

Глаголица и кириллица: цифры
Когда я писал о глаголице и кириллице, то намеренно пропустил такую важную тему, как обозначение цифр в этих алфавитах, поскольку посчитал, что это лишь сильнее раздует и без того некороткие посты.
Что ж, кажется, пришло время для отдельного поста на эту тему, тем более, что мне как раз попала в руки обзорная статья по теме, из которой удобно красть заимствовать материал и таблички:
Štefan Pilát Číselná soustava hlaholice a cyrilice // Vesper Slavicus. Sborník k nedožitým devadesátinám prof. Radoslava Večerky. Praha, 2018. S. 161-173.
Начнём с древней Греции. Когда греки позаимствовали у финикийцев алфавит, они придумали так называемую акрофоническую систему, в которой цифры обозначались первой буквой соответствующего числительного:
5 – Π от πέντε /пэнтэ/;
10 – Δ от δέκα /дэка/;
100 – Η от ἑκατόν /hэкатóн/ (Η использовано в своём первоначальном значении, для обозначения согласного, как это было в финикийском);
1000 – Χ от χίλιοι /хилиой/;
10 000 – Μ от μυριάς /мюриáс/.
Только для единицы использовался знак Ι, который скорее соотносится с зарубками на счётных палочках, чем с каким-либо словом. Не случайно китайские иероглифы 1, 2 и 3 выглядят как 一, 二 и 三. Как вертикальная черта выглядел знак для единицы и у древних египтян.
999 в этой системе будет выглядеть как ΗΗΗΗΗΗΗΗΗΔΔΔΔΔΔΔΔΔΠΙΙΙΙ. Аналогичным образом были устроены, скажем, римские цифры (способ вычитания появился относительно поздно).
Тем временем у египтян изначально использовались отдельные иероглифы для чисел 1, 10, 100 и так далее, вплоть до миллиона включительно:
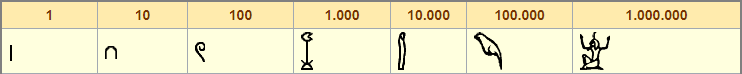
Со временем египтяне разработали более удобную систему, включавшую в себя знаки для всех единиц, десятков, сотен и тысяч. Вот так она выглядела в позднем демотическом письме:
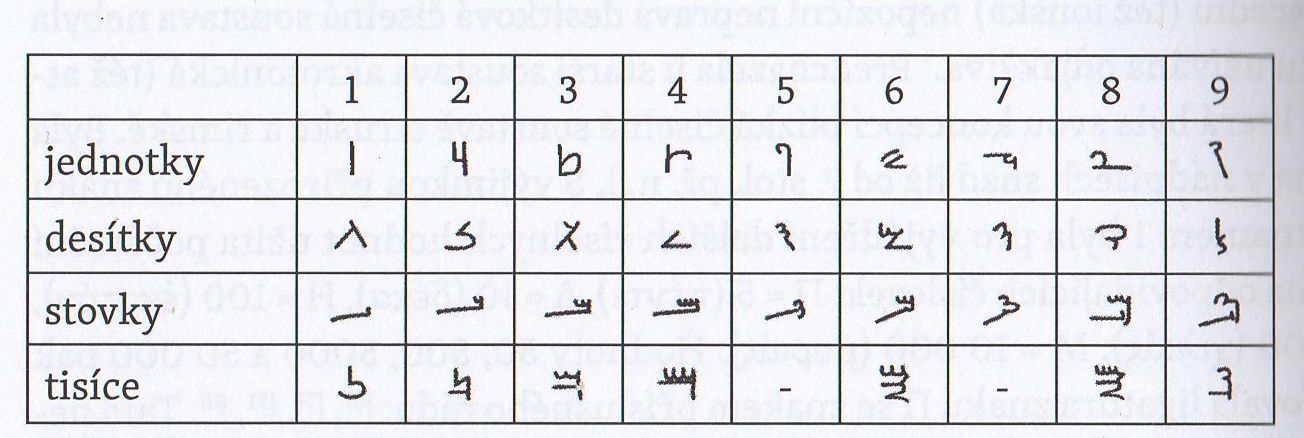
В отличие от современных «арабских» цифр, эта система была непозиционной, то есть, значение цифр не зависело от её места в числе (упрощённо говоря, всё равно, как записывать 12 - как 10-2 или 2-10, это ничего не меняет). И если сейчас мы обходимся десятью цифрами, то здесь их количество куда больше. Скажем, если вы оперируете цифрами до 10 000 включительно, вам понадобится 37 символов.
Эту систему скопировали древние греки в VI веке до нашей эры, приспособив буквы (в алфавитном порядке) вместо специальных символов:

