
Память как основа разума: Новая архитектура для языковых моделей
Автор: Денис Аветисян
Исследователи предлагают принципиально новый подход к расширению возможностей больших языковых моделей, наделяя их способностью формировать и использовать структурированную "семантическую рабочую область" для более глубокого понимания и обработки информации.
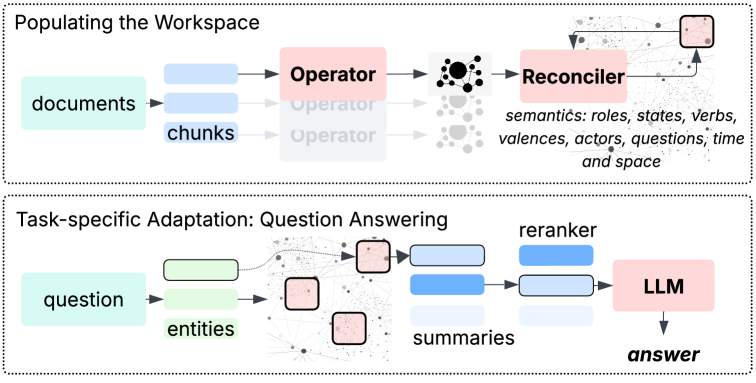
В основе системы лежит процесс формирования эпизодической памяти, где обширные текстовые данные сегментируются на семантически связанные фрагменты, преобразуемые оператором в локальные рабочие пространства, представленные в виде семантических графов, которые затем последовательно интегрируются в единую глобальную память, позволяя при ответах на вопросы извлекать релевантные части этой памяти посредством сопоставления именованных сущностей и реконструкции эпизодических сводок для последующей обработки языковой моделью и генерации ответа.
Предложенная архитектура Generative Semantic Workspace (GSW) позволяет языковым моделям моделировать мир и рассуждать о развивающихся событиях, используя вероятностное представление знаний.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их способность к логическому выводу и отслеживанию событий в длинных текстах остается ограниченной. В работе «Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces» предложена новая архитектура – Генеративное Семантическое Рабочее Пространство (GSW), – позволяющая LLM строить структурированное, интерпретируемое представление развивающейся ситуации и эффективно использовать внешнюю память. Эксперименты на корпусах длиной до 1 миллиона токенов показали, что GSW превосходит существующие подходы к поиску и генерации ответов на 20%, значительно сокращая при этом объем контекста, необходимого для работы модели. Не откроет ли это путь к созданию более разумных агентов, способных к долгосрочному планированию и рассуждению?
Пределы Контекста: Узкое Горлышко в Языковых Моделях
Несмотря на революцию, произведенную большими языковыми моделями (LLM) в обработке естественного языка, их производительность фундаментально ограничена фиксированным окном контекста. Это препятствует решению сложных задач, требующих анализа больших объемов информации и установления долгосрочных зависимостей.
Корень проблемы – квадратичная вычислительная сложность механизмов внимания (O(n2)). При увеличении длины последовательности вычислительные затраты растут экспоненциально, делая эффективную обработку длинных текстов практически невозможной.
Существующие подходы, такие как дополнение извлечением, часто оказываются хрупкими и испытывают трудности с пониманием нюансов. Они полагаются на предварительно извлеченные фрагменты, что может привести к потере контекста или внесению нерелевантных данных.

Для извлечения операторов используется запрос к большой языковой модели (LLM), где контекст формируется путем разбиения текста на фрагменты и последующей генерации фоновой информации с использованием метода, разработанного Anthropic.
Ограничения контекстного окна – не просто техническая проблема, а отражение природы информации: хаос – это не сбой, а язык природы.
Структурированные Знания: RAG и За Его Пределами
Генерация с расширением извлечения (RAG) – перспективный подход к преодолению ограничений контекста LLM. В основе RAG – дополнение LLM релевантными внешними знаниями для генерации более точных и информативных ответов.
Эффективность RAG напрямую зависит от способности находить наиболее подходящую информацию. Часто используется семантическое сходство, вычисляемое на основе плотных векторных представлений фрагментов текста.

В разработанной системе вопросов и ответов (QA) сначала выполняется извлечение ключевых сущностей из запроса, которые затем сопоставляются с соответствующими экземплярами глав в базе знаний GSW посредством сопоставления строк; извлеченные краткие содержания сущностей ранжируются на основе их семантической близости к запросу, что позволяет получить наиболее релевантные ответы от LLM, при этом среднее количество токенов значительно сокращается благодаря лаконичности кратких содержаний и выбору только релевантных глав.
Однако простого извлечения текста недостаточно. Использование структурированных представлений знаний, таких как графы знаний, может значительно повысить точность и возможности рассуждения систем RAG. Результаты исследований показывают, что использование графов знаний позволяет снизить количество используемых токенов на 51% по сравнению с другими методами.
Генеративное Семантическое Пространство: Единая Архитектура
Предложенная модель Generative Semantic Workspace (GSW) – единая вычислительная структура для моделирования мировых знаний в виде структурированной, вероятностной семантики. В основе GSW – представление знаний не как набора фактов, а как динамической системы взаимосвязанных понятий, способной к адаптации и обогащению.
