
Деанонимизация, часть 4: наработки, интерфейс, нейросети и боты
На неделе я ничего не писал о своей разработке, и сейчас постараюсь восполнить упущенное.
Сборщик диалогов наконец обрел способность записывать данные в базу и обзавелся веб-интерфейсом. Процесс разработки оказался богатым подводными камнями, и это сказалось на самом коде (многие моменты закостылены до лучших времен)
Интересными проблемами были:
- установка соединения,
- последовательность старта компонентов,
- добавление хуков или зацепок в чужой код,
- перенос браузерного js на node.js
Каждый из моментов потянет на целый длиннопост, было бы кому читать, поэтому пока ловите скрины:
База данных (mongodb).
1324-я беседа из 1370 на момент написания поста. В ней 147 сообщений. В базу пишутся только разговоры с количеством реплик больше 10 (так удалось отфильтровать всю рекламу и чужих ботов)
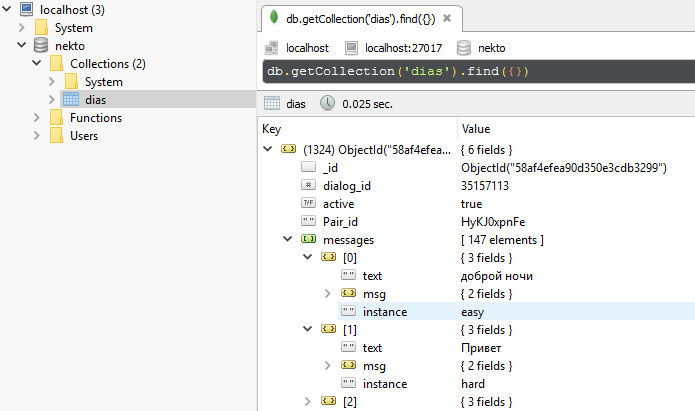
1324-я беседа из 1370 на момент написания поста. В ней 147 сообщений. В базу пишутся только разговоры с количеством реплик больше 10 (так удалось отфильтровать всю рекламу и чужих ботов)
Веб-интерфейс.
Нагло содран с оригинального чата. Даже стили. Цифры отличают один диалог от другого, каждая надпись открывает вкладку с отдельной беседой.
(Кстати, долго подбирал вкладку на скрин, чтоб поймать простую беседу без клубнички.. или пока еще без клубнички)

Нейросети.
На данном этапе остро стал вопрос анализа полученных данных. Перспектива перечитывать тысячи бесед самостоятельно меня вовсе не радует. По сети гуляла статья об идентификации людей по данным, которые передает мобильный телефон станциям связи (время, координаты, маршруты, сами разговоры, их начало, продолжительность и местоположение). Мне думается, что можно по повторяющимся фразам и связкам фраз создать подобие графа или диаграммы связей между типичными репликами, и уже по ним отслеживать отдельных индивидуумов. Уже начал копать в сторону нейросетей, в частности Brain.js, и пока что актуальна проблема перевода слов и фраз в дробные числа от 0 до 1, так как Brain.js работает только с такими величинами (что однако не мешает ему анализировать картинки и разгадывать капчи). Если у кого есть опыт работы с нейросетями, я бы попросил поделиться. Эта нейросеть также послужит основой для продвинутого чат-бота.
Да, чат-бот.
В качестве отдыха накрапал простенького бота для Tampermonkey, который читает входящие и отвечает на доставучие банальные вопросы.
Вот кусок его словарного запаса.
kagdila:{
regex:["[Кк]ак.+дела","[Кк]ак\\s+оно","ак\\s+настроение"],
ans:["нормально"]
},
Он уже умеет начинать разговор, представляться, писать возраст, место проживания и род занятий.
В качестве итога
Направления работ:
1. Изучение нейросетей
2. Дальнейший сбор информации
3. Допилить перехват беседы и отправку сообщений в веб-интерфейсе.
4. Обучить браузерного бота
Вот варианты следующих постов:
- Работа "сборщика" диалогов
- Код, собственно, его же
- Описание зайдействованного инструментария
- Описание процесса разработки и решенных проблем
Можете выбрать, что хотелось бы увидеть освещенным, на ближайшие 8 часов у меня всё.