

Исправляем грамматику с помощью GPT-4 API

С самого выхода ChatGPT я начал ее использовать для решения задач корректуры текста: устранения опечаток, исправления ошибок и улучшения стилистики.
Однако, при использовании веб-версии ChatGPT возникают некоторые проблемы:
Приходится вчитываться в исправленный текст, чтобы найти изменения
Не используется вся мощь API, в котором есть возможности для более тонкой настройки бота
Можно задать системное сообщение, в котором объяснить ассистенту смысл его существования
Few-shot learning: можно предоставить набор примеров коррекции сообщений
Неудобство: нужно вставлять свой текст в веб-версию, затем набирать свой промт для его улучшения (который может быть разным в зависимости от типа коррекции). Хотелось бы иметь Web UI, где нужно просто вставить текст и выбрать тип коррекции - а далее текст будет обрабатываться оптимизированным промтом
Данный проект призван устранить эти недостатки. Потыкать приложение можно здесь (для использования нужен OpenAI API-ключ).
Приложение

В веб-приложении есть поле с текстом, в которое пользователь вводит свое сообщение, которое нужно исправить. После нажатия на изображение-кнопку в поле справа постепенно выводится исправленная версия, а по окончании вывода выделяются изменения. При наведении на изменение, tooltip показывает, что конкретно было исправлено.
Поддерживается множество языков. Можно либо выбрать язык исходного сообщения вручную, либо положиться на встроенный детектор языка.
Можно выбрать используемую модель: общедоступную GPT 3.5 Turbo, либо GPT-4. Доступ к GPT-4 API сейчас по вейтлисту, сама модель более чем на порядок дороже, но зато гораздо умнее.
Поддерживаются два типа коррекции текста:
just correct grammar просто исправляет грамматические, орфографические и пунктуационные ошибки
make more natural вдобавок улучшает стилистику текста. Однако, тут изменения более кардинальны, и иногда они могут менять смысл текста
OpenAI API стоит денег. Передо мной встала задача: как сделать проект юзабельным для множества людей, если он базируется на платном API? Брать с пользователей деньги и оплачивать своим ключом - такая стратегия не подходит для небольшого пет-проекта, потому что реализовать биллинг - отдельная большая задача. Поэтому пусть пользователь сам вводит свой ключ и платит с него. При нажатии на шестеренку открывается страница с настройками, где можно ввести/изменить свой API-ключ.
В такой парадигме проект пришлось делать вообще без сервера, чисто на React (потому что ключи нельзя никуда отправлять). Кроме того, для еще большей прозрачности код я открываю: https://github.com/einhornus/language-challenge-react (данное приложение - это на самом деле только часть большого проекта, который находится в процессе разработки).
Я питонист-MLщик со специализацией в NLP, кодинг на React для меня - выход из зоны комфорта. Поэтому прошу сильно не пинать из-за кривизны UI и качества JS-кода в репе.
Фокус данного проекта - на максимизации качества коррекции текста и на скорости релиза юзабельной версии.
GPT-4 API
В этой секции я расскажу про GPT-4 API и покажу, как с его помощью можно решать задачи NLP.
В API есть метод ChatCompletion, который принимает список сообщений, который мы будем называть промтом, и возвращает следующее сообщение.
Каждое сообщение этого списка - это словарь с двумя полями: role и content.
По значению role сообщения классифицируются на 3 типа: системные сообщения (role="system"), сообщения пользователя (role="user") и сообщения ассистента (role="assistant").
Системное сообщение содержит в своем поле content высокоуровневые инструкции для ассистента - то, как он должен действовать. Если в промте несколько системных сообщений, иметь значение будет только последнее из них (новые системные сообщения переписывают старые). Как расположение системного промта относительно остальных сообщений влияет на результат - я пока не понимаю, это открытый вопрос.
Последовательностью сообщений пользователя и ассистента задается предыдущая беседа между ними. Однако, эти сообщения также можно использовать для описания примеров решения задачи (few shot learning). В каждом сообщении пользователя находится пример входных данных, а в сообщении ассистента после него - ожидаемое решение. После примеров идет сообщение пользователя, в которое записываются входные данные, для которых нужно получить решение.
Рассмотрим задачу машинного перевода с английского на русский. В этом случае промт может выглядеть следующим образом:
[ { "role": "user", "content": "Hello how are you?" }, { "role": "assistant", "content": "Привет, как дела?" }, { "role": "user", "content": "Despite the heavy rain, they decided to continue their hike through the dense forest" }, { "role": "assistant", "content": "Несмотря на сильный дождь, они решили продолжить свой поход через густой лес" }, { "role": "user", "content": "The chef, inspired by flavors from around the world, has created a unique fusion cuisine that attracts food enthusiasts and critics alike" }, { "role": "assistant", "content": "Повар, вдохновленный вкусами со всего мира, создал уникальную фьюжн-кухню, которая привлекает как гурманов, так и критиков" }, { "role": "system", "content": "You are TranslateGPT. You translate user messages from English to Russian. You are the most accurate English to Russian translator in the world." }, { "role": "user", "content": "{текст, который надо перевести}" } ]
Если послать API-запрос с таким промтом, в ответ мы получим сообщение ассистента, которое будет содержать перевод нашего текста.
Кроме промта, в запросе к API есть и другие параметры:
model - используемая модель. На данный момент поддерживаются gpt-3.5-turbo (общедоступна) и gpt-4 (пока только для тех, кому предоставили доступ). gpt-4 стоит значительно дороже: 3 цента за 1000 токенов промта + 6 центов за 1000 токенов ответа против 0.2 центов за 1000 любых токенов у gpt-3.5-turbo. Однако, результаты при решении NLP-задач у gpt-4 гораздо лучше.
temperature - число от 0 до 2, которое задает, насколько часто при генерации следующего токена модель будет предпочитать не самый вероятный вариант. Увеличение температуры повышает креативность ответов, но снижает их качество. При решении задач NLP лучше всего просто оставлять температуру равной нулю.
max_tokens - максимальное количество токенов в генерируемом сообщении. При превышении лимита сообщение обрывается.
Полную справку по параметрам в API можно посмотреть здесь. Поиграться с API можно в плейграунде.

Переводчик в плейграунде
GPT-4 API в JS
В данном проекте мне нужно вызывать GPT-4 API из реакта. Да, существует специальная либа OpenAIApi, но она пока не поддерживает стриминг частичного ответа - чтобы пользователь мог видеть частичный результат по мере генерации сообщения.
Промт для решение задачи
Промт для модели формируется из двух частей:
Системное сообщение, в котором меняется только название языка
Набор примеров, который прописывается отдельно для каждого языка (может быть пустым)
NLP в React
Токенизация
Для токенизации текстов в JS я быстро нашел Intl.Segmenter, который превосходно справляется с задачей. Что важно, он также умеет работать с разными языками. Например, в китайском языке не ставят пробелов, токенизатор будет делить текст на логически связанные последовательности из нескольких иероглифов.
Распознавание языка
Алгоритм для коррекции текста требует идентификатор языка для извлечения примеров и токенизации текстов. Пользователь может выбрать язык напрямую, но более удобно иметь опцию автоматического распознавания языка.
С распознаванием языка возникли проблемы.
Сначала я наткнулся на либу franc, она не подошла из-за отвратительной точности распознавания.
Затем я посмотрел несколько других либ, которые у меня не получилось установить (видимо, они предназначены для Node.js). Была пара решений с внешним API, но для моего проекта это не подходит.
Потом у меня возникла идея решить эту задачу с помощью GPT-3.5 API. В целом это работало, но в сложных случаях модель начинала "ломаться" и выдавать что-то вроде "It seems to be a text in English with a couple of Russian words thrown in there as well" вместо того, чтобы просто выдать название языка в первых двух токенах. Кроме того, хотелось бы обойтись без всякой асинхронности, чтобы детекция языка происходила мгновенно. Да и вообще, использовать LLM для такой простой задачи - это оверкилл.
В итоге я быстренько навелосипедил собственный детектор. Он выбирает между 15 языками, опции "неизвестный язык" не предусмотрено.
Если у языка уникальная система письма, то распознать текст на нем несложно - нужно просто удостовериться, что процент символов из соответствующего алфавита превосходит определенный порог. С помощью такого подхода мой детектор распознаёт китайский, японский, корейский, хинди, армянский, грузинский и тайский. Есть проблема с деванагари - оно на самом деле используется некоторыми другими популярными индийскими языками, не только хинди. Этой проблемой я пока пренебрег.
Если текст прошел фильтр выше (то есть, он скорее всего написан на латинице или кириллице), я запускаю основной алгоритм классификации между 8 языками - английский, русский, испанский, немецкий, французский, португальский, итальянский, голландский.
Для каждого из этих языков я скачал частотный список слов и для 1000 самых частотных слов посчитал их нормированную частоту. Также я посчитал матожидание нормированной частоты слова, если оно отсутствует в списке 1000 самых распространенных.
Далее, я применяю метод максимального правдоподобия: для каждого языка я токенизую текст и считаю вероятность принадлежности текста к языку как произведение нормированных частот соответствующих слов (или их матожиданий для редких слов).
Поиск изменений
Пусть нам даны исходный текст и его исправленная версия (оба - в виде массива слов). Требуется найти кратчайший список операций для преобразования первого массива во второй. Операции бывают трех видов: удаление слова, вставка слова и замена слова. Для операций удаления нужно найти индекс удаляемого слова в массиве исходного текста, для операций вставки - индекс вставляемого слова в массиве исправленного текста, а для операций замены - оба индекса.
Нетрудно заметить, что длина нашего кратчайшего списка операций эквивалентна расстоянию Левенштейна. Таким образом, для решения задачи нужно восстановить редакционное предписание в алгоритме Левенштейна.
Результаты
Если использовать GPT-4, то получаются просто офигенные результаты

