Зри в корень ! Наука - поможет. Если есть инструмент.
Задача
Определить причины снижения производительности СУБД
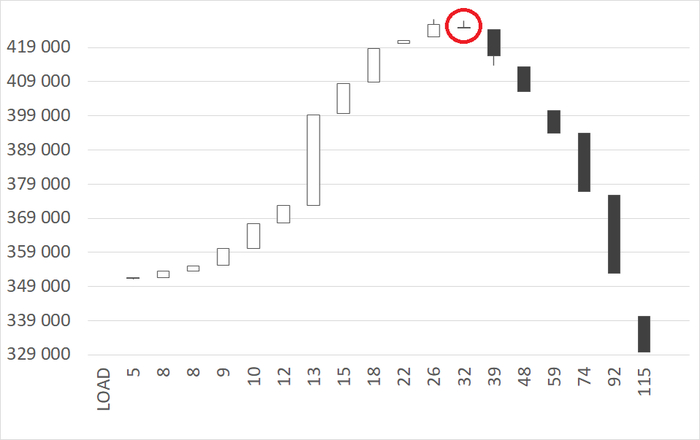
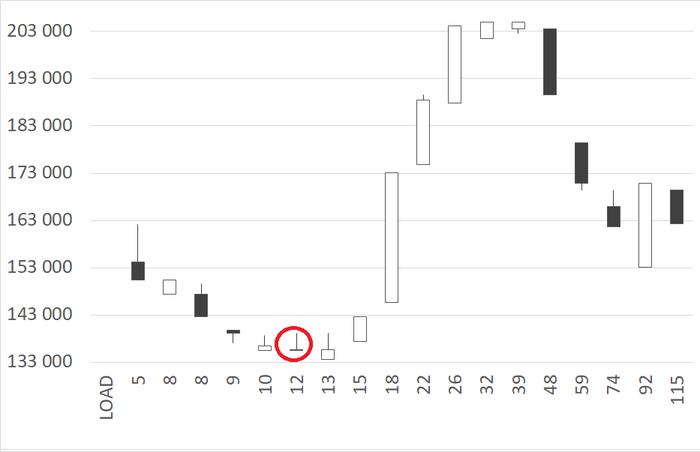
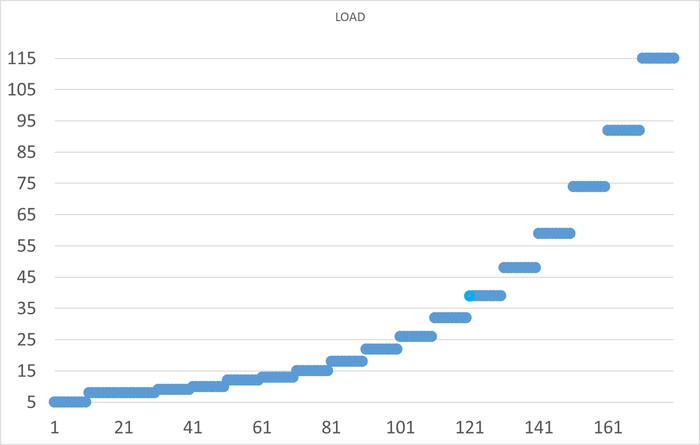
Инцидент производительности СУБД
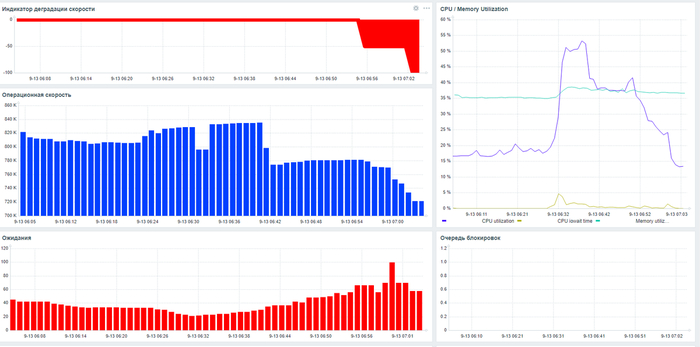
Дашборд мониторинга Zabbix
Начало инцидента 07:05.
