У любой проблемы есть корневые и сопутствующие причины.
Задача
Установить причину неудачного нагрузочного тестирования СУБД по сценарию повышенной нагрузки на CPU.
Виртуальная машина 06
CPU = 2
RAM = 2GB
Astra Linux 1.7
PostgreSQL 15
Сценарий тестирования-1
Select only : 50% нагрузки
Select + Update : 30% нагрузки
Insert only : 15% нагрузки
Сценарий тестирования-2
Select only : 50% нагрузки
Select + Update : 30% нагрузки
Insert only : 15% нагрузки
CPU Load : 5% нагрузки
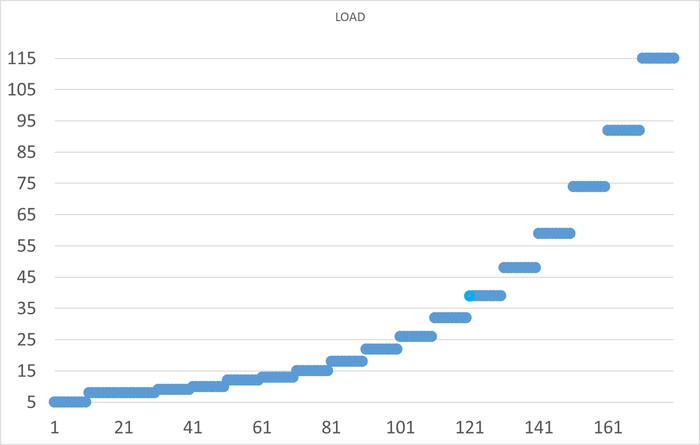
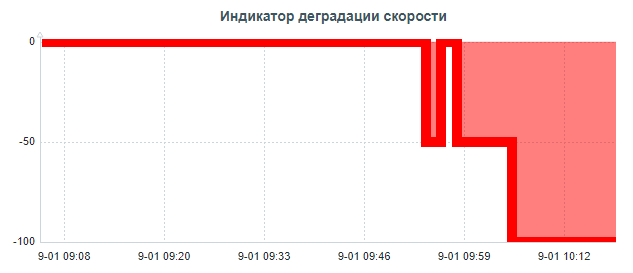
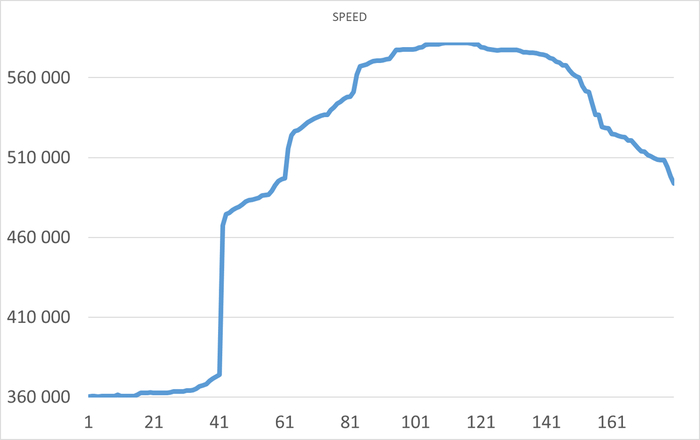
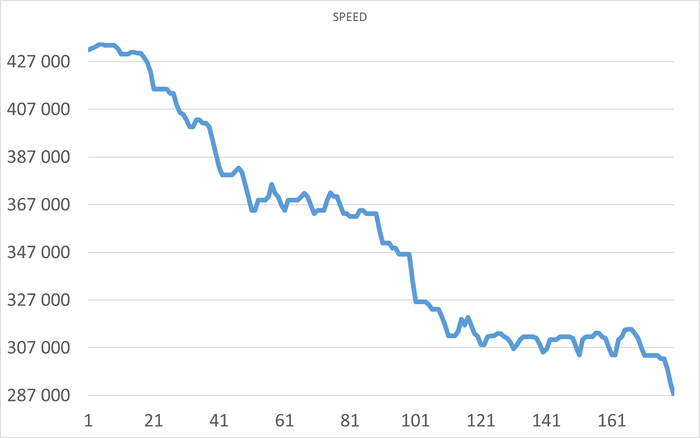
Нагрузка
Ось X - точка наблюдения. Ось Y - количество сессий pgbench
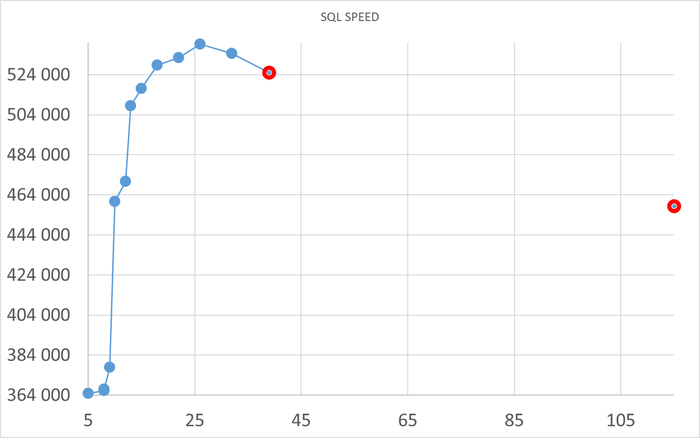
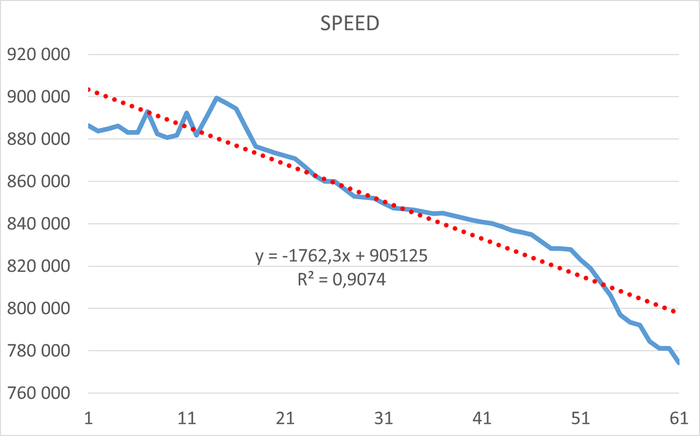
Операционная скорость - 2
Ось X - количество сессий pgbench. Ось Y - Операционная скорость.
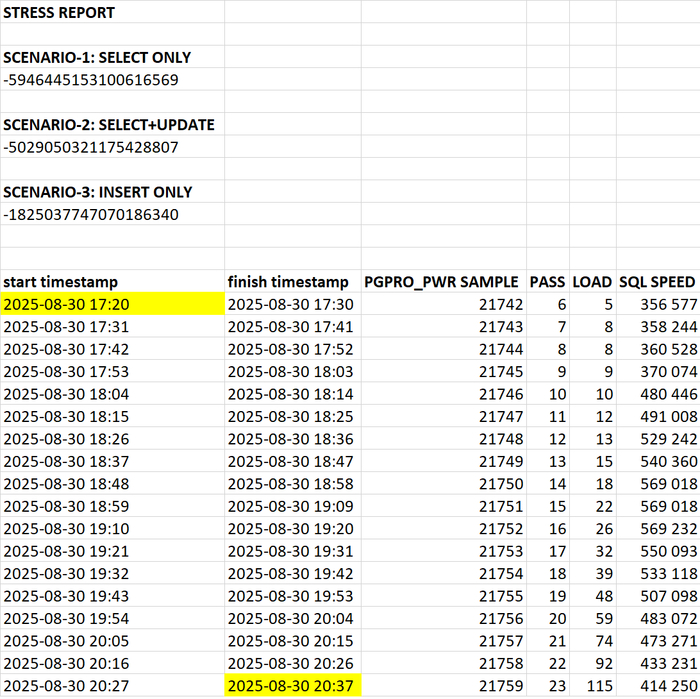
Отсутствуют данные по нагрузке 39 - 115 .
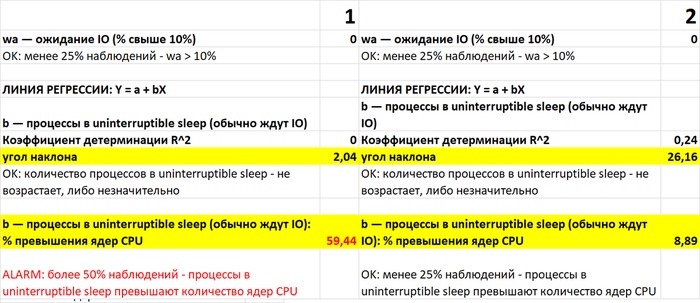
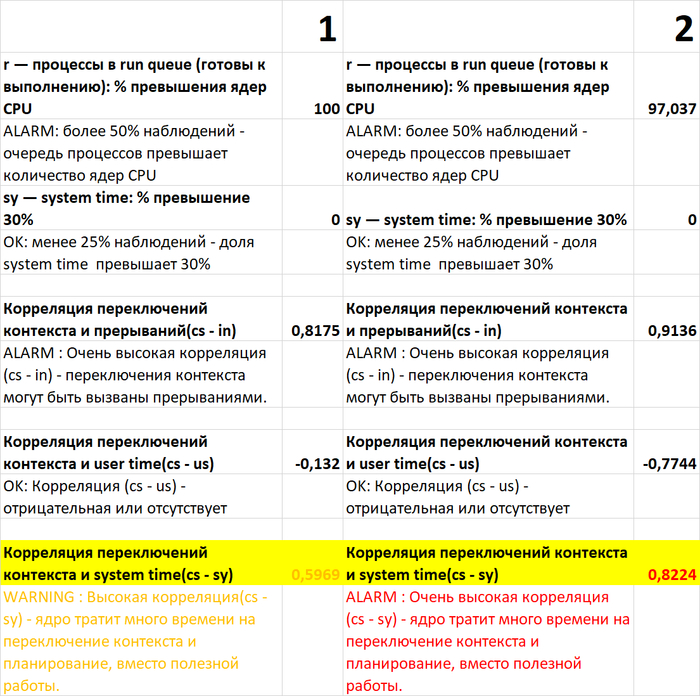
Чек-лист IO (сценарий-1 и сценарий-2)
Чек-лист CPU (сценарий-1 и сценарий-2)
Чек-лист RAM (сценарий-1 и сценарий-2)
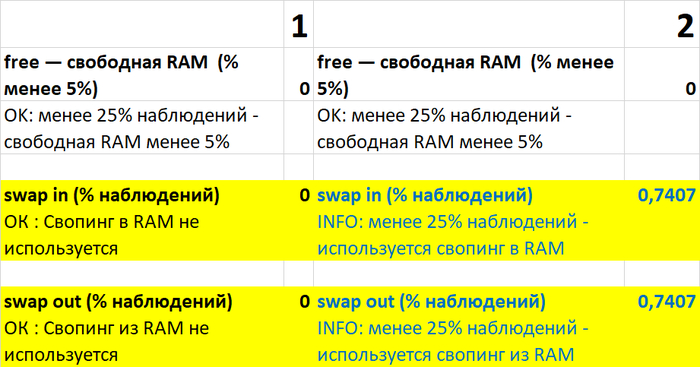
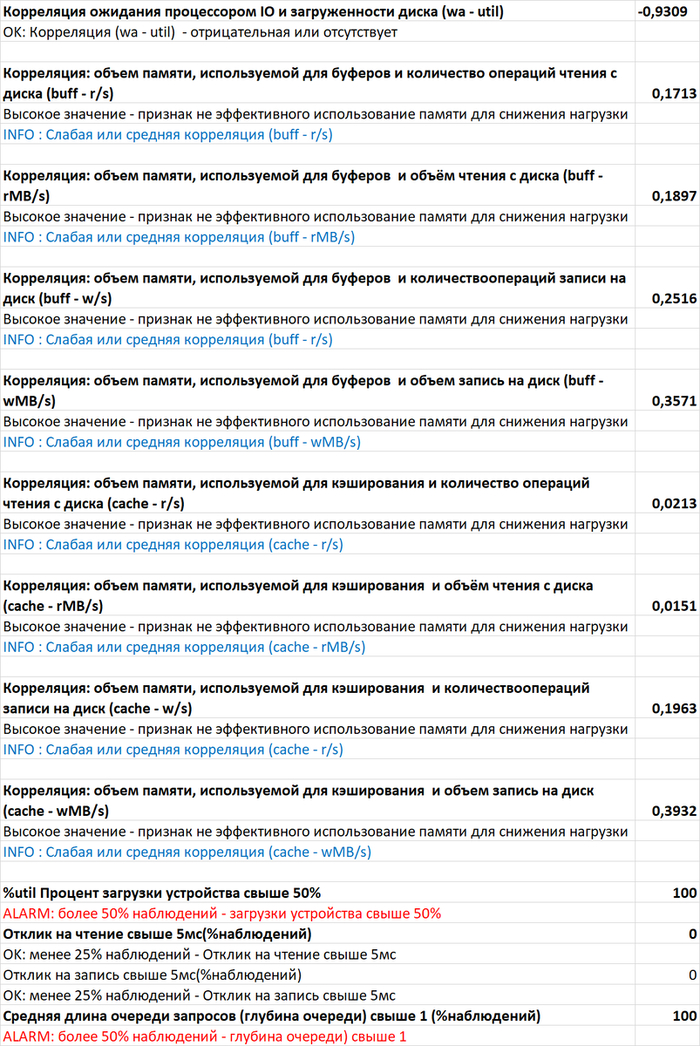
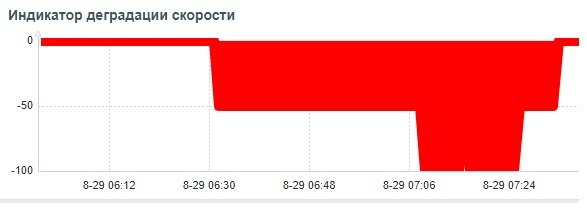
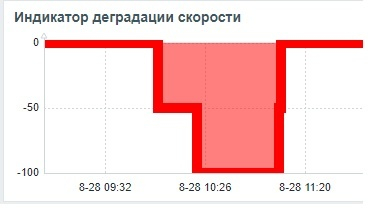
Причина ошибки сбора данных при нагрузочном тестировании по сценарию-2
Свопинг в ходе нагрузочного тестирования по сценарию-2.
📊 1. Механизм возникновения свопинга при нехватке памяти
При увеличении числа подключений к СУБД (например, с 5 до 115) каждый новый процесс требует выделения памяти для своих операций. Если физической памяти (RAM) недостаточно, система начинает использовать swap-пространство на диске для перемещения неактивных страниц памяти.
При конфигурации 2 GB RAM и интенсивной нагрузке на CPU процессы СУБД могут быстро исчерпать доступную оперативную память. Это активирует механизм подкачки, при котором демон kswapd начинает активно перемещать данные между RAM и диском, что дополнительно нагружает CPU.
⚙️ 2. Влияние свопинга на CPU и общую производительность
Процесс свопинга требует значительных вычислительных ресурсов. При активном использовании swap-пространства нагрузка на CPU может достигать 90-100%, причем большая часть этого времени тратится на системные (kernel) операции.
Это связано с тем, что ядро Linux должно управлять страницами памяти, определять, какие данные перемещать в swap, и обрабатывать дисковые операции ввода-вывода. В результате нагрузка на CPU возрастает даже при том, что основная задача свопинга — разгрузить оперативную память.
3. Экспоненциальный рост нагрузки и его последствия
Экспоненциальное увеличение числа соединений (с 5 до 115) приводит к нелинейному росту потребления ресурсов. Каждое новое соединение требует памяти для выполнения запросов, хранения временных данных и управления транзакциями.
При 2 GB RAM такой рост может быстро исчерпать доступную память. Например, если каждое соединение потребляет даже небольшой объем памяти (например, 20-50 MB), то при 115 соединениях общее потребление может превысить 2 GB, что активирует свопинг.
