

AI Красноярск
1 пост
1 пост






Сделал довольно простой бесконечный генератор мемных котов, обучив Stable Diffusion на всех мемных котах известных в сети)










































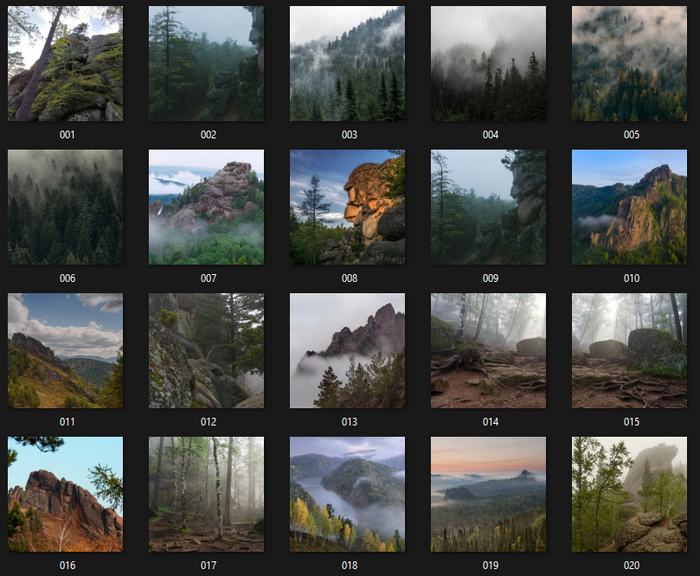
Исходники, на которых проходило обучение
Stable Diffusion 1.5 CardosAnime_v20 + CinematicStyle LoRA + кастомная LoRA

CardosAnime_v20

Juggernaut_reborn

Juggernaut_reborn + CinematicStyle LoRA

CardosAnime_v20 + CastingShadowStyle LoRA

Moomoocomic_v10
По-моему Олег очень крутой и добрый дядька)
Stable Diffusion 1.5 + кастомная LoRA, обучение нейросети на базе модели Deliberate_v6

Привет!
На сегодняшний день получить фотографию живого мамонта является неразрешимой проблемой. Но что, если очень хочется или даже нужно...
Стандартные решения вроде Midjourney или Dall-e способны выдавать неплохой и даже симпатичный результат, который, правда, всё ещё далёк от фотореализма и вызывает, как правило, лишь одну реакцию - "это нарисовала нейросеть":

Мамонты, сгенерированные Midjourney
Нам поможет самостоятельное обучение нейросети на базе Stable Diffusion 1.5
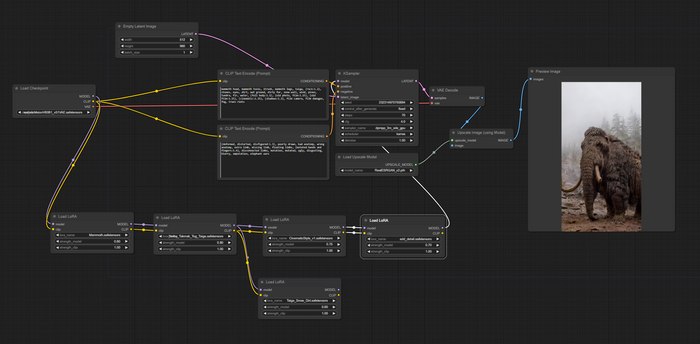
Рабочий процесс в Stable Diffusion через интерфейс ComfyUI
В настоящее время я не использую в своей работе SDXL, так как SDXL обучается во много раз дольше, чем SD1.5, что хоть и даёт более детализированную картинку, но не позволяет оперативно следить за результатом, даже на мощном железе.
Итак! Нам понадобятся:
Общий вид мамонта (тут подойдут любые реконструкции - фото из музеев, 3д рендеры, рисунки, главное - это дать нейросети общее представление о форме животного)

Изображения на которых проходило обучение
2. Изображения, которые помогут нейросети понять как должен выглядеть мех крупного, грязного и дикого зверя, наподобие мамонта. Подойдут фото бизонов, овцебыков, кабанов:

3. Для большего фотореализма добавим немного слонов. Но только глаза, хобот и бивни

К каждому из изображений, на которых будет происходить обучение, необходимо добавить текстовый файл, описывающий, что именно на конкретной картинке должна запомнить нейронка. Затем, при генерации, эти описания будут незаменимы при составлении промпта.
4. Для генерации окружения я использовал около 100 картинок, показывающих природу Красноярского края и Якутии. Тайга, тундра, грязь, снег, слякоть:

Добавляем готовые гиперсети формы, меха, глаз, окружения и прочего к основной, базовой 1.5 Апскейлим, что-то переробучаем и проверяем результат:















До полного фотореализма, конечно ещё далеко. К тому же из-за особенностей генерации в SD1.5 вертикальные картинки получаются значительно более гармоничными, чем горизонтальные. Пока что эти недостатки помогает скрыть стилизация под старое фото на плёнку:)
Базовая модель RealisticVisionV6.0 + кастомные LoRA с мамонтами и природой + LoRA CinematicStyle_v1
Примерно 4-5 секунд требуется для генерации одного вертикального изображения 512х960 на карточке 4080 . Время обучения одной LoRA примерно 4-6 минут

Всем привет!
За почти год освоения Stable Diffusion и работы с ним у меня накопилось огромное количество контента, основанного на самостоятельном обучении нейросетей. Часть это коммерческие проекты (в основном для театров и других учреждении культуры), но также многое проделано "в стол" в процессе освоения, поиска и экспериментов.
Понемногу буду выкладывать что-то здесь)
Начну с чего-то не сложного)
Я живу в Красноярске, а самое известное место отдыха жителей нашего города это заповедник «Столбы»!
Базовая модель - Realistic Vision V6.0 B1 + кастомная LoRA, основаная на фото Красноярских столбов и сибирской тайги














