


Qwen 2.5 и Qwen 2.5 Coder - перспективная коллекция LLM для систем агентов
Разработчикам приложений Generative AI стоит обратить внимание на новую коллекцию моделей Qwen 2.5 и Qwen 2.5 Coder. С сентября 2024 года эти модели привлекают внимание разработчиков благодаря своей эффективности.
Во-первых, веса Qwen 2.5 доступны в версиях от 0.5B параметров — это очень легковесная модель — до 72B. Посередине есть 3, 7, 14 и 32B, каждую из которых вполне можно запускать локально, если у вас есть, например RTX 3080 с 16ГБ видеопамяти. В этом поможет квантизация (особенно в случае с 32B). Квантованные веса в форматах GGUF, GPTQ, AWQ есть в официальном репозитории.
Для более быстрого инференса и файнтюнинга Qwen 2.5 можно арендовать облачный GPU и работать с этой моделью так же, как с привычной нам Llama. Я показывал примеры файнтюнинга последней в предыдущих статьях, используя облачные видеокарты и стек Huggingface Transformers (код Qwen 2.5 добавлен в одну из последних версий transformers).
Есть базовая модель и версия Instruct, вы можете пробовать файнтюнить обе и смотреть, какой результат вам лучше подходит. Но если вы хотите взять готовую модель для инференса, то лучше конечно Instruct. Благодаря разнообразию размеров и форматов, Qwen может быть полезен для разных типов приложений - клиент-серверных, или десктопных, и даже на мобильных - вот как это выглядит:
Изображение взято из треда про адаптацию Квен под мобильные платформы:
Но по-настоящему Qwen 2.5 привлек внимание разработчиков, когда вышла коллекция Qwen 2.5 Coder. Бенчмарки показали, что 32 B версия этой модели может конкурировать с GPT-4o по написанию кода, а это очень интересно, притом что 32 миллиарда параметров вполне можно запустить на средней мощности видеокарте, и получить хорошую скорость генерации токенов.
Вообще какие приложения можно создавать с помощью новых моделей Qwen? Это конечно различные чатботы, но не только.
Разработчики говорят, что Qwen хорош для систем агентов.
Вот что написал недавно в Reddit один из них:
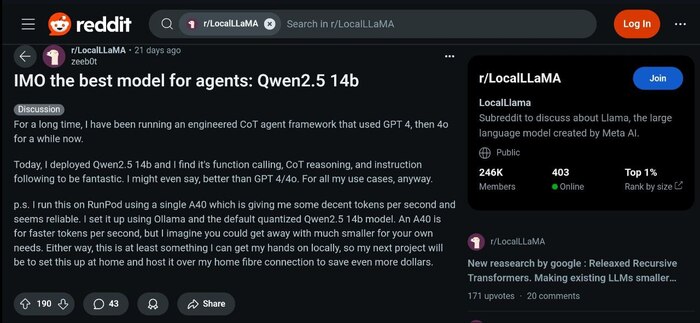
Я длительное время использовал кастомный Chain-of-thoughts фреймворк с GPT-4, затем 4o.
Сегодня я развернул Qwen 2.5 14B и обнаружил, что его возможности вызова функций, Chain of Thoughts и следования инструкциям фантастические. Я бы даже сказал, лучше чем GPT 4/4o - для моих задач, во всяком случае
Кажется интересным не только то, что разработчик получил такую высокую производительность для сложных задач, требующих продвинутой логики, на открытой LLM. Интересно и то, что для этого ему потребовались сравнительно небольшие мощности — ведь речь идёт о квантованной 14B модели:
Я использую одну видеокарту A40 для надёжности системы и высокой скорости генерации. Я выполнил установку через Ollama, взяв дефолтный квантованный Qwen 2.5 14B. A40 нужна для более высокой скорости, но я могу представить, что вам подойдёт и намного меньшая видеокарта для ваших задач
Мне нравится идея разработки агентских систем с помощью открытой модели на 14B параметров, для работы которой достаточно экономичной видеокарты A40 или даже менее мощной модели.
Агенты, вспомним, это GenAI приложения которые могут оперировать компьютером пользователя, взаимодействовать с другими программными компонентами. Для этого очень важна способность интегрироваться с разными API, вызов функций и логическое мышление модели.
По поводу логического мышления, традиционный подход — это Chain of Thoughts, особая стратегия промптинга. Она побуждает LLM строить пошаговые рассуждения, более эффективные для решения задачи и самовалидации решения на каждом шаге. Некоторые модели специально обучены для работы с таким промптом, например, GPT-4o1. Непонятно, обучали ли Qwen строить цепочки мыслей, но, как видим, разработчики указывают на высокую производительность модели в этом отношении.