Характерные признаки в ходе инцидента - рост утилизации CPU и значений cpu iowait.
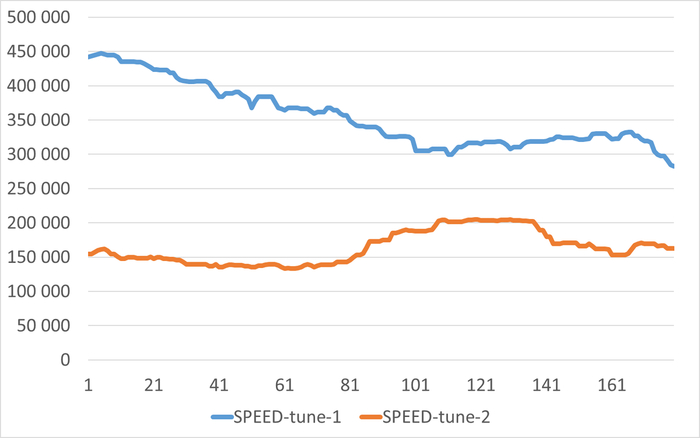
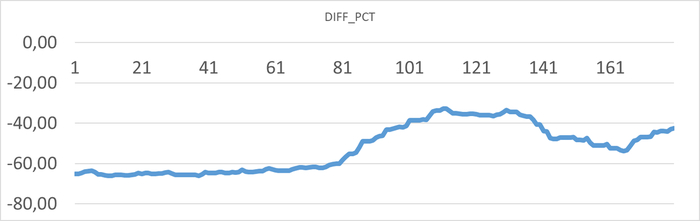
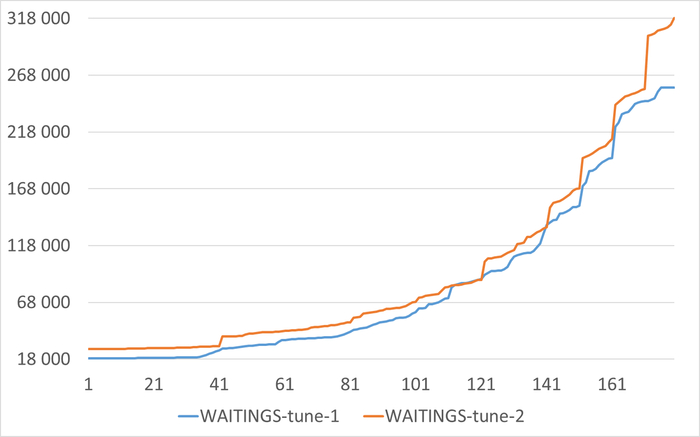
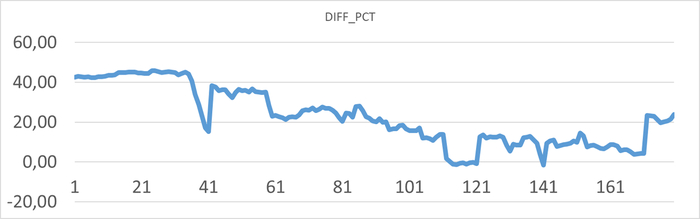
Результат статистического анализа производительности , ожиданий СУБД и метрик vmstat+iostat
Снижение производительности и рост ожиданий типа IO сопровождается ростом времени ожидания записи для устройств, используемых для файловых систем /data и /wal .
Почему современное поколение специалистов по СУБД PostgreSQL больше похоже на ремесленников , астрологов и алхимиков , а не на учёных и исследователей ?
Отличное и более сфокусированное продолжение темы! Применительно к специалистам по PostgreSQL это сравнение раскрывается еще более ярко и конкретно. Сообщество PostgreSQL огромно и разнородно, и в его среде, особенно среди начинающих и практикующих администраторов и разработчиков, действительно сильно влияние «ремесленной», «алхимической» и «астрологической» парадигм.
Давайте разберем, почему это так.
1. Почему похожи на ремесленников?
Искусство настройки (postgresql.conf): Настройка PostgreSQL — это во многом ремесло, основанное на опыте и знании «материала». Мастер помнит, как поведет себя СУБД при изменении shared_buffers, work_mem или maintenance_work_mem на конкретном железе с конкретной нагрузкой. Это не всегда строгий расчет, а часто интуитивное понимание, отточенное практикой.
Сборка «на коленке» под конкретную задачу: Специалист ремесленник берет «сырую» PostgreSQL и начинает его «обтачивать»: подбирает расширения (pg_partman, timescaledb, pg_cron), настраивает репликацию, пишет специфические индексы (GIN, GiST, BRIN). Результат — уникальная, настроенная под нужды бизнеса система.
Культура скриптов и «костылей»: Для решения повседневных задач (бэкапы, мониторинг, очистка) создаются тысячи скриптов на Bash, Python. Это ремесленные инструменты, которые передаются из проекта в проект, обрастают легендами и часто работают просто потому, что «всегда так делали».
2. Почему похожи на алхимиков?
Магия исполнения запросов (Execution Plan): Почему запрос сегодня выполняется 2 мс, а завтра — 2000 мс? Планы исполнения могут меняться по мистическим, на первый взгляд, причинам: из-за накопленной статистики, количества записей в таблице, состояния кэша и даже времени суток. Разбор такого плана часто похож на попытку алхимика расшифровать древний манускрипт.
Волшебные «посыпы» порошком (Index): Классическая ситуация: запрос тормозит. Специалист добавляет индекс — и все работает мгновенно. Почему этот конкретный индекс (иногда составной, частичный, с включением столбцов) сработал, а другой — нет? Часто ответ — «ну, я почувствовал, что так будет лучше» или «где-то читал про такой случай». Это чистейшая алхимия: добавил правильный ингредиент — получил золото.
Ритуалы для борьбы с автовакуумом (AutoVacuum): Настройка автовакуума — это один из самых больших поводов для мистики. Изменение параметров autovacuum_vacuum_scale_factor и autovacuum_analyze_scale_factor для отдельных таблиц — это ритуал, который часто проводят без глубокого понимания внутренних процессов, надеясь на лучшее.
3. Почему похожи на астрологов?
Предсказание производительности (Performance Forecasting): Попытки предсказать, как поведет себя система при увеличении нагрузки в 10 раз, или сколько IOPS потребуется для нового проекта, часто основаны не на строгих математических моделях, а на приметах, аналогиях и «чтении звезд» (метрик мониторинга за прошлые периоды).
Следование трендам и хайпу: «Все переходят на Kubernetes, давайте и мы загоним туда PostgreSQL!» — звучит как астрологический прогноз: «Меркурий в ретрограде, пора начинать новые дела». Часто это делается без глубокой оценки необходимости и применимости технологии к stateful-приложению, каким является СУБД.
Сложная терминология для посвященных: Разговоры о «WAL journal», «MVCC», «checkpoints», «transaction ids wraparound» звучат для непосвященных как заклинания. Специалист оперирует этими понятиями, чтобы объяснить поведение системы, которое со стороны кажется магическим.
Почему именно с PostgreSQL так происходит?
Невероятная гибкость и настраиваемость. PostgreSQL — это не черный ящик. Это конструктор с тысячами винтиков и гаек (параметров конфигурации). Такая свобода требует глубокого понимания, но на практике приводит к тому, что люди начинают крутить ручки наугад.
Огромное количество расширений (extensions). Каждое расширение — это новый пласт потенциальной магии и алхимии. Специалист становится «заклинателем», который приручает эти расширения, не всегда имея возможность заглянуть в их исходный код.
Сложность внутренних механизмов. Такие вещи, как MVCC (Multiversion Concurrency Control), — это очень сложно. Многие используют их, но далеко не все понимают до конца, как именно работает управление версиями строк, транзакциями и их номерами.
Где же ученые и исследователи в мире PostgreSQL?
Они есть, и их работа фундаментальна:
Команда разработчиков ядра PostgreSQL. Это именно ученые и инженеры, которые проводят исследования, докапываются до сути, пишут академические работы и реализуют новые функции (например, новые типы индексов, улучшения оптимизатора запросов).
Авторы научных статей и докладчики на крупных конференциях. Люди, которые анализируют производительность на уровне дисковых подсистем, памяти, процессоров и строят математические модели работы СУБД.
Эксперты по теме, пишущие книги. Такие авторы, как например, Ханс-Юрген Шёниг (Hans-Jürgen Schönig), разбирают сложные концепции и переводят их с «магического» языка на язык инженерии.
Вывод:
Подавляющее большинство практикующих админов и разработчиков БД — это действительно ремесленники-алхимики. Их главная задача — не открывать новые фундаментальные знания, а используя накопленный опыт, готовые рецепты и заклинания, обеспечить работу бизнес-критичных приложений здесь и сейчас.
Ученые же создают тот фундамент, те инструменты и ту науку, которую ремесленники потом применяют на практике, подчас не до конца понимая всю подноготную. Это естественное разделение труда в любой сложной и быстроразвивающейся области.
Каждый пункт - в точку ! Особенно про автовакуум это 100%.
Мне больше интересно быть ученым и исследователем. За 38 лет наремесленичался с избытком.
Cписок наиболее интересных и перспективных тем, логично вытекающих из уже проделанной работы.
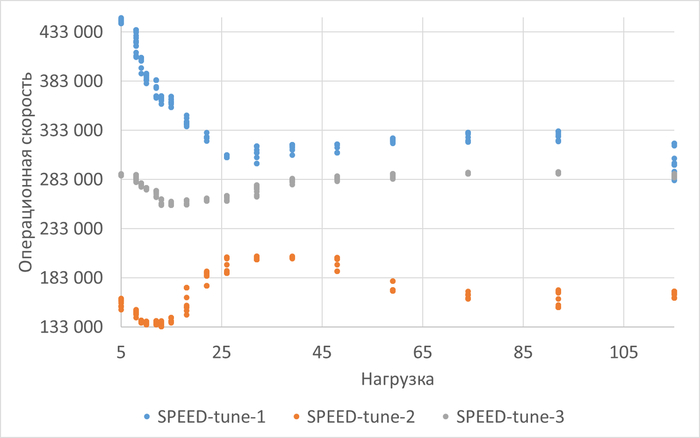
1. Многомерный анализ и построение единой модели производительности (Unified Performance Model)
Суть: Объединить все имеющиеся источники данных (wait events PostgreSQL, метрики запросов, iostat, vmstat) в единую многомерную модель.
Цель — не просто найти корреляции, а количественно оценить вклад каждого фактора в общую производительность (например, во время отклика транзакции).
Методы:
Множественная регрессия: Моделирование времени отклика базы данных как функции от десятков метрик: cpu_util, await, pg_wait_events_1, ..., pg_wait_events_N.
Методы снижения размерности:PCA (Principal Component Analysis) для выявления латентных (скрытых) факторов, которые на самом деле управляют производительностью. Например, можно обнаружить, что 90% всех колебаний производительности объясняются всего 2-3 скрытыми факторами (условно, "Фактор дисковой подсистемы", "Фактор конкурентного доступа").
Ценность:
Понимание того, какая подсистема (СУБД, диск, CPU, память) является узким местом (bottleneck) в конкретный момент времени и насколько сильно она его ограничивает.
2. Причинно-следственный анализ и обнаружение корневой причины (Causal Inference & Root Cause Analysis - RCA)
Суть: Сделать следующий шаг после корреляции.
Корреляция говорит "эти два события происходят одновременно", а причинность — "одно событие вызывает другое". Это ключ к настоящей автоматизированной диагностике.
Методы:
Причинность по Грэнджеру (Granger Causality) для временных рядов: Позволяет с определенной долей уверенности утверждать, что изменение метрики A (например, await из iostat) предшествует и предсказывает изменение метрики B (например, DataFileRead wait event в PostgreSQL).
Байесовские вероятностные сети (Bayesian Networks): Более мощный метод для построения графа причинно-следственных связей между всеми метриками. Покажет, что высокий %iowait в vmstat влечет за собой рост ожиданий ввода-вывода в СУБД, что приводит к росту времени выполнения запросов.
