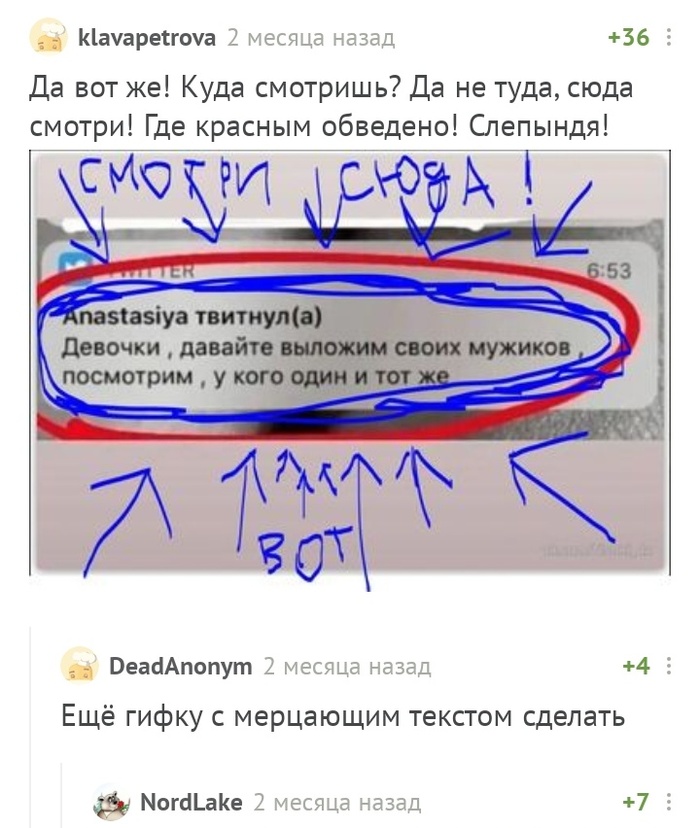
Незабудки




Показать полностью
3
Есть файл эксель с результатами анкетного опроса, в нем несколько десятков столбцов. Точно известно, что часть респондентов проходила опроса больше одного раза.
Как найти дубли? В гугле есть инструкции по написанию формулы для складывания символов в ячейках, предполагается прописать там все столбцы. Допустим, этот способ даже работает, но опухнуть же можно прописывать формулу вручную для пятидесяти названий столбцов.
Есть какие-то еще способы? Именно выделить не дублирующиеся ячейки (они там все дублируются, т.к. ответы стандартные из списка), а полные строки.
Что это можно сделать условным форматированием, мне в теории понятно, хотелось бы конкретики, что там прописывать, для тупых. С макросами тем более, я самостоятельно не напишу, могу только скопировать готовое.
Данные анонимные, есть анкетные вопросы, но никакой сортировки по ФИО сделать нельзя. Максимум - по городу проживания.
Есть ли какоето лосшырение или плагин для Гугл хром чтоб слова- дубликаты виделяло каким то цветом? Тоесть если есть слово или буква, которая имеет в начале и вконце слова пробел - то есть отдельное слово (если есть буква, которая перед и после имеет пробел ее тоже ето касается) Что посоветуете?
Здравствуйте.
@admin, нельзя ли добавить выделение цветом комментирующих пост в котором они были призваны (как ТС)?
Это позволило бы не читать ответы ответов ответов и ответов, а видеть сразу мнение призванных людей.
Желательно разных цветов, так будет удобнее различать фронты диванных войн.