


Сказ о том, почему LelResetFeg со спидраном не свезло
3 дня назад во время прохождения GTA: San Andreas на скорость товарищу LelResetFeg на голову упал вертолёт. Некоторые игроки начали подозревать стримера в нечестной игре, но если подумать, то ситуация выглядит слишком глупо
Если вы ранее играли в GTA: SA, то вполне возможно, что подобное с вами уже случалось: совершенно рандомная последовательность клавиш приводила к активации какого-нибудь чита.
В этом посте мы разберёмся, что же приводит к такому поведению игры
Дальше будет много технических подробностей, а сочетания, которые мог случайно прожать стример, будут в конце
Для начала, нужно понять, как игра хранит список чит кодов.
Этот вопрос решается простым гуглением:
GTAG Modding:...
San Andreas stores the last 29 characters typed on the keyboard, hashes the resulting string and compares it with the hashes of the cheats. Because the cheats are stored in hash form, it is much harder to figure out what they are. Most cheats have more than one code due to hash collisions and the intended cheat phrases for many took a long time to find.
Cheats have a minimum length of 6 characters and are stored all in upper-case.
Отлично, теперь мы знаем следующее:
- Хеш-функция достаточно слабая (много коллизий)
- Длина чит кода может быть от 6 до 29 символов
- При вводе символы сохраняются в верхнем регистре (это важно, поскольку хеш-функция учитывает регистр)
Для вашего понимания (определения неполные и значительно упрощены):
Хеш-функция - это такая штука, которая может преобразовать набор входных данных в набор выходных данных, но уже определённой длинны (который будет называться хешем).
Пример: Вы можете хешировать «Войну и мир» Л. Н. Толстого и на выходе получить строку вроде "73279c854ad356869d3f59150ebc964d53269aed" (хеш по алгоритму SHA-1). Затем, если вам скинут архив с кучей книг и рандомными названиями, то найти среди них нужное издание книги вы сможете просчитав хеши всех книг, и найдя среди них книгу с хешем "73279c854ad356869d3f59150ebc964d53269aed" (не читая ни названий, ни содержания).
Вероятность того, что хеш SHA-1 совпадёт с хешем другой книги - крайне мала.
Коллизии - те самые случаи, когда хеши разных входных данных совпадают. Вероятность появления коллизий зависит от длины хеша и особенностей конкретной хеш-функции (алгоритма).
Итак, что мы можем сделать дальше?
Поверим англоязычным товарищам на слово и будем считать, что хеш-функция действительно слабая.
Для этого есть некоторые предпосылки, например, оптимизация: во времена разработки GTA: SA (напомню, игра вышла в конце 2004 года) трата кучи ресурсов компьютера на просчёт хеша последних введённых символов на клавиатуре была бы... не лучшим вложением.
Наша задача - найти как можно больше коллизий для чит кода OHDUDE (спавн вертолёта Hunter), для её упрощения (и ускорения расчётов) мы ограничимся набором символов "WASD"
Проблема: не понятно, какую хеш-функцию использует игра. По этому поводу информации практически не найти, поэтому рассмотрим, какие кусочки информации есть на форумах:
Есть хеши чит-кодов:
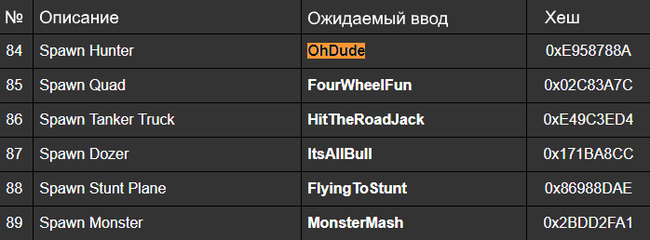
Каждый хеш длиной в 4 байта, с такой длиной куча коллизий - не сюрприз.
Запомним хеш нужного нам чита - 0xE958788A
На ум сразу приходит CRC32 (32=8*4 - от количества бит в хеше), вот только не понятно, какая его разновидность используется в игре.
Не будем ломать себе мозг и воспользуемся калькулятором.