Исправление грамматики в сообщении на русском от неносителя
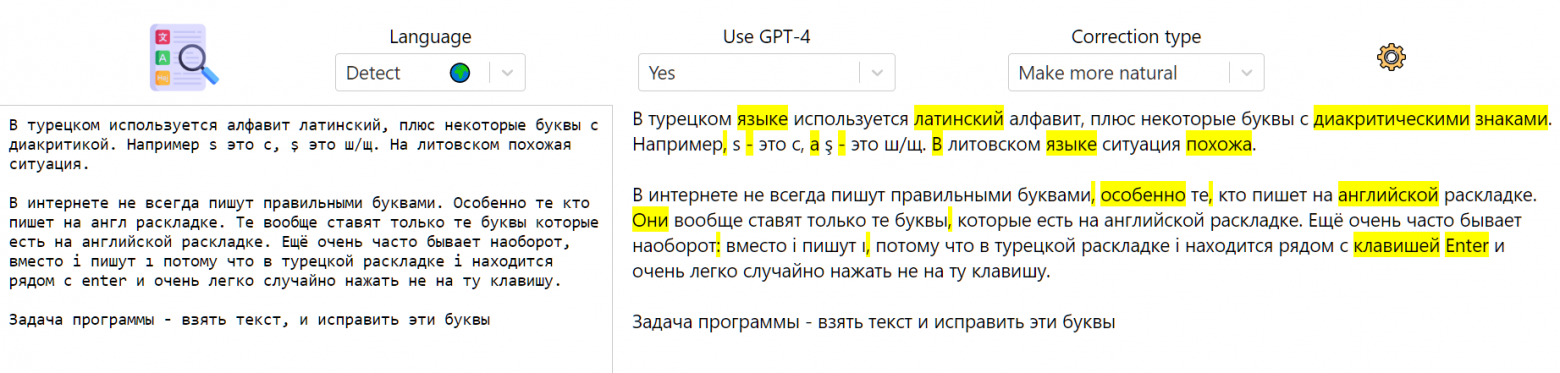
Улучшение текста, написанного в слегка неформальном стиле. Все изменения по делу

Исправление introduction, найденного в одном дискорд-сервере
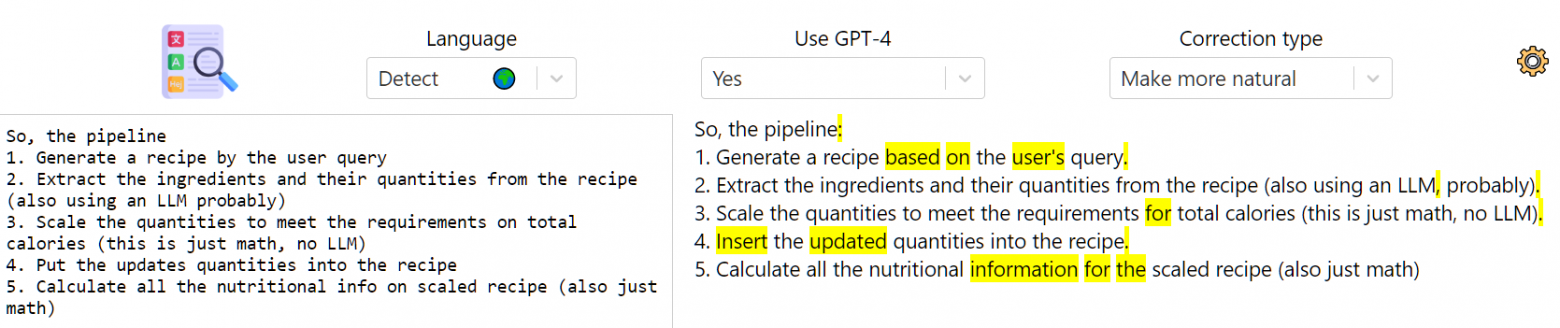
Улучшение моего неформального сообщения на английском

Мегахардкор - сочинение Ли Вонг Яна

Еще одно
На GPT-3.5 результаты похуже, но все равно очень даже неплохие

Результаты на GPT-3.5 слабо отличаются от результатов на GPT-4

Очень много исправлений по сравнению с GPT-4

Результаты на GPT-3.5 слабо отличаются от результатов на GPT-4

GPT-3.5 не исправила "их" → "её"
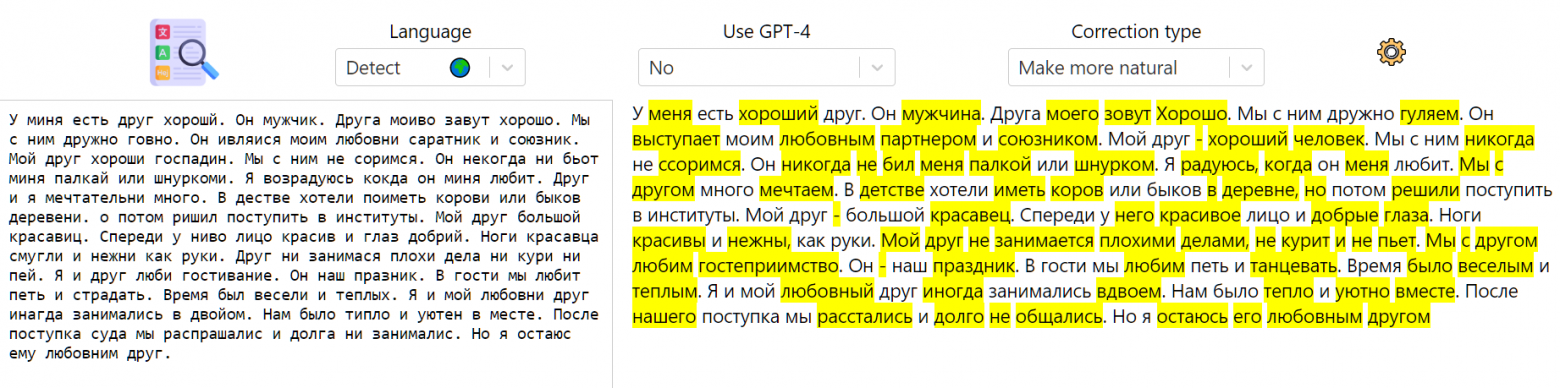
Ли Вонг Ян. На этом тесте явно видно превосходство GPT-4

Тут тоже GPT-3.5 исправляет текст гораздо хуже, чем GPT-4

Прикольная фича: можно вставлять слова на другом языке, и GPT будет переводить их в контексте
Используйте Chat GPT-4 телеграм бот. В РФ это самое удобное решение. Да еще и дешевле на 50%, чем на официальном сайте, так как работает через api Open AI.
ChatGPT
1.4K постов3.7K подписчика