


Клип в чернобыле
как думаете реально или хромакей
как думаете реально или хромакей
Ущерб от действий преступника оценивается примерно в 10 млн рублей.
Прокуратора Ульяновска утвердила обвинительное заключение в отношении местного жителя, неоднократно пытавшегося сжечь офис регионального управления Роскомнадзора. Мотивом преступления стала блокировка ведомством пиратского сайта, где обвиняемый мог беспрепятственно смотреть видео.
По данным прокуратуры, попытки поджога офиса РКН, расположенного в Ульяновске на улице Карла Маркса, осуществлялись трижды - 2 и 15 апреля, а также 9 мая 2018 года. Поджигатель ночью камнями и молотком разбивал окна в офисе ведомства, а затем разливал легковоспламеняющуюся жидкость и поджигал ее охотничьими спичками. Ущерб от действий преступника оценивается примерно в 10 млн рублей.
В отношении киномана возбуждено уголовное дело по ч.3 ст.30, ч.2 ст.167 УК РФ (покушение на уничтожение и повреждение чужого имущества, повлекшее причинение значительного ущерба, совершенное путем поджога). Данная статья предусматривает наказание в виде лишения свободы сроком до 5 лет. Дело направлено в суд для рассмотрения по существу.
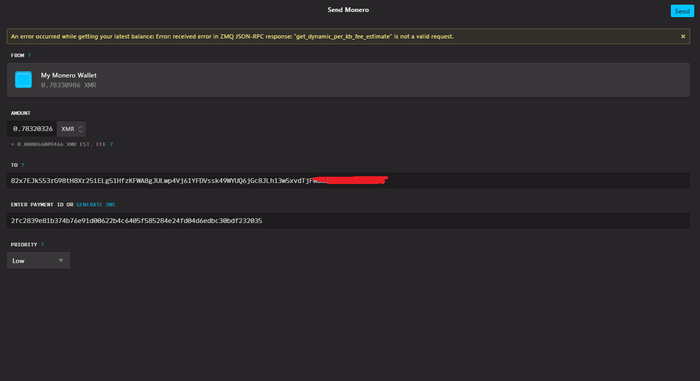
Извиняюсь за возможно глупый вопрос
Но, подскажите пожалуйста, что я делаю не так. почему транзакция не проходит?
что это за ошибка
кошель https://wallet.mymonero.com/

В Лаборатории искусственного интеллекта MIT опубликовали Speech2Face — модель, которая реконструирует лицо человека по записи его голоса. Нейросеть обучалась на миллионах видеозаписей с YouTube, на которых демонстрируется разговор человека. Задача заключалась в том, чтобы понять, может ли голос отражать внешние характеристики его обладателя. Исследователи не фокусировались на том, чтобы точно реконструировать портрет человека по голосу, а на том, чтобы восстановить основные внешние характеристики.
Архитектура модели
На вход модель принимает спектограмму аудиозаписи голоса. Спектограмма — визуальное представление аудиоволн. На выходе модель отдает вектор размером в 4096 с характеристиками лица, который затем декодируется в изображение лица. Декодирование из вектора с характеристиками в изображение лица происходит с помощью предобученной нейросети.Обучалась модель на датасете AVSpeech. Для этой цели исследователи использовали предобученную VGG-Face.Пайплайн обучения модели можно разделить на два шага:
1. Кодировщик голоса, который принимает на вход спектограмму и предсказывает вектор с характеристиками лица человека;
2. Декодировщик лица, который принимает на вход вектор с характеристиками лица человека и генерирует лицо человека в стандартном формате (анфас и безэмоциональное)
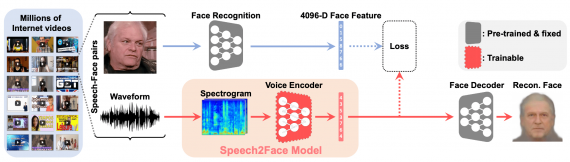
Во время обучения декодировщик лица был зафиксирован и обучался только кодировщик голоса. Декодировщик лица исследователи взяли готовым из работы Cole et al.
Оценка работы модели
Нейросеть была протестирована с помощью качественных и количественных метрик. Во время экспериментов модель тестировалась на датасетах AVSpeech и VoxCeleb. Ниже можно, что чем длиннее входная аудиозапись (3 сек против 6 сек), тем выше количественная метрика и тем ближе сгенерированное изображение к истинному.