Вводим OHDUDE, и... ничего похожего здесь нет:
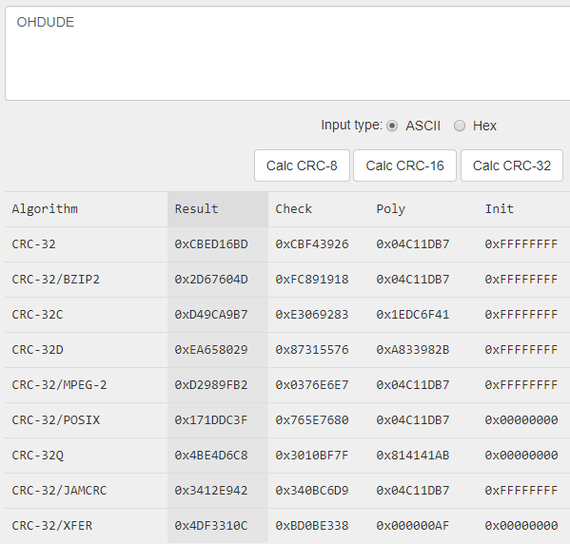
На этом этапе я провёл достаточно много времени, обнаружил на форумах утверждение, что в игре используется CRC-32/JAMCRC. Также было упоминание о расчётах CRC-32 в исходных кодах инструмента для изменения игровых файлов, но результаты никак не сходились.
До тех пор, пока до меня не дошло, что гораздо удобнее хранить историю нажатых клавиш в перевёрнутом виде. Посмотрим:
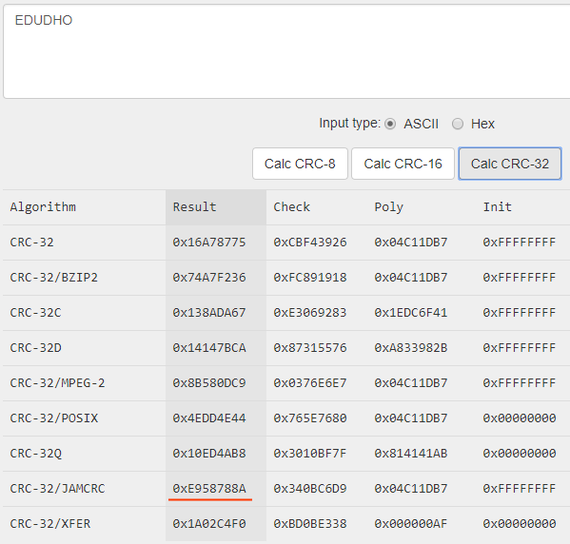
Ха, вот оно как!
Значит, осталось перебрать все возможные последовательности нажатия кнопок W, A, S и D, хеш CRC-32/JAMCRC которых будет равен 0xE958788A.
Конечно, делать это мы будем не ручками, а при помощи небольшой программы.
В ней нет почти ничего интересного, суть сводится вот к чему:
- Получаем на вход ожидаемый чит код
- Считаем его хеш
- Перебираем все возможные сочетания WASD (длиной до 17 символов, но это можно изменить)
- Выплёвываем все совпадения, предварительно перевернув строку задом наперёд
Самые любопытные могут почитать исходный код. (Писалось под Linux/g++, заводилось на WSL)
Итак, после перебора 17 179 869 100 возможных сочетаний мы получаем следующий список:
1. DASD AWAA WSSW WAW
2. AWDD WAAD SAAA WASS S
3. SWSW SWAA AWWW ASWW S
4. SSWD AWSS ADWD SSDW A
5. SDAW WDWS DDWS WSAW A
(если проверять все возможные сочетания, список будет гораздо длиннее, но перебор 288 230 376 151 711 744 сочетаний займёт... скажем, достаточно продолжительное время)
5 коллизий, и это только 4 кнопки с макс. длиной 17 символов! Время проверить:
Ни одной осечки :)
Такой вот ночной детектив.
Будете генерировать свои версии чит-кодов - кидайте в комментарии, может кому-нибудь они ещё понадобятся.















Лига Геймеров
44.4K постов88.9K подписчиков
Правила сообщества
Ничто не истинно, все дозволено, кроме политоты, за нее пермач, идите на ютуб
Помни!
- Новостные/информационные публикации постим в pikabu GAMES
- Развлекательный контент в Лигу Геймеров
Нельзя:
Попрошайничать;
Рекламировать;
Оскорблять участников сообщества;
Нельзя оценивать Toki Tori ниже чем на 10 баллов из 10;
Выкладывать ваши кулвидосы с только что зареганных акков - пермач