


Миллиард на хайпе!

В мае 2024 года Илья Суцкевер, ранее занимавший пост главного научного руководителя OpenAI — компании, ответственной за разработку ChatGPT, сообщил о своем уходе и запуске нового стартапа под названием Safe Superintelligence (SSI).
ДЛЯ СПРАВКИ: Родившись в 1984 году в Нижнем Новгороде, он эмигрировал с семьей в Израиль в 1991 году, а затем переселился в Канаду. Да, целых семь лет Илья был нашим земляком.
Помните ту историю с зеленым гигантом, когда начались сподвижки внутри проекта, а часть сотрудников из совета директоров были уволены? Так вот, эта та история. Суцкевер просто сказал, что не хочет опасного AGI в современном мире, поэтому постарается сделать вклад в безопасное ИИ, и уволил Сэма Альтмана.
После массового бунта сотрудников, Сэма вернули к должности, а сам Суцкевер решил окончательно уйти из проекта добровольно.
Их новый стартап SSI фокусируется исключительно на разработке безопасного суперинтеллекта.
Суцкевер уточнил, что основная цель стартапа — создание безопасного искусственного интеллекта, представляющего собой единственный продукт, на котором будут сконцентрированы все усилия команды, что, по его словам, требует единственного и точного подхода.
Компания SSI намерена базироваться сразу в двух ключевых центрах технологической индустрии — в Пало-Альто, Калифорния, и в Тель-Авиве, Израиль.
Помимо самого Суцкевера, в состав сооснователей вошли две влиятельные фигуры, также обладающие значительным опытом в вычислительной информатике и ИИ: Дэниэл Гросс, ранее возглавлявший отдел ИИ-разработок в компании Apple, и Дэниэл Леви, который в прошлом также сотрудничал с OpenAI.
Такой состав основателей подчеркивает высокую степень профессионализма и амбициозность нового проекта, настолько подчеркивает, что инвесторы задонатили ребятам по 5 млрд долларов.
В интервью, данном агентству Bloomberg, Суцкевер воздержался от раскрытия информации о спонсорах, поддерживающих новый стартап, равно как и о суммах, уже привлеченных в проект.

Однако Дэниэл Гросс, его сооснователь, отметил, что вопросы привлечения капитала — не особо серьезное препятствие для компании на текущем этапе. Может быть, что у SSI есть серьезные инвест-потоки…
Суцкевер пояснил: проект будет огражден от внешнего давления, часто сопровождающего создание масштабных и сложных продуктов, а также от необходимости участвовать в конкурентной гонке. Это круто, если посмотреть на компании-соседи по типу OpenAI или Google…
Под безопасностью суперинтеллекта он подразумевает, к слову, нечто, схожее по важности с ядерной безопасностью, однако этот аспект не следует путать с более обыденными понятиями вроде «доверия» и «безопасности». Ключевым моментом в этом контексте является стремление выйти за пределы современных языковых моделей, которые, хотя и доминируют на рынке ИИ, не отвечают требованиям безопасности суперинтеллекта в полной мере
Галлюцинации, ложь и откровенно адские заявления LLM при провокации вызывают опасения.
Современные системы ИИ позволяют пользователям лишь общаться с моделью, однако суперинтеллект должен представлять собой нечто значительно более мощное — своего рода гигантский центр обработки данных, способный к самостоятельному разработке новых технологий.
Основная задача SSI заключается в том, чтобы внести вклад в обеспечение безопасности таких систем. Суцкевер особенно акцентировал внимание на том, что фундаментальное свойство безопасного суперинтеллекта заключается в его способности не причинять человечеству широкомасштабного вреда, но не частного.
Биографическая справка о Суцкевере помогает лучше понять его мотивацию и мировоззрение.
AGI, по его мнению, способен значительно превзойти человеческие возможности, что может представлять серьезную угрозу, если не будет создано соответствующее согласование этих технологий с фундаментальными человеческими ценностями.
В конце 2022 года Суцкевер публично выразил беспокойство тем, что в будущем AGI может начать воспринимать людей так же, как сейчас люди воспринимают животных, что лишь подчеркивает остроту этических и философских вопросов, связанных с развитием этих технологий.
В каком направлении проект может продвинуться?
Для повышения интерпретируемости важно разработать модели, которые можно подвергать проверке и анализу на каждом этапе их работы.
Например, вместо использования слишком сложных моделей, которые трудно интерпретировать, можно разработать более простые модели или гибридные системы, которые сочетают в себе мощь глубокой нейронной сети и традиционных алгоритмов, таких как логистическая регрессия или деревья решений.
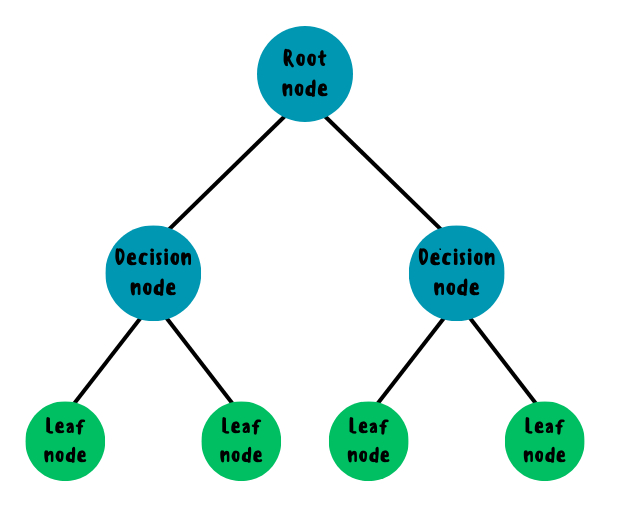
Технически они представляют собой иерархическую структуру, где каждый внутренний узел соответствует проверке определенного условия по одному из признаков данных, а каждая ветвь — это результат этой проверки, ведущий к следующему узлу или листу дерева. Листья, в свою очередь, представляют собой конечные классы или значения, которые модель предсказывает.
Процесс построения дерева решений можно разделить на несколько ключевых этапов, которые обеспечивают интерпретируемость модели.
Разбиение данных на основе признаков (feature splits). На каждом шаге построения дерева выбирается признак, по которому данные будут разделены на подмножества. Это выбор основан на критерии, который максимизирует чистоту (homogeneity) подмножеств.
Чистота измеряется с помощью таких метрик, как энтропия или индекс Джини, которые оценивают степень однородности данных в каждой ветви после разбиения.
Цель алгоритма заключается в том, чтобы на каждом этапе минимизировать неопределенность или разнородность в подмножестве данных, тем самым улучшая точность предсказаний.
После выбора признака, данные разделяются по порогу или категориальным значениям, и процесс повторяется рекурсивно для каждого нового подмножества.
Это разбиение продолжается до тех пор, пока не достигнуты либо заданные критерии остановки, либо все данные в узле однородны, либо глубина дерева не превышает допустимого предела.
Важно отметить, что каждое решение в дереве связано с конкретным признаком, что делает процесс принятия решения легко интерпретируемым: каждый узел дерева представляет логическое условие, а путь от корня к листу — это последовательность условий, объясняющих, как было достигнуто предсказание.
Благодаря такой структуре деревья решений легко визуализировать и анализировать. Каждое решение можно проследить шаг за шагом, изучив, какие признаки были использованы на каждом этапе и каким образом они привели к конечному результату.
Один из доп направлений повышения интерпретируемости — использование пост-хок интерпретируемых методов.
Пост-хок интерпретируемые методы играют ключевую роль в интерпретации сложных моделей машинного обучения и нейронных сетей, когда их структура слишком сложна для непосредственного анализа.
Такие методы применяются уже после того, как модель обучена, и их задача заключается в создании инструментов для анализа связи между входными данными и выходными решениями модели. Они предоставляют разработчикам и исследователям способы деконструкции «черного ящика», позволяя выявлять причинные зависимости и зоны чувствительности внутри модели.
Один из важнейших пост-хок методов — это вычисление важности признаков (feature importance). Важность признаков измеряет, насколько сильное влияние каждый отдельный признак (feature) оказывает на выход модели.
Например, можно использовать обратное распространение ошибки (backpropagation) для определения того, насколько изменение конкретного признака влияет на изменение выходного значения.
Один из вариантов этого подхода — градиентный, который использует производные выходного значения модели по отношению к каждому признаку, что позволяет оценить их значимость.
В случае нейронок, где прямой расчет значимости признаков становится затруднительным, применяются такие техники, как интегрированные градиенты (integrated gradients), которые усредняют вклад каждого признака по траектории от базовой точки до текущего состояния модели.

Другой мощный метод — это LIME (Local Interpretable Model-agnostic Explanations). Этот алгоритм фокусируется на интерпретации локальных решений модели.
LIME работает на основе создания приближенной модели для небольшой области вокруг конкретного предсказания, используя простые линейные модели, которые легче интерпретировать.
Процесс включает в себя выбор подмножества данных вблизи исходной точки предсказания и построение на них модели, которая приближает работу исходной сложной модели. Таким образом, LIME позволяет интерпретировать сложные модели даже в том случае, если они изначально не предоставляют информации о структуре своих решений.
Grad-CAM (Gradient-weighted Class Activation Mapping) — это техника визуализации, специально разработанная для глубоких сверточных нейронных сетей (CNN). Grad-CAM позволяет выявить области на входном изображении, которые наиболее сильно влияют на активации последних слоев сети, отвечающих за принятие решения.
Этот метод использует градиенты выходных активаций по отношению к активациям внутри сверточных слоев, чтобы визуализировать, какие части изображения были наиболее значимыми для сети.
Grad-CAM генерирует тепловую карту (heatmap), которая показывает, какие участки изображения имеют наибольшую важность для конкретного предсказания, тем самым улучшая интерпретируемость моделей в задачах компьютерного зрения.
Еще один класс методов, который можно отнести к пост-хок интерпретируемости, включает в себя методы пертурбации. Здесь используется идея модификации входных данных с целью оценки чувствительности модели к изменениям определенных признаков.
Простейший пример — это замена одного из признаков или его значения на случайное или экстремальное, чтобы оценить, как модель реагирует на такие изменения.

Другие техники связаны с объяснением решений через построение «суррогатных» моделей. Это такие модели, которые приближают сложные модели, используя более простые структуры, например, деревья решений или линейные модели.
Такие суррогатные модели служат для создания интуитивно понятных интерпретаций сложных предсказательных алгоритмов.
Например, в задачах классификации могут быть использованы методы построения деревьев, которые приближенно повторяют логику работы нейросети, предоставляя аналитический способ для понимания того, как были приняты решения в ключевых узлах сети.
Пост-хок методы не без недостатков: их интерпретируемость и применимость могут быть ограничены за счет того, что они не всегда точно отражают внутренние процессы сложных моделей, а лишь приблизительно интерпретируют результаты.
Но в самом деле… все эти методы не обеспечивают реальной безопасности и совершенно убивают трансформерные преимущества LLM. Получится ли у бывшего сотрудника OpenAI создать безопасный ИИ без вреда эффективности?



