

Диск NVMe постоянная нагрузка 100%
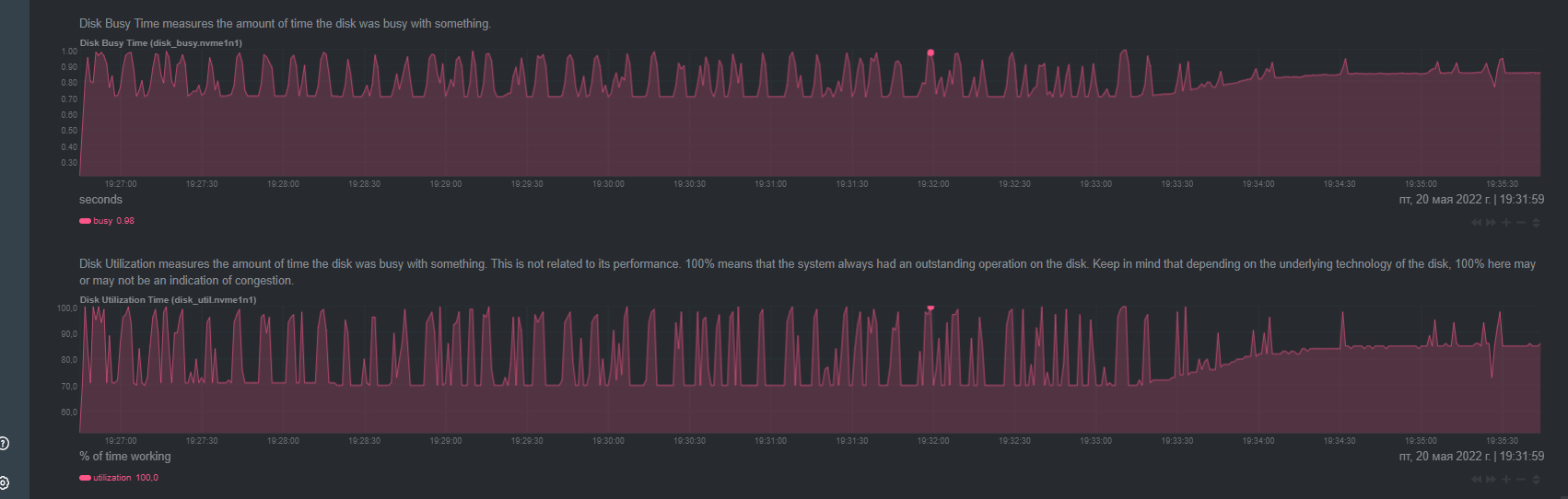
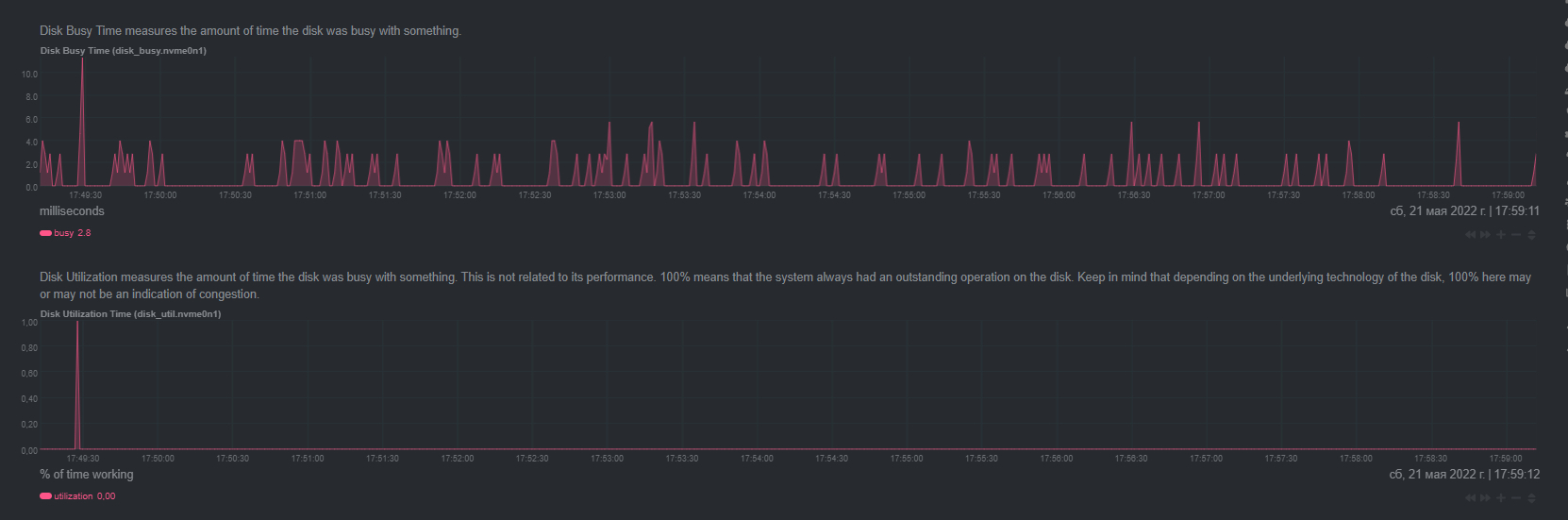
Посмотрел "atop" и заметил загрузку диска от 95% до 100%.
Начал анализировать, все началось с того, что я отключил все работающие проекты на этом выделенном сервере и заметил, что нагрузка упала до `15-20%`, думал дело в проектах..но не тут то было там нагрузка снова вернулась и стала достигать `75-85%`, поверх было видно, что при появлении `kworker` нагрузка на диск моментально подскакивала.
скриншотыatop:
1. https://i.stack.imgur.com/r81Wr.png
2. https://i.stack.imgur.com/lsd8f.png
3. https://i.stack.imgur.com/nQ86t.png
Я смотрю в `perf log`, `perf top` и вижу:
https://i.stack.imgur.com/1VOxm.png
https://i.stack.imgur.com/KdXFa.png
Диски здоровы, результат по скорости:
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.4319 s, 2.5 GB/s
Timing buffered disk reads: 3878 MB in 3.00 seconds = 1292.39 MB/sec
что можно сделать на следующих шагах, чтобы локализовать проблему и загруженности дисков на 95-100%?
Debian 10 debian 4.19.181-1
Лига Сисадминов
1.6K постов17.8K подписчиков
Правила сообщества
Мы здесь рады любым постам связанным с рабочими буднями специалистов нашей сферы деятельности.