

Итак, Qwen 3
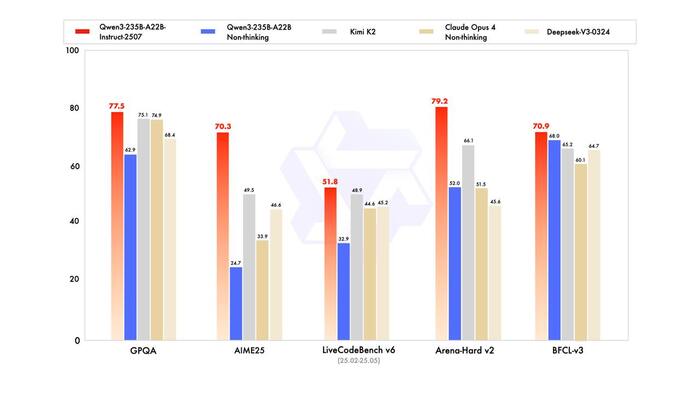
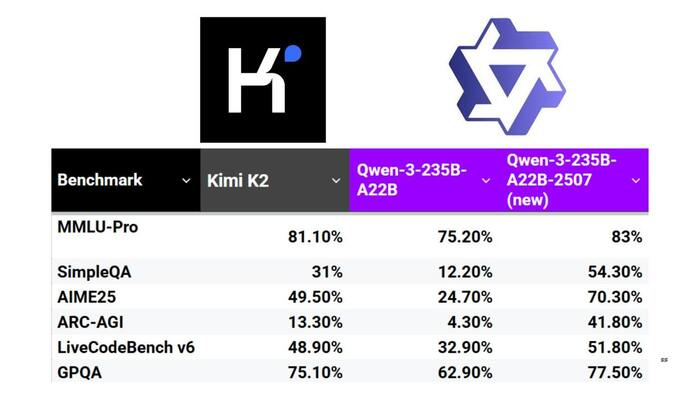
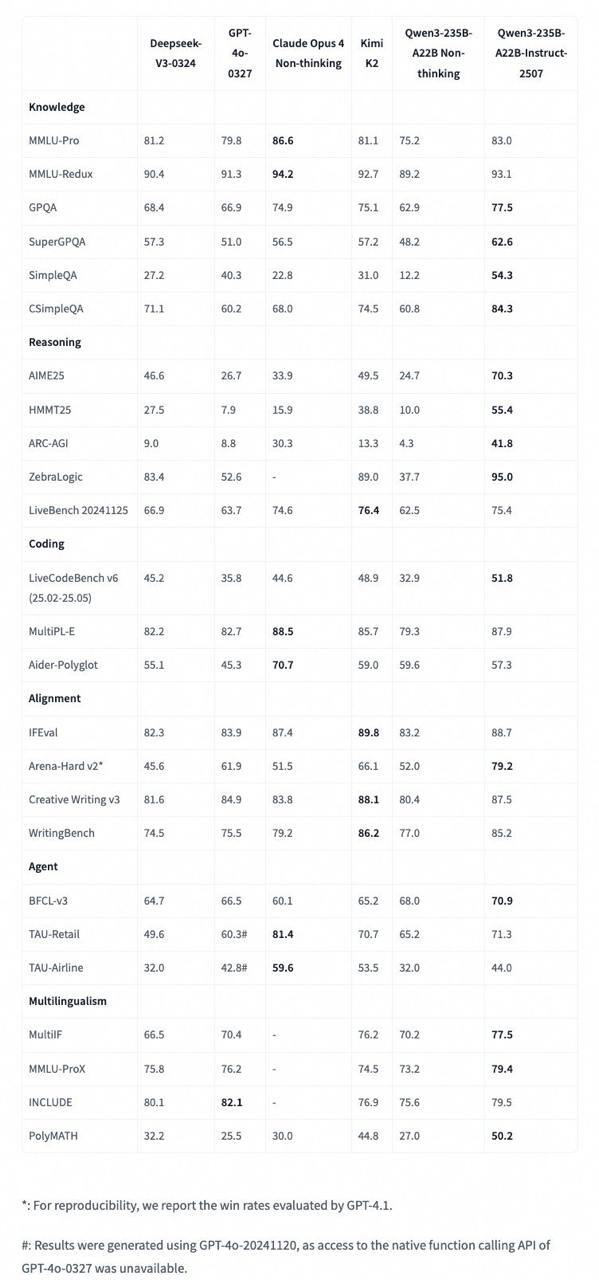
Сперва про Qwen3-235B-A22B-Instruct-2507-FP8
Это не просто апдейт: теперь Qwen отказывается от гибридных моделей, разделяя их на отдельные линии — Instruct и Reasoning. Сегодня у нас Instruct, reasoning будет позже.
Что нового и почему стоит обратить внимание?
* Метрики отличные: по ряду тестов обходит даже Kimi K2 (qwen такая же послушная, но более креативная), на некоторых задачах превосходит Claude 4 Opus (non-thinking), а цена в десятки раз меньше
* Большой прирост на ARC-AGI, лучше понимает инструкции и умеет держать хороший контекст — до 262K токенов.
* Цена как у самых маленьких моделей: $0,12/M input, $0,59/M output (уже есть в OpenRouter)
* Креативность сохраняется даже на низкой температуре, хорошо держит промпт и не уходит “в сторону”, как это бывает у конкурентов — очень хорошо подходит для ИИ-агентов. Причём это китайская модель, и она хорошо понимает азиатские языки — лучше, чем gpt
* Прямо сейчас можно использовать через chat.qwen.ai и openrouter.ai
---
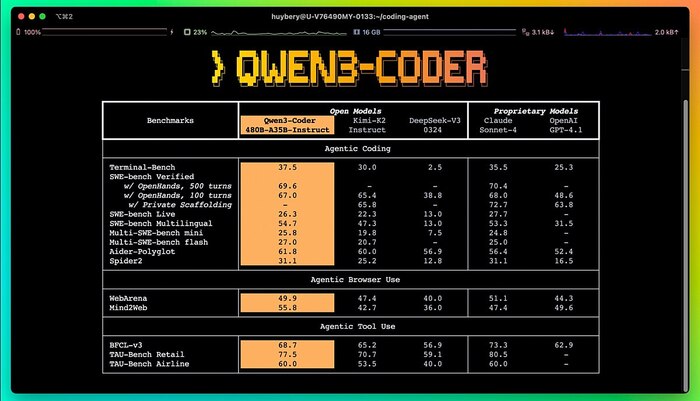
• Qwen3-Coder — мощный конкурент Claude Code
Это полноценная open-source кодовая модель на 35B активных параметрах, с контекстом до 1M токенов (наконец-то конкурент Gemini!). Но при этом также стоит копейки — $1/M input и $5/M output, это дешевле gpt-4.1
Но пока что тоже не думающая. Ждём вариант thinking, чтобы повысить планирование и багфиксинг.
В бенчмарках — на уровне Sonnet 4, иногда даже Opus. Работает бесплатно через Qwen Chat: можно грузить кодбазу, использовать CLI, интегрировать в свои пайплайны.
— Также работает и через openrouter.ai (а значит можно использовать в Cline, Kiro, RooCode)
— GitHub
— HuggingFace
В целом Qwen уверенно выходит в топ-3 самых интересных open-source LLM прямо сейчас. Если нужен рабочий “мозг” для агента или автоматизации, советую не пропускать. Меня лично очень порадовало, особенно обычный qwen-3
—
Мой тг-канал по ии-стартапам и вайб-коду
Искусственный интеллект
5K постов11.5K подписчика
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан