


Взлом генетического кода
Всем привет! Продолжаю историю о расшифровке генетического кода.
Краткое содержание предыдущего поста: учёные Уотсон и Крик, закинувшись ЛСД, открывают структуру ДНК и понимают, что в ней заключена генетическая информация. И записана она 4-мя нуклеотидами - А, Г, Т(У), Ц, которые кодируют 20 молекул-аминокислот, из которых в свою очередь синтезируются белки в нашем организме (см. гифку).
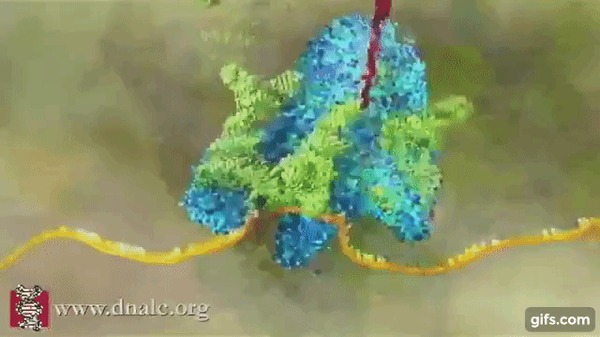
Получилась чуть ли не криптографическая задача - надо было разгадать, каким образом 4 буквы-нуклеотида шифруют 20 аминокислот.
Сразу стало понятно, что в условном "байте" этого кода должно быть минимум три буквы, типа АГЦ, потому что две буквы могут кодировать максимум 16 вариантов, а три - целых 64. А надо было 20 - явная несостыковочка.
Было предложено два элегантных и красивых решения, которые математически объясняли эти особенности кода, однако реальность прошлась по красоте катком экспериментальных данных. И результат расшифровки учёных, прямо скажем, разочаровал (ссылка на это кино http://pikabu.ru/story/kak_uchyonyie_geneticheskiy_kod_vzlam...).
Указанные события произошли в 1950-1960 годах. А дальше пришёл технический прогресс с компьютерами и стало намного интереснее.
1. Когда байтов слишком много
Генетический код, когда его расшифровали, разочаровал учёных по нескольким причинам.