999 будет записываться так: ϠϞΘ, что, конечно, куда удобнее, чем ΗΗΗΗΗΗΗΗΗΔΔΔΔΔΔΔΔΔΠΙΙΙΙ.
Удобной она, кстати, была и ещё для одной вещи, подсчётов числового значения слова, когда значения всех букв слова складывались и получалось число, соответствующее всему слову, из чего потом делались всяческие нумерологические выводы. У евреев аналогическая практика называется гематрия и именно таким методом было, по всей видимости, из словосочетания «Нерон Цезарь» получено знаменитое число зверя, 666.
В Греции новая система постепенно вытесняет старую акрофоническую, и ко времени создания славянских азбук, уже была единственной в Византии. Она была реализована как в глаголице, так в кириллице, однако, что крайне важно, по-разному.
Как мы помним, «кириллица» - слегка модифицированный греческий алфавит. Соответственно числовые значения почти полностью соответствуют греческим. И если в греческом буква Б отсутствовала, то и в качестве цифры она в кириллице не использовалась.

А вот глаголица – дело рук Константина-Кирилла. И он сохранил принцип, но присвоил числовые значения согласно порядку в алфавите, без пропуска букв:

Это привело к тому, что при одинаковом принципе, значения отдельных букв в кириллице и глаголице отличались. Примеры (глаголические буквы даю в транслитерации):

Эти различия иногда приводили к ошибкам при переписывании из глаголицы в кириллицу. Например, в сочинении черноризца Храбра, которое я цитировал в прошлых постах, есть число ⰳⰺ, 14. И мы точно знаем, что там должно быть именно 14, поскольку так в большинстве списков (= копий) этого памятника – ДІ (4+10), а в одном даже записано словами: четыри на десѧть. Однако в московском списке внезапно появляется число ГИ (3+8), которое не просто ошибочно, но даже невозможно в рамках алфавитной системы, поскольку сочетать цифры одного разряда нельзя. Объясняется эта ошибка легко: писец, не задумываясь, транслитерировал глаголические цифры ГИ, не сообразив, что в кириллице они имеют другое значение.
Характерно, что нам известны подобные ошибки, вызванные переписыванием глаголических памятников кириллицей. А вот обратных примеров нет. И это является сильным аргументов в пользу старшинства глаголицы.
Чтобы числа отличались от обычных букв, их с двух сторон выделяли точками, а над числом ставилось титло.
Как видно из табличек выше, алфавитную систему удобно использовать до 10 000. Потом буквы кончаются и к ним нужно прикручивать какую-нибудь диакритику. В принципе, для древнейших памятников это не было большой проблемой. Числа свыше десяти тысяч использовались редко и если что, их можно было записать словами. Показательно, что греческое μυριάς обозначает как 10 000, так и несметное множество. И те же самые значения мы находим у старославянского слова тьма.
Однако на Руси уже в XI веке (в знаменитом Новгородском кодексе) мы обнаруживаем цифру для 10 000 – а в кружочке. А вот обозначения десятков тысяч (в кружочках) в новгородской берестяной грамоте №342 (1320-1340 гг.):
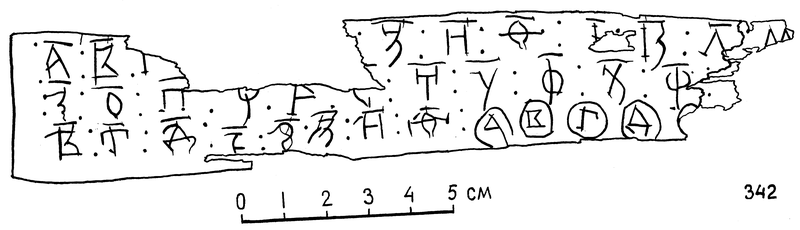
В трактате Кирика Новгородца «Учение о числах» (1136 год) обнаруживается обозначение ста тысяч – а окружённое точками. В качестве названия для него было использовано слово несъвѣда, которое в старославянских памятниках значило «бесчисленное множество». То, что цифровой ряд стал увеличиваться именно в купеческом Новгороде, вполне понятно и объяснимо.
Знак для миллиона мы находим в литургическом сборнике конца XV века, в нём буква а обведена кругом из запятых.
В 1607 году купец Фенне составил в Пскове немецко-русский разговорник. В нём мы находим названия до миллиона включительно, однако 100 000 названы не несъвѣда, а легионъ, а миллион – легиодръ (позднее также леодръ). Есть предположение, что автор довольно искусственного термина легиодръ ориентировался на французскую пару million – milliard.
Однако на этом русские книжники не остановились. В XVIII веке появляется обозначение десяти миллионов – воронъ или вранъ (в южнославянской огласовке), а затем и ста миллионов – колода или клада. Последним были изобретены символы для миллиарда – тьма тьмъ.

Максимально возможное число в этой системе выглядит так:
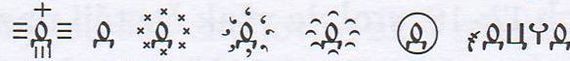
Ну а потом пришли более простые арабские цифры и всю эту красоту уничтожили.
Наука | Научпоп
9.5K поста83K подписчика
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.