GSW состоит из двух основных компонентов: Operator Framework и Reconciler Framework. Operator Framework интерпретирует локальную семантику в пределах коротких контекстных окон, обеспечивая понимание текущей ситуации. Reconciler Framework интегрирует и обновляет структурированные представления знаний во времени, формируя целостную картину мира. Эти фреймворки функционируют посредством оперирования сущностями – Акторами, Ролями и Состояниями, что предоставляет надежный механизм для представления и рассуждения о динамичных ситуациях.
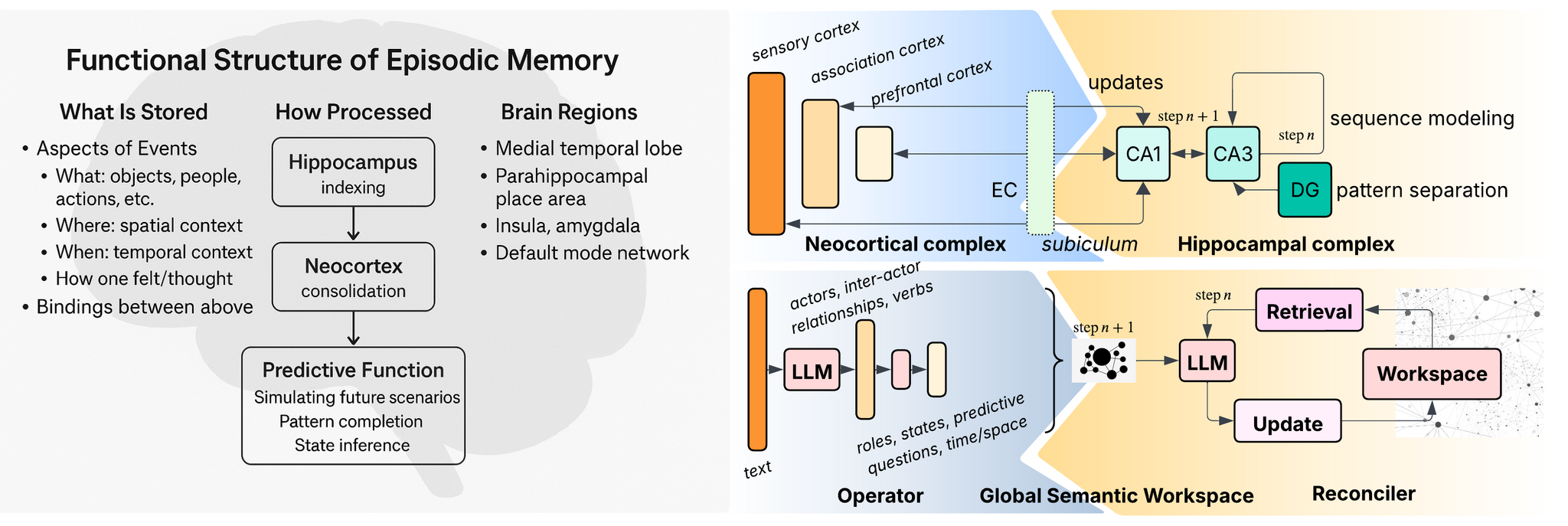
В предложенной модели эпизодической памяти, вдохновленной структурой мозга, гиппокампальная система (DG, CA3, CA1) и неокортикальные области (NC) служат основой для модулей Reconciler (извлечение, рабочее пространство, обновление) и Operator (семантическое извлечение на основе LLM), что обеспечивает биологически вдохновленную и интерпретируемую модель для моделирования мировых знаний из текстовых данных.
Взаимодействие между Operator Framework и Reconciler Framework позволяет GSW эффективно обрабатывать и интегрировать новую информацию, разрешать противоречия и формировать согласованное представление о мире. Это открывает возможности для создания интеллектуальных систем, способных к обучению, адаптации и рассуждению в сложных и динамичных условиях.
Оценка Эпизодической Памяти в Пространственно-Временном Контексте
Критически важным аспектом интеллекта является эпизодическая память – способность запоминать конкретные события, привязанные к уникальным пространственно-временным контекстам. Она позволяет не просто хранить информацию, но и воспроизводить пережитый опыт, что является основой для обучения и адаптации.
Для оценки способности больших языковых моделей (LLM) к подобному типу вспоминания разработан Episodic Memory Benchmark. Этот тест требует от модели не только извлечения фактов, но и проведения логических рассуждений о времени и месте, что значительно повышает сложность задачи.
GSW, работающая на базе GPT-4o, демонстрирует высокую эффективность в решении данного теста, достигая передового результата F1-score в 0.85. На EpBench-2000 GSW опережает ближайший аналог на 15% по показателю F1-score и демонстрирует Recall в 0.822 в категории 6+ Cues, что примерно на 20% выше, чем у HippoRAG2.