💎 Заключение
При конфигурации CPU=2 ядра и RAM=2 GB экспоненциальный рост нагрузки до 115 соединений с высокой вероятностью приведет к свопингу, что вызовет дополнительную нагрузку на CPU и может значительно снизить производительность СУБД.
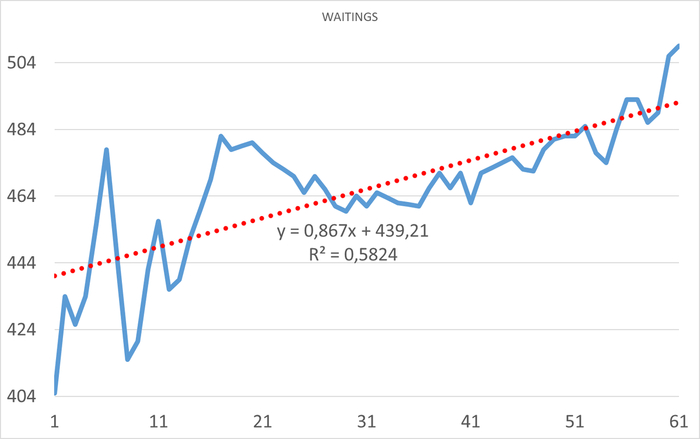
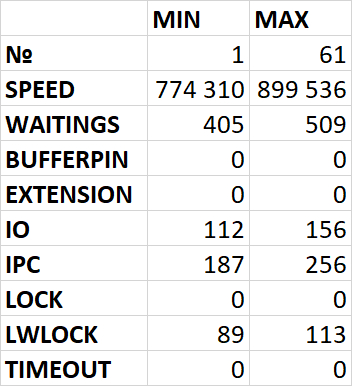
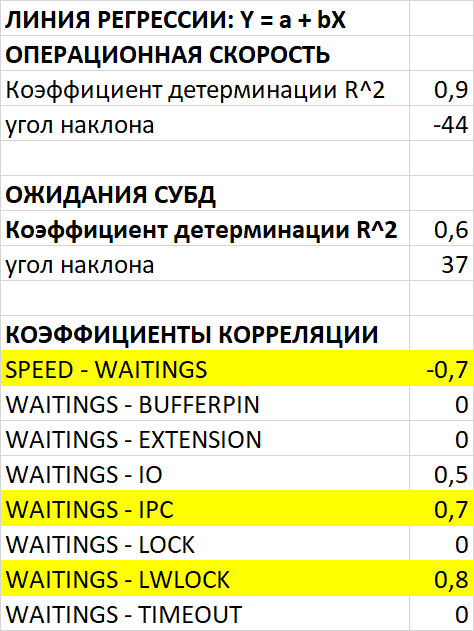
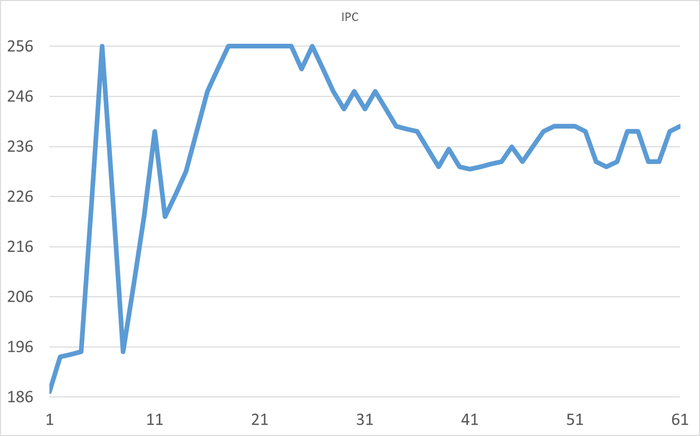
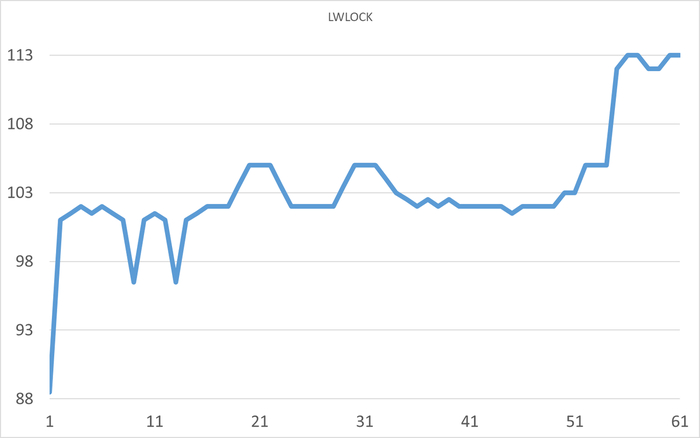
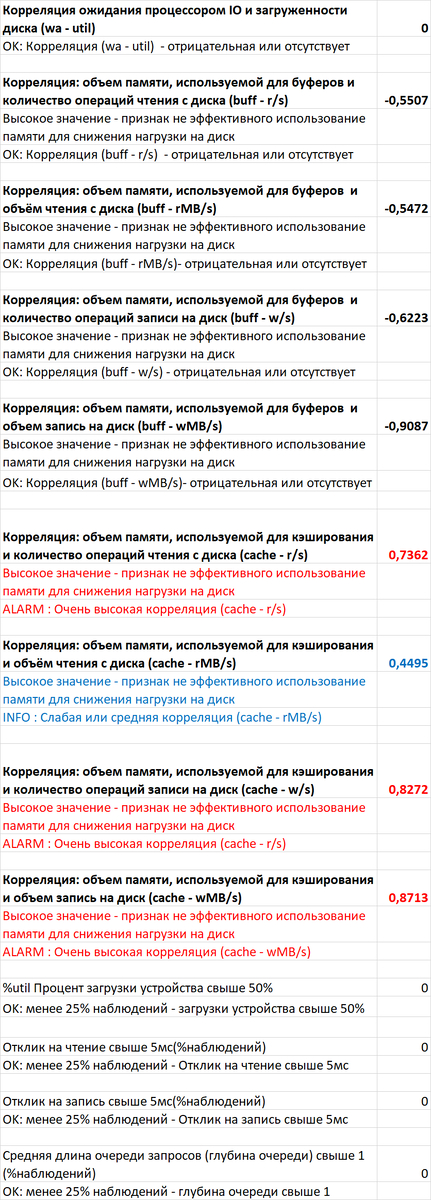
Провести корреляционный анализ ожиданий СУБД PostgreSQL и метрик Операционной системы для определения корневой причины деградации производительности СУБД.
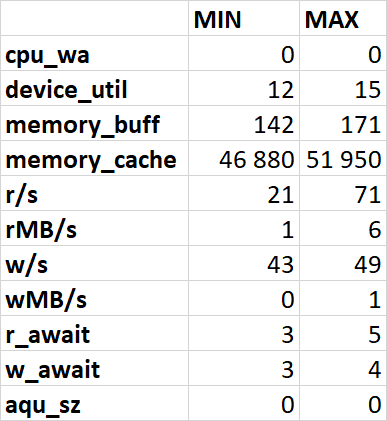
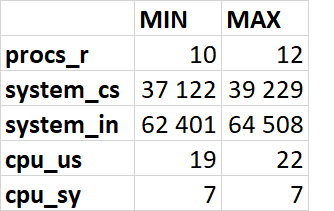
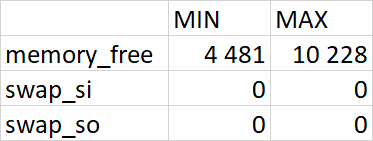
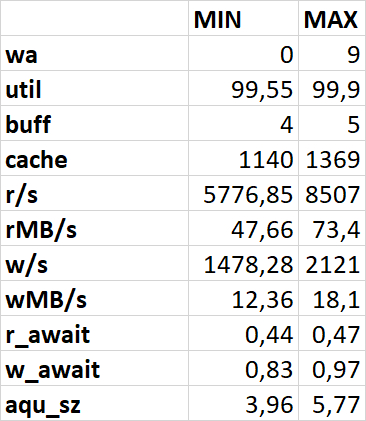
Минимальные и максимальные значение: Файловая система /data
wa (I/O wait): Важный показатель! Процент времени, в течение которого процессор простаивал в ожидании завершения операций I/O.
%util: Процент времени, когда устройство было занято обработкой I/O-запросов
buff: Объем памяти, используемой буферами (буферизация данных для записи на диск).
cache: Объем памяти, используемой кэшем (кэширование данных, прочитанных с диска). Свободная память = free + buff + cache (ядло освободит буферы и кэш при необходимости).
r/s: Количество операций чтения (запросов) в секунду
rMB/s: Объем данных, прочитанных с устройства в мегабайтах в секунду
w/s: Количество операций записи (запросов) в секунду
wMB/s: Объем данных, записанных на устройство в мегабайтах в секунду
r_await: Среднее время чтения (в миллисекундах).
w_await: Среднее время записи (в миллисекундах).
aqu-sz: Средняя длина очереди запросов к устройству. Значение больше 0 может указывать на накопление запросов.
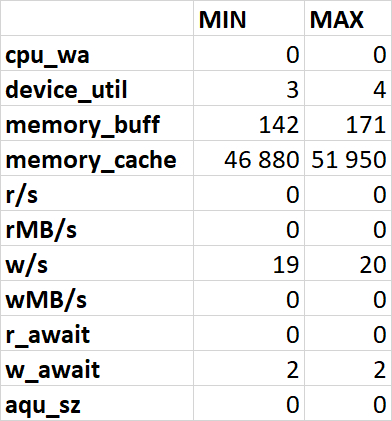
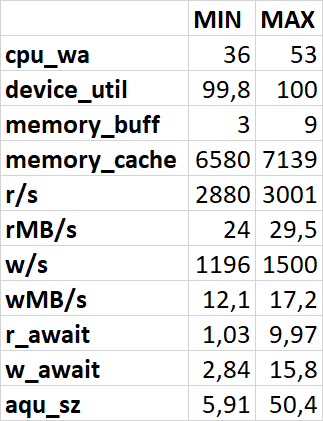
Минимальные и максимальные значение: Файловая система /data
wa (I/O wait): Важный показатель! Процент времени, в течение которого процессор простаивал в ожидании завершения операций I/O.
%util: Процент времени, когда устройство было занято обработкой I/O-запросов
buff: Объем памяти, используемой буферами (буферизация данных для записи на диск).
cache: Объем памяти, используемой кэшем (кэширование данных, прочитанных с диска). Свободная память = free + buff + cache (ядло освободит буферы и кэш при необходимости).
r/s: Количество операций чтения (запросов) в секунду
rMB/s: Объем данных, прочитанных с устройства в мегабайтах в секунду
w/s: Количество операций записи (запросов) в секунду
wMB/s: Объем данных, записанных на устройство в мегабайтах в секунду
r_await: Среднее время чтения (в миллисекундах).
w_await: Среднее время записи (в миллисекундах).
aqu-sz: Средняя длина очереди запросов к устройству. Значение больше 0 может указывать на накопление запросов.
Cравнительный анализ преимуществ комплекса pg_hazel перед системой pgpro_pwr в контексте мониторинга производительности PostgreSQL
Мониторинг производительности базы данных играет ключевую роль в управлении эффективностью и надежностью современных информационных систем. Своевременное обнаружение узких мест, оптимизация структуры запросов и настройка параметров системы помогают поддерживать высокий уровень работоспособности приложений, работающих с большими объемами данных.
На сегодняшний день рынок предлагает множество инструментов для мониторинга и анализа производительности PostgreSQL — одной из самых распространенных систем управления реляционными данными (СУБД).
В частности, заслуживают внимания такие продукты, как комплекс pg_hazel и система pgpro_pwr, которые широко используются в корпоративных инфраструктурах.
Настоящий материал посвящен детальному сравнению этих двух решений и выяснению их сильных сторон применительно к задачам повышения производительности PostgreSQL.