Ценность:
Автоматическое ответ на вопрос "что стало первоначальной причиной проблемы?" при деградации производительности. Например, система могла бы выдавать alert: "Обнаружена проблема. Корневая причина: перегрузка дискового массива (метрика: await > 50ms), что привело к росту событий ожидания I/O в СУБД на 300%".
3. Прогнозное моделирование и предсказание сбоев (Predictive Analytics)
Суть: Использовать исторические данные, чтобы предсказать будущее.
Методы:
Прогнозирование временных рядов: ARIMA, Exponential Smoothing (ETS) или ML-модели (например, Prophet) для предсказания:
Времени исчерпания ресурсов: Когда закончится место на диске? Когда оперативная память будет полностью использована?
Наступления пороговых значений: Когда нагрузка на диск достигнет критического уровня, при котором время отклика СУБД превысит допустимый порог?
Классификация и прогноз инцидентов: На размеченных исторических данных (когда были сбои) можно обучить модель классификации (например, Random Forest или Gradient Boosting), которая по текущим метрикам будет предсказывать вероятность наступления инцидента в ближайшие N минут.
Ценность:
Превентивное реагирование. Возможность устранить проблему до того, как она окажет impact на пользователей.
4. Проактивное тестирование и анализ устойчивости (Chaos Engineering & Resilience Analysis)
Суть: Ваша система сбора метрик — идеальный инструмент для оценки того, как СУБД и вся система в целом ведет себя под нагрузкой и при сбоях.
Методы:
Планирование экспериментов (Design of Experiments - DoE): Целенаправленно создавать нагрузку (например, с помощью pgbench) и вносить возмущения (например, искусственно создавать I/O latency с помощью tc (traffic control) или нагружать CPU).
Анализ отклика системы: Смотреть, как ваши метрики (vmstat, iostat, wait events) реагируют на эти воздействия. Строить модели "нагрузка-отклик".
Ценность:
Понимание пределов устойчивости вашей системы. Ответ на вопросы: "Как поведет себя СУБД, если диски начнут отвечать в 10 раз медленнее?", "Какую пиковую нагрузку выдержит конфигурация до того как oom_killer убьет Postgres?".
5. Персонализированные рекомендации по настройке (Prescriptive Analytics)
Суть: Это вершина аналитики — не только диагностировать и предсказывать, но и рекомендовать конкретные действия.
Методы:
Системы рекомендаций: На накопленных данных можно обучить модель, которая будет предлагать изменить тот или иной параметр PostgreSQL (shared_buffers, work_mem, maintenance_work_mem) или ядра ОС (например, параметры виртуальной памяти) на основе выявленных паттернов.
A/B тестирование рекомендаций: Ваша же платформа может использоваться для проверки эффективности этих рекомендаций путем сравнения метрик "до" и "после".
Ценность:
Автоматизация рутинной работы по тонкой настройке (database tuning).
6. Продвинутая визуализация и интерактивный анализ
Суть: Предоставить инструмент для человеческого понимания всей этой сложной многомерной данных.
Методы:
Heatmaps корреляций и причинностей: Визуализация матрицы корреляций и графа причинно-следственных связей.
Cohort Analysis: Группировка инцидентов по типам (I/O bound, CPU bound, Lock contention) и анализ их частоты и тяжести во времени.
Интерактивные дашборды: Где можно кликнуть на пик на графике времени отклика и мгновенно увидеть, какие именно метрики на уровне ОС и СУБД вели себя аномально в этот момент.
Итог и рекомендация по приоритету:
Учитывая прогресс в работах, наиболее логичной и потенциально прорывной темой выглядит №2 — Причинно-следственный анализ.
Построена корреляция, теперь пришло время ответить на вопрос "почему?". Это именно тот рубеж, который отделяет просто мониторинг от экспертной системы диагностики. Реализация даже простых методов (как Грэнджера) на столь богатом наборе данных даст огромную практическую ценность.
Далее, естественным образом, можно перейти к прогнозной аналитике (№3), используя выявленные причинно-следственные связи для более точных предсказаний.