


Машинное обучение или учим компьютер понимать нашу речь
Всем привет! Продолжаю посты про машинное обучение. Этот пост будет посвящён компьютерной лингвистике. Сразу оговорюсь: я не занимался задачами, в которых стоит задача работы со звуками. Например, вы говорите:"Окей, гугл. А что тое изобние янда Алиса?", а компьютер показывает вам результаты по выдаче "А что такое изобретение Яндекса Алиса". То есть, компьютер записал вашу речь и затем восстановил её. Там свой пласт задач и алгоритмов (например, основанных на Витерби).
Вообще, задача понимания текста очень актуальна. Всем желающим причаститься к проблемам: раз, два и будущая Алиса от сбербанка (ага, программисты им не нужны. Ну да, отдадим на аутсорс). Мы с вами будем заниматься несколько другой задачей. Давайте представим себе следующий отзыв с кинопоиска:
"Последние Пираты ну просто редкостное дерьмо. Сюжета никакого нету, всё высосано из пальца. Только Депочка и Джефри Раш тащут. За них и поставлю такой балл. Нет, честно. Хотя я и люблю пиратскую тематику, но смотреть фильм невозможно. Ну, ещё спецэффекты ничего. Итого, 4 из 10"
В мои задачи входило:
1. Самая простая задача. Понять, а какова эмоциональная окраска текста? Ну, здесь довольно очевидно. Явно отрицательная.
2. Немного усложним задачу. А вообще о чём пишет пользователь? Какова тематика отзыва?
3. А теперь совсем сделаем сложной задачу: надо понять что именно не понравилось пользователю.
4. Ну, и задача в моей кандидатской была на основании того, что пользователю нравится и на что он обращает внимание порекомендовать кино. (про рекомендательные системы напишу попозже).
Сразу же перед нами встаёт техническая задача. А как построить матмодель для задачи? Ну, или как представлять слова в компьютере? Существует два подхода. Классический (bag-of-words) и современный (word2vec). Рассмотрим первый подход (последний более сложный)

Bag-of-words.
Классика же. Давайте представим, что у нас ограниченный язык и состоит из следующих слов: "я", "люблю", "кофе","утром", "чай","с", "лимон", "ненавижу". Давайте пронумеруем подряд все эти слова от 0 до 7. Будем представлять, что у нас каждое предложение это вектор. На i-ой позиции, которая символизирует соответствующее слово, может стоять или 0 (слово из языка не встречается), или 1 (наоборот). Например, предложение "Я люблю кофе" будет выглядеть :(1,1,1,0,0,0,0,0,0). А предложение:"Я люблю утром чай с лимоном" будет выглядеть "1,1,0,1,1,1,1,0". Когда мы разобрались уже с представлением текста, давайте попробуем приспособить нашу модель, для анализа тональности текста. Пусть теперь если слово имеет положительный окрас, оно будет иметь оценку 1, а если негативную, то -1. Остальные слова имеют 0 оценку. Рассмотрим предложение:"Я ненавижу кофе утром". Оно будет иметь вид:"0,0,0,0,0,0,0,-1". Что делать дальше?
А дальше можно делать разное, но лучше всего тупо взять и просуммировать. То есть, если выражаться научным языком у нас будет линейный классификатор. Картинка будет выглядеть примерно следующим образом:
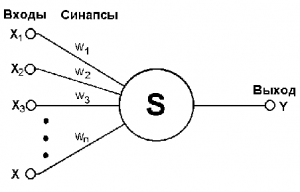
Да-да, я взял картинку персептрона (нейросети. По ним будет отдельный разговор), но сути это не меняет. На вход подаётся вектор, каждой координате вектора присваивается определённый вес, затем каждая координата умножается на этот вес и всё суммируется. По сути я расписал здесь работу в S. Но тогда (до 2014) использовался активно SVM. Что это за зверь?
SVM
Предположим, у нас есть двумерное пространство. Два измерения: Х и У. Есть выборка. Любой элемент из выборки может быть или звёздочкой (класс 1), или кружавчиком (класс 2). Мы взяли и нарисовали это на двумерной плоскости. Получили примерно следующую картинку.

Теперь мы хотим определить алгоритм, который позволит новые элементы отнести или к кружкам, или к звёздочкам. На картинке это красная линия. Любой элемент, который будет левее этой линии будет отнесён к звёздочкам, а правее ко кружкам. Как построить эту линию? Надо будет решить оптимизацию по максимизации/минимизации margin (вообще-то в литературе принято именно такое название. На рисунке это почему-то называется gap). Говоря простым языком, разделяющая гиперплоскость (красная линия) должна проходить по cередине между двумя классами. (Желающим понять как решается математически эта задача - размещу ссылку в конце). Ясное дело, что такую прямую не всегда можно построить. Множества объектов, где можно построить такую прямую называются линейно-разделимыми.
Ещё у линейных алгоритмов есть одно замечательное свойство/особенность, которое ярко проявляется в задачах лингвистики. В задачах анализа текста мы имеем дело с векторами с ОЧЕНЬ большой размерностью. А есть теорема, которая гласит, что для ЛЮБОГО множества можно подобрать пространство, где оно будет линейно разделимо.
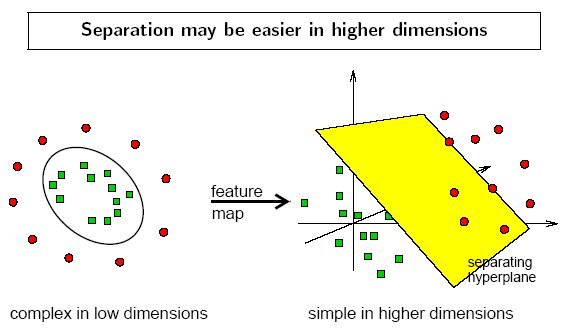
На левой картинке множество в двумерном пространстве не является линейно-разделимым. Но если мы выйдем в трёхмерное пространство, то всё будет ок! А теперь, у нас итак дофигамерное пространство. Там скорее всего и так будет всё линейно разделимо.
На практике используют всё-таки модификации алгоритма. Добавляют специальные функции: ядра, которые служат чтобы повысить размерность задачи и всё было разделимо. Это отдельный такой тонкий момент, не будем его касаться в данном посту. (Желающим узнать больше первая ссылка)
"Так как же это всё применить к нашей задаче?"- наверняка спросите вы. А я отвечу. Давайте возьмём линейный классификатор SVM в качестве алгоритма. Составим огроменные вектора (обычное дело, когда там 10 000 координат), где i-ая координата вектора будет слово алфавита. Затем, возьмём отзыв который мы хотим классифицировать. Закодируем и подадим на вход нашему алгоритму и получим ответ. А как вы думаете, такой способ кодировки - он нормальный? В ранних работах по анализу тональности текста с бинарной классификацией (нравится/не нравится), такой "тупой" и "примитивный" подход давал вполне неплохой результат. Насколько я помню, где-то 70-80%. Что казалось круто. Кстати, а в чём же всё-таки минусы такой кодировки? Кодировки bag-of-words и последующего применения SVM?
Минусы:
1. Теряется информация о предложении. Зачастую довольно важная.
2. Всё сваливается в одну кучу и невозможно понять, а о чём собственно отзыв?
3. Теряются связи в предложении.
А самое главное. А что будет, когда пользователь начнёт в своём отзыве пересказывать сюжет? А там запросто может быть что-то ругательное, но не относящееся к мнению пользователя. Или наоборот, "Добрый принц поскакал героически спасать прекрасную принцессу. Имхо, сюжет говно". Гляньте, сколько положительных слов в первом предложении! И сильных эмоционально. Но мнение пользователя в реальности отражает только второе предложение и оно ключевое. Как это понять?
В середине нулевых была работа, которая призывала тренировать SVM на отзывах, которые были малость причёсаны вручную. Были выделены отдельно фразы, которые отражают мнение пользователя, а отдельно общие фразы типа насчёт сюжета. Такой подход дал неплохой прирост. Где-то 80%-85% точности. Идея хорошая. Но можно улучшить. А что если применить ещё метрику tf.idf для анализа текста? Была использована следующая модификация.
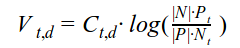
где:
Vt,d — вес слова t в документе d
Сt,d — кол-во раз слово t встречается в документе d
|P| — кол-во документов с положительной тональностью
|N| — кол-во документов с отрицательной тональностью
Pt — кол-во положительных документов, где встречается слово t
Nt — кол-во отрицательных документов, где встречается слово t
Затем в bag-of-words вместо +-1 ставилась эта оценка.
Результаты работы, где была введена эта метрика:
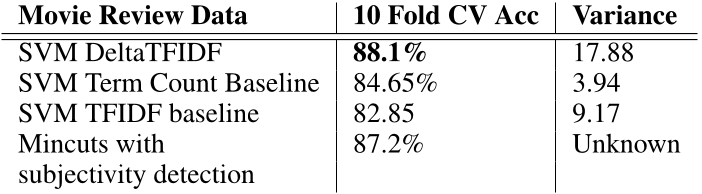
Круто, что сказать. Вообще, здесь можно говорить много, поэтому вместо итога расскажу немного о своей роли в мировой науке (2014 год). Я поставил вопрос: а на каких отзывах считать delta tf.idf? На больших текстах или небольших "а ля твиты"? Ну, у меня получилось, что лучше твиты. Тетсировал я, дай Бог памяти, на 100 000 отзывах. Также там попинал одного греческого учёного за неаккуратное ведение исследований. Статью у меня приняли в скопус на английском, но, если честно, я её стыжусь. Да, я сделал исследование и сделал его сам, но это херь по своей значимости (хотя, чего таить, было приятно. Что я магистр и в скопусе). Тем более, что в том же году Томас Миколов триумфально ввёл в обиход компьютерной лингвистики рекуррентные нейросети...
Честно говоря, и так получился огромный пост. Если будет интересно, в следующем посту немного расскажу или о нейросетях и word2vec, или о рекомендательных системах и их симбиозе с анализом тональности текста. Ну, или про шахматные программы.
Ссылки:
1. SVM: http://www.ccas.ru/voron/download/SVM.pdf
2. Учёные, которые догадались использовать машинное обучение для сентимент-анализа. Их статья, где они придумали использовать субъективные фразы. http://www.cs.cornell.edu/home/llee/papers/cutsent.pdf
3. Учёные, которые придумали использовать delta td.ifd. http://ebiquity.umbc.edu/_file_directory_/papers/446.pdf

Наука | Научпоп
7.7K постов78.5K подписчиков
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.