Он действительно не был так красив как предсказывали гипотезы:
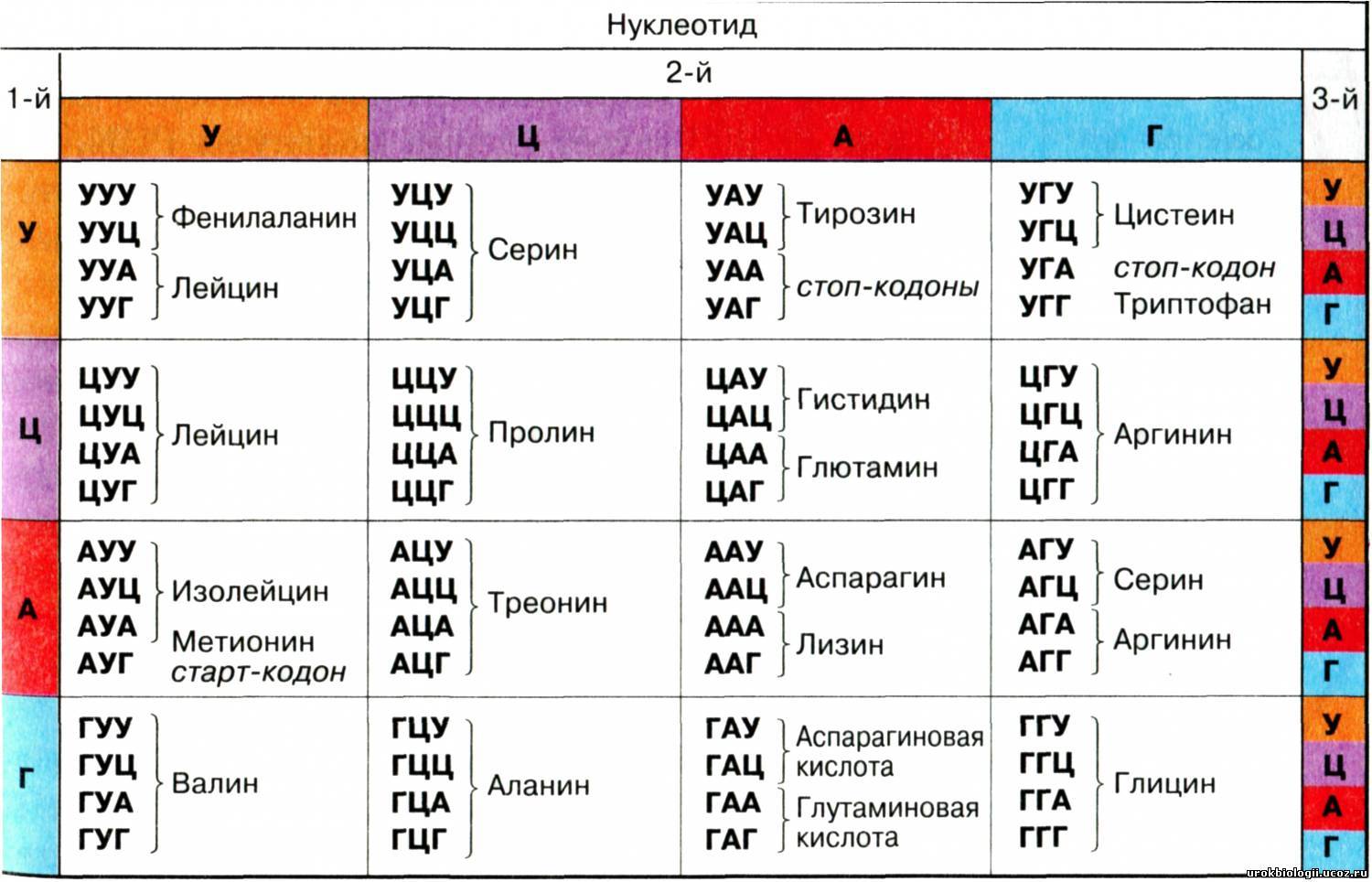
(Для облегчения понимания (и для тех кто не видел предыдущий пост): в генетическом коде используется четверичный код, а не двоичный, как в комппьютерах - А Г У Ц вместо 0 и 1. Байт, он же кодон, в генетике выглядит напимер так - ГУУ, что означает аминокислоту валин, а в компьютерной кодировке - 01000001, что означает букву А. Однако валин при этом кодируется ещё и кодонами ГУА, ГУЦ и ГУГ (см. левый нижний угол) - это и есть вырожденность)
Действительно, трудно говорить о красоте, когда одна и та же аминокислота кодируется сразу несколькими кодонами (например, левый нижний угол таблицы: валин кодируется 4-мя сочетаниями сразу - ГУУ, ГУЦ, ГУА, ГУГ). Примените этот принцип к стандартной кодировке Windows, где каждому символу соответствует один и только один байт, и получите полную неразбериху и избыточность, которая только усложнит написание и прочтение кода.
Ниже пример стандартной невырожденной кодировки, в которой байт соответствует 1 символу:
01000001 - A
11000001 - Б
01000011 - C
01000100 - D
01000101 - E
01000110 - F
01000111 - G
01001000 - H
и т.д.
В общем, генетический код был "некрасивым" и вырожденным. И как ни пытались учёные найти какую-нибудь структурную логику в генетическом коде, ничего не получилось: между аминокислотами и кодонами на первый взгляд не было ни особой химической, ни особой физической связи.
2. Почему код только один?
Учёный, стоящий у истоков расшифровки, со звучной фамилией Крик, объявил этот удручающий код "застывшей случайностью". Проще говоря, код возник случайным образом и в таком виде дошел до наших дней.
И это было весьма и весьма логичное предположение. Если точечная мутация в ДНК организма может изменить ту или иную аминокислоту, расположенную в определенном месте определенного белка, то любое изменение хоть в одной букве самого кода привело бы к сбою всей кодировки.
Для понимания пример точечной мутации (см. картинку ниже): меняем один "бит" (Г на Ц) -> меняется "байт" (ГАУ на ЦАУ) -> при синтезе белка участвует другая аминокислота (вместо Аспарагина - Гистидин) -> как следствие изменение структуры и свойств белка (на картинке оно критичное, однако это не всегда так).
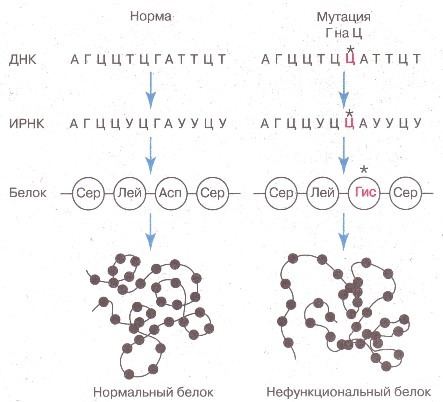
Ясное дело, остальные белки в организме при точечной мутации не изменяются. А теперь представьте что будет если поменять хотя бы одну букву в самом коде - вся система просто рухнет. И красивая цитата от Крика: "после того, как код был выбит на скрижалях, любые покушения на него карались смертью".
Но предполагаемая Криком "случайная" природа кода ставила одну проблему. Почему такая случайность была всего одна? Почему кодов не возникло несколько?
Самый очевидный ответ предполагал, что все живое на земле происходит от единственного общего предка, у которого генетический код уже был жестко закреплен. Крик даже предположил, то жизнь могла быть занесена на землю в сформированном виде, может даже разумными существами.

(момент из не самого удачного и продуманного в научном плане фильма "Прометей", когда пришелец прилетает на древнюю Землю, закидывается чем-то и рассыпается на органическую субстанцЫю, дающей начало жизни)
Однако время шло, техника и методы научного анализа развивались, и уже в начале 80-х годов, стало ясно, что генетический код нельзя считать застывшим или полностью случайным. В нём нашлись скрытые закономерности, своего рода код внутри кодонов, дающий нам ключи к разгадке тайны четырёхмиллиарднолетней (советую прочесть это слово пару раз) давности.
Собственно, теперь мы знаем, что генетический код представляет собой не тот жалкий шифр, который так разочаровал в свое время криптографов.
3. Код внутри кодонов
С 60-х годов в генетическом коде выявили ряд закономерностей, однако большинство отбрасывались как обыкновенный статистический шум. Местами даже казалось, будто совокупность закономерностей не несет особого смысла. Однако вовремя нашёлся калифорнийский биохимик Брайан Дэвис, который имел другое мнение на этот счёт.
Он первым заметил, что буквы кодонов несут скрытый физико-химический смысл. Например, если взять все кодоны, начинающиеся с Т, то окажется, то все эти кодоны кодируют аминокислоты, образующиеся из одного и того же вещества-предшественника (так называют простые молекулы, которые стоят в основании синтеза более сложных органических веществ) - пирувата (он же пировиноградная кислота).
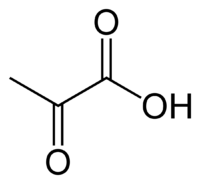
Пируват может образовываться в природе, например в гидротермальных источниках, из углекислого газа и водорода. То же относится и к другим первым буквам - каждая из них ведