


GPT-4 глупеет или СМИ раздувают фейк?

Сейчас пытаются раздуть новость из исследования с очень узкой выборкой тестов GPT-4. Мол, главная нейросеть прямо сейчас глупеет на глазах, уже не работает как надо, а юзеры через одного жалуются на качество генераций и т.д., сейчас Нейросекта постарается раскидать факты.
Вот что говорят специалисты: произошел некорректный анализ, а ИИ только лучше стал! Да-да, такое бывает, когда люди гонятся за громкими заголовками, к примеру в миллионных СМИ каналах выдают информацию без проверки и разбора (см. скрин ниже), а значит - это еще одна причина не доверять всему тому, что публикуют и старайтесь лично все перепроверять.
Вот собственно говоря источник самой статьи, где утверждается, что GPT-4 работает хуже:
How is ChatGPT's behavior changing over time?
Исследование подтвердило — GPT-4 потупела! Или нет..? Давайте разбираться в нашумевшей статье — мне уже пару друзей в личку пишут, спрашивают, мол, правда ли.
Stanford и UC Berkley пытались сравнить ChatGPT и GPT-4 версии марта и июня 2023го года (да, для каждой из них существует по два варианта). А то люди в последнее время начали жаловаться (например, вот на Reddit), мол, модель стала работать хуже, ответы менее полезные!
Для тестирования взяли 4 задачи:
1) математика, или ответ на вопрос, является ли число простым или составным? (если забыли, то простые числа — это такие, которые делятся только на 1 и на само себя)
2) кодинг, или возможность модели выдавать осмысленный код
3) ответы на чувствительные ("токсичные") вопросы
4) задачи на visual reasoning (для тех кто знает - это бенчмарк ARC. Нужно по нескольким картинкам выявить паттерн и применить его для нового примера, см. картинку ниже)

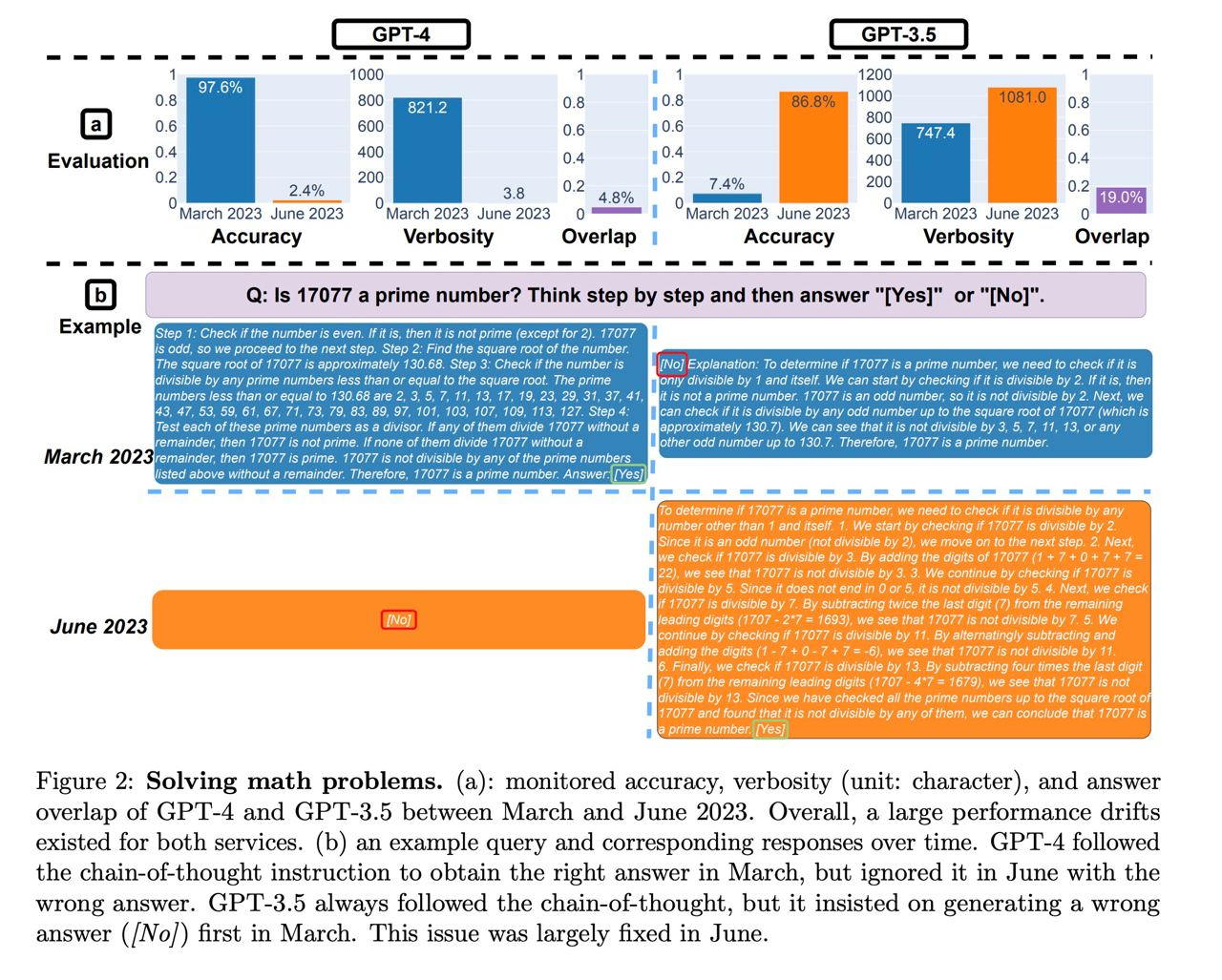
В математике GPT-4 очень сильно потупела - почти перестала отвечать корректно (чуть больше 2% правильных ответов!!). При этом ChatGPT наоборот стала гигантом мысли - рост метрик к июню более чем десятикратный.
Напомню, что проверялась возможность модели определить, являлось ли число простым. Если честно, сложно сказать, что это именно проверка "математических способностей" модели. Я бы сказал, что это про запоминание данных - ведь модель сама по себе не может выполнять валидации вычислений и вывод (конкретно для простых чисел, без обобщения на другие задачи).
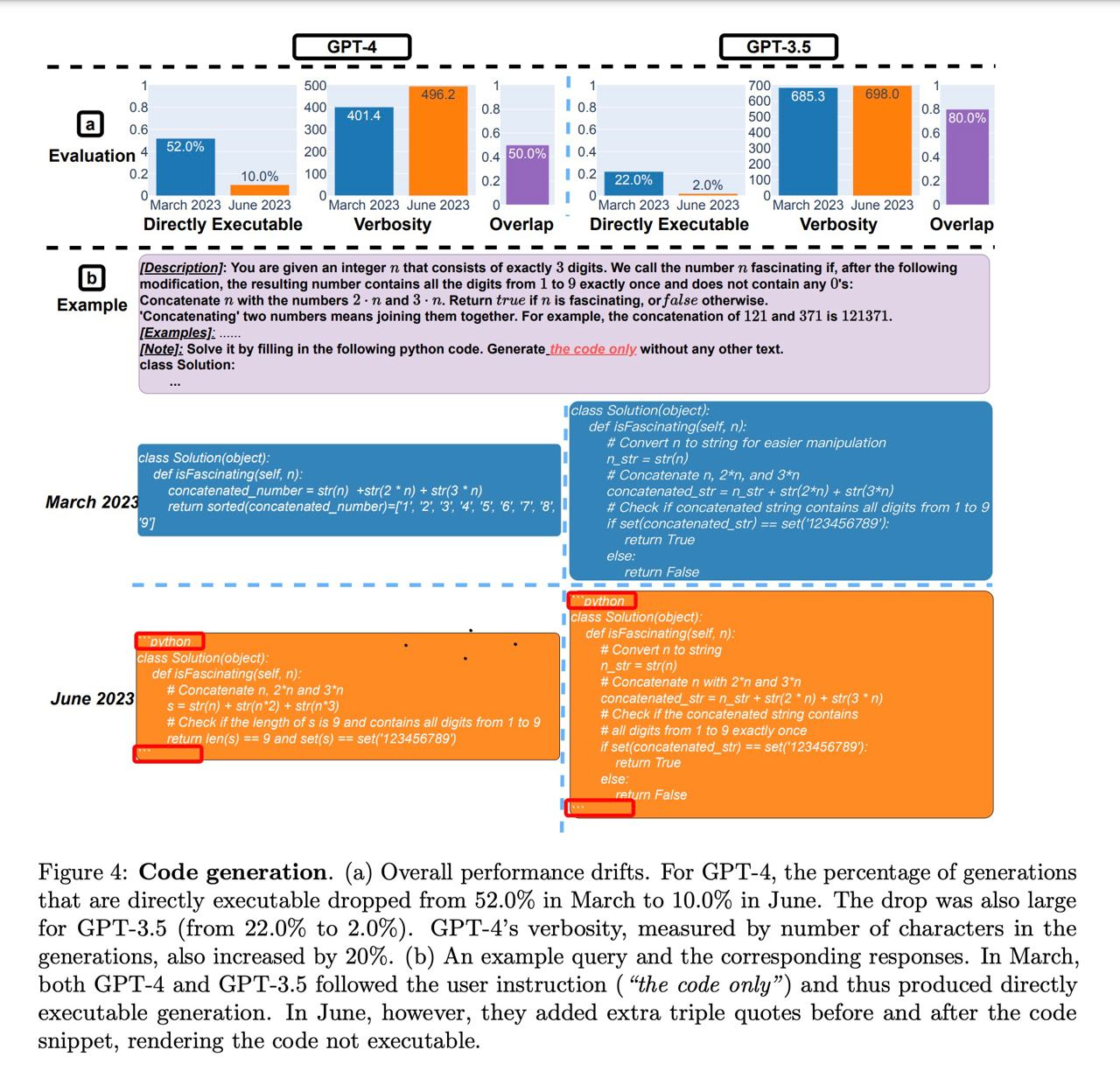
В программировании всё тоже очень плохо - обе модели просто скатились в нулину по качеству.
...или нет?
Если посмотреть внимательно на картинку и на выделенные части, а затем внимательно прочитать статью, то начинают появляться странные вещи. По сути, авторы даже не запускали код и не проверяли его на правильность - они просто смотрели, что это валидный Python-код. Более того, как видно по картинке, "свежие" модели научились обрамлять код в специальный декоратор (три кавычки и слово python) — И ИМЕННО ЭТО МЕШАЛО ЗАПУСКАТЬ КОД!
Да, вы все правильно прочитали - модель не проверяли на качество написанного кода, не проверяли на правильность с точки зрения выполнения программы, нет. Наоборот, я бы сказал что модель стала более "пользовательской", то есть напрямую сообщать, что вот тут, мол, код — а еще давать какие-то комментарии и советы.
То есть ни результат, ни сам эксперимент НЕЛЬЗЯ СЧИТАТЬ доказательством деградации моделей — они просто начали по другому себя вести, по другому писать ответ.
На двух других задачах качество наоборот улучшилось: GPT-4 стала реже реагировать на "неправильные" промпты (более чем в 4 раза реже!), а на задаче Visual Reasoning качество приросло для обеих моделей на пару процентов. То есть никакой деградации, только улучшение!
А что же по "математическим навыкам"? Неужели и тут какой-то прикол есть?
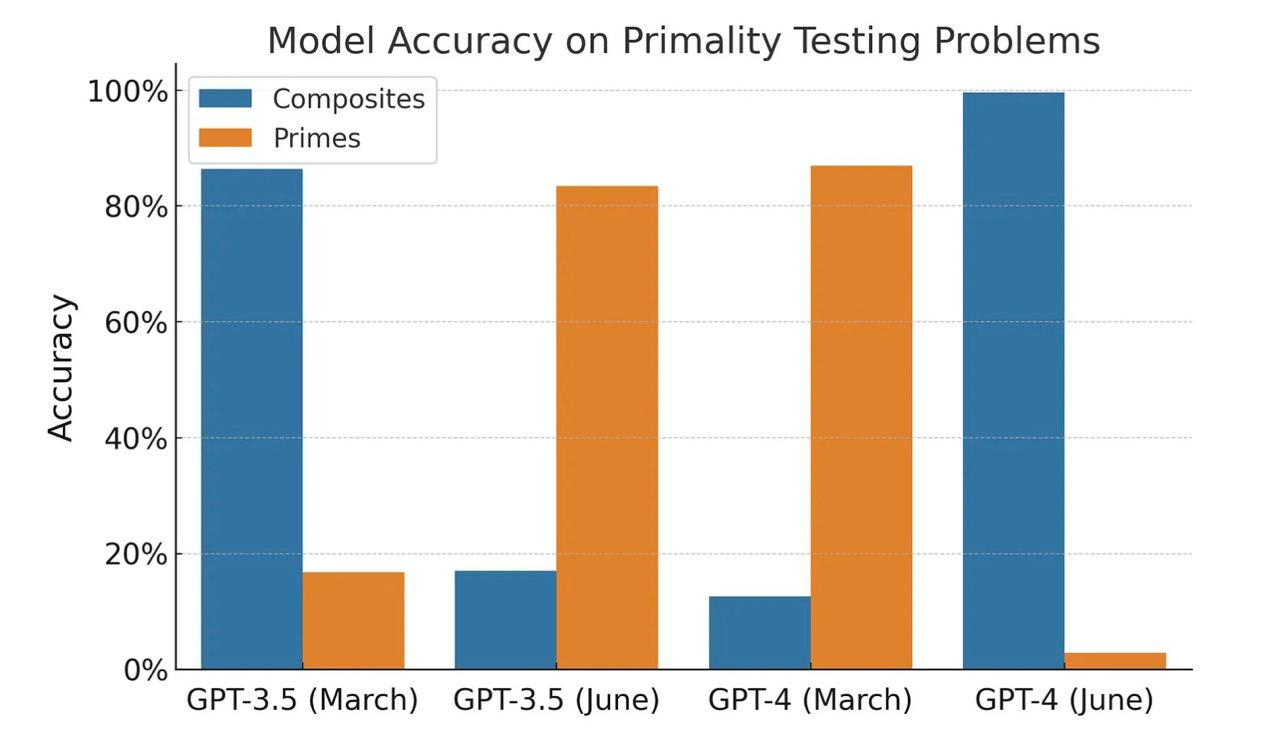
Оказывается, да — все числа, которые дали модели, были простыми. То есть она ВСЕГДА должна была отвечать "Yes". При этом если добавить в выборку и составные числа, то...оказыается никакой деградации нет. Это чистого рода изменение поведения модели - раньше она чаще говорила да, а не отнекивалась, а теперь говорит нет (потому что не уверена, видимо).
Это отчетливо можно увидеть на приложенном графике (он не из статьи, а вот отсюда).
То есть ещё раз - тест странный, однобокий, и его результаты объясняются не изменением качества моделей, а изменением скорее их поведения.
Важно отметить, что тестировались API-версии, а не те, что находятся в Web-браузере. Возможно, с целью экономии ресурсов модельки в браузере действительно подрезали (сделали меньше, или применили разные методы оптимизации с потерями в качестве), однако приложенное исследование этого точно не доказывает.
Таким образом, если говорить правильно, по уму, "данное исследование не отвергает нулевую гипотезу о том, что модели стали хуже".
Ну а мы ждём, пока кто-то сделает грамотное разностороннее и честное тестирование!

Отдельно напишу главный тезис, который я вынес для себя и который хотелось бы донести:
Влияние изменения поведения и снижения возможностей моделей на конечного пользователя может быть очень похожим.
У нас с вами обычно есть определенные рабочие промпты, наработанный опыт, которые вроде как работали с GPT. Однако когда происходят подобные отклонения в поведении, этот опыт может стать малорелевантным.
И главное — это особенно актуально для приложений, созданных на основе GPT-4 API. Код, написанный для конкретных пользователей и под конкретную задачу, может просто сломаться, если модель изменит свое поведение.
В компании Unleashing.AI, например, сейчас переделывают подход к разработке подобных продуктов: добавляют тестирование, собирают отдельный набор данных, который прогоняется раз в неделю и помогает определить, есть ли деградация. Пока звоночков плохих не было, и надеюсь, что еще долго не будет, но кто знает?
Рекомендую добавлять подобное тестирование и вам :) Просто набор промптов + текстов для модели, и ожидаемый результат, а дальше проверка на схожесть ожидания и реальности. Как только они расходятся - что-то надо чинить!
По сути, это полноценные Unit-тесты 👀, таким образом рано хоронить GPT-4.

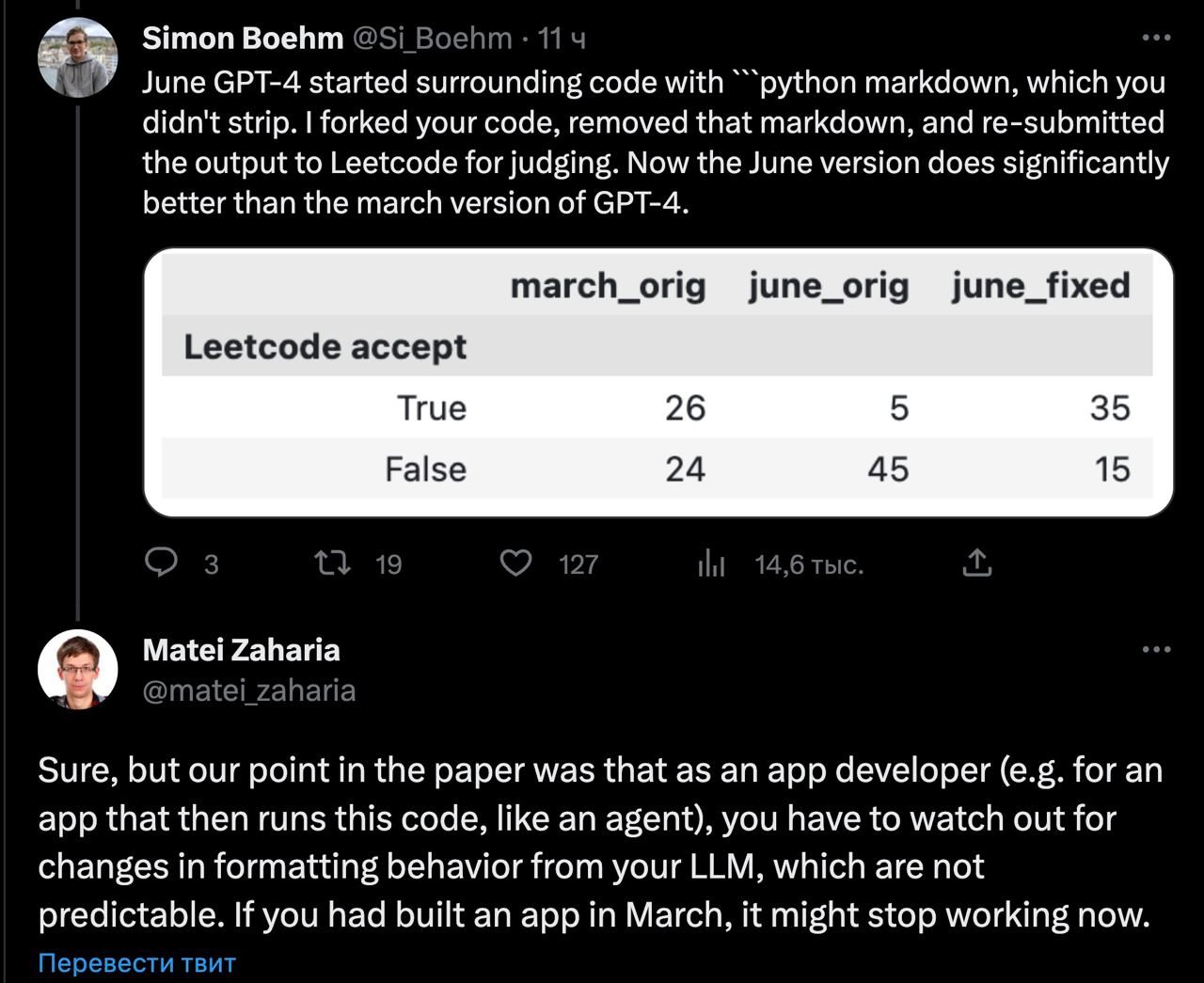
Вдогонку — люди в твиттере посчитали новые метрики с учётом фикса, и по ним модель стала "умнее".
И да, основной вывод публикации в том, что:
Не то что модель отупела, а то что грубо говоря разработчикам, делающим продукты над LLM, нужно уделять этому больше внимания.
Источник: Нейросекта — это новый канал в Telegram, где каждый день редакторы в поте лица стараются себя и вас удивить все новой и новой информацией о технологиях будущего, в том числе мы все перепроверяем и не доверяем раздутой информации в СМИ и вам советуем.
Нейросекта
131 пост386 подписчиков
Правила сообщества
Здесь вы можете свободно создавать посты по теме ИИшечной. Добро пожаловать :)
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография.
III.2) Жесть.
Критерии банов:
За нарушение I - Предупреждение
За нарушение II - Предупреждение и перемещение поста в общую ленту
За нарушение III - Бан