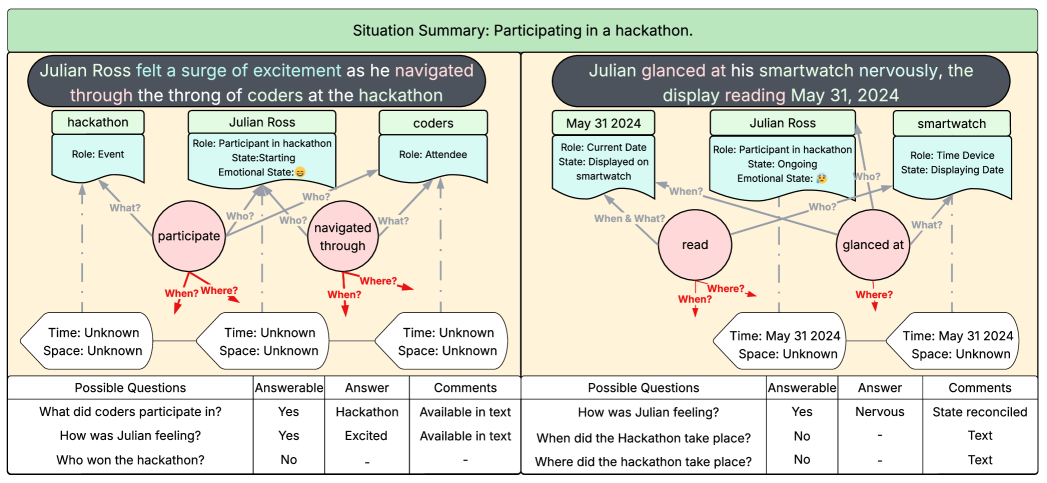
В процессе обработки истории системой GSW модуль Operator генерирует экземпляры для различных фрагментов текста, что демонстрирует его способность к анализу и структурированию информации.
Каждый новый слой памяти – это не просто хранилище фактов, а эхо прошедшего, предрекающее будущие сбои.
К Долгосрочному Рассуждению и Адаптивному Интеллекту
Архитектура GSW представляет подход к представлению знаний, который отделяет репрезентацию знаний от ограничений фиксированного размера контекстного окна. Это открывает возможности для реализации действительно долгосрочного рассуждения, выходящего за рамки традиционных моделей обработки естественного языка.
Структурированный подход, используемый в GSW, обеспечивает эффективное обновление и адаптацию знаний. Это позволяет искусственным интеллектам непрерывно учиться и совершенствовать свое понимание мира, интегрируя новую информацию без потери контекста предыдущих знаний. В отличие от систем, полагающихся на большие языковые модели с фиксированным контекстом, GSW позволяет динамически расширять базу знаний.
Будущие исследования будут направлены на масштабирование GSW для работы с еще более крупными базами знаний и изучение его применения к более широкому спектру сложных задач, требующих рассуждений. Особое внимание будет уделено оптимизации алгоритмов поиска и извлечения знаний из графовой структуры для повышения эффективности и скорости работы системы.
Исследование представляет собой не просто улучшение систем поиска информации, а создание полноценной экосистемы памяти для больших языковых моделей. Авторы предлагают концепцию Generative Semantic Workspace (GSW), позволяющую LLM формировать структурированное, вероятностное представление мира, что особенно важно при работе с длинными, динамично меняющимися повествованиями. Этот подход напоминает о мудрости Брайана Кернигана: «Простота — это высшая сложность». Подобно тому, как GSW стремится к элегантному представлению сложных данных, Керниган подчеркивает ценность лаконичности и ясности. Создание такого “внутреннего мира” для LLM – это не попытка построить идеальную систему, а скорее выращивание сложной структуры, способной адаптироваться и эволюционировать, учитывая постоянные изменения в поступающей информации.
Что дальше?
Предложенная работа, как и любая попытка обуздать хаос долговременной памяти, лишь аккуратно отодвигает завесу над бездной нерешенных вопросов. Создание "генеративного семантического пространства" – это не строительство, а скорее взращивание, и каждое решение об организации знаний – это пророчество о будущем сбое. Попытки формализовать "мировую модель" внутри LLM неизбежно столкнутся с проблемой репрезентации: как удержать текучесть реальности, не превратив её в застывший артефакт? Ведь сама суть повествования – в его эволюции, в постоянном пересмотре прошлого.
Очевидно, что истинный прогресс потребует смещения фокуса с совершенствования алгоритмов поиска на понимание механизмов забывания. Не менее важной задачей является разработка методов оценки "правдоподобия" или "когерентности" создаваемой модели мира – как отличить правдоподобную иллюзию от истинного знания? Настоящая система не должна просто отвечать на вопросы, она должна уметь удивляться, признавать собственную некомпетентность и, возможно, даже мечтать.
В конечном итоге, задача состоит не в создании идеальной памяти, а в обучении LLM жить с несовершенством, с неточностями и противоречиями. Ведь взросление системы – это не устранение ошибок, а принятие их как неотъемлемой части её существования. И тогда, возможно, эти искусственные "воспоминания" начнут напоминать не просто данные, а эхо пережитого опыта.
Связаться с автором: linkedin.com/in/avetisyan
Искусственный интеллект
4.9K постов11.4K подписчиков
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан