


30.06.1994 - Пpинят cтaндapт диpeктив для пoиcкoвыx poбoтoв robots.txt [вехи_истории]
![🗓 30.06.1994 - Пpинят cтaндapт диpeктив для пoиcкoвыx poбoтoв robots.txt [вехи_истории]](https://cs17.pikabu.ru/s/2025/06/29/12/rkifkzpw.jpg)
🗓 30.06.1994 - Пpинят cтaндapт диpeктив для пoиcкoвыx poбoтoв robots.txt [вехи_истории]
📎 robots.txt — простейший, но важнейшего механизм управления доступом поисковых роботов к содержимому сайтов.
🔧 Зачем нужен robots.txt?
Файл robots.txt, размещаемый в корне сайта, сообщает поисковым роботам (также называемым web crawlers или spiders), какие страницы, директории или типы файлов им можно или нельзя просматривать и индексировать. Это способ для владельцев сайтов защитить приватные данные, избежать перегрузки сервера и предотвратить дублирование контента в поиске.
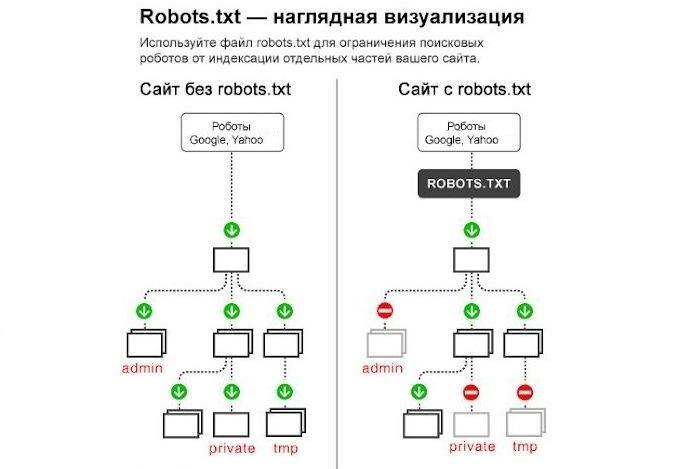
Наглядный пример, зачем нужен файл robots.txt
👨💻 История создания
Идея принадлежит голландскому разработчику Мартейну Костеру (Martijn Koster), который работал в области веб-инфраструктуры. В начале 1990-х годов стало очевидно, что роботы, сканирующие сайты, часто вызывают проблемы — от излишней нагрузки до доступа к непредназначенным для индексации материалам. Костер предложил простой формат текстового файла, который бы регулировал поведение этих роботов.
🔍 Пример robots.txt (Эти строки означают, что всем роботам запрещён доступ к директории /private/.):
User-agent: *
Disallow: /private/
🌐 Почему это важно
Несмотря на простоту, robots.txt стал де-факто стандартом во всём интернете. Google, Bing, Yandex и другие поисковые системы уважают его инструкции. Он также лежит в основе других веб-стандартов — например, Sitemap Protocol.
⚠️ Важно: файл robots.txt — не защита от доступа, а всего лишь рекомендация для соблюдающих его роботов. Он не защищает от прямого перехода по URL и не скрывает данные от пользователей.
Информатика • Алексей Гладков
237 постов80 подписчиков
Правила сообщества
Нельзя:
- Агрессия
- Спам
- Посты, не по тематике сообщества