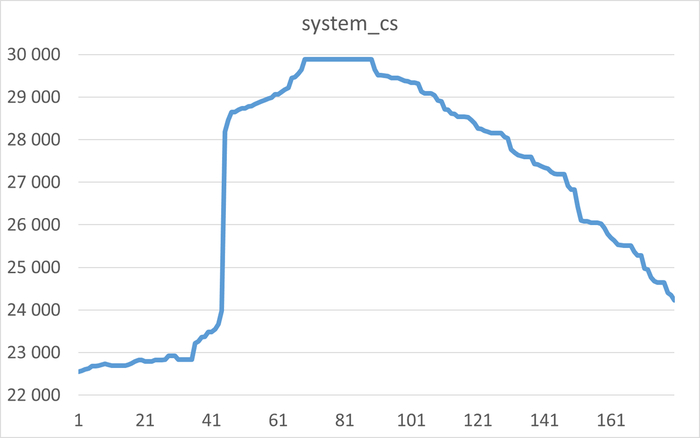
Ожидания СУБД в течении 1 часа до начала инцидента

Ось X - точка наблюдения. Ось Y - Операционная скорость . Красный график - Линия регрессии
Детали и подробности
Показать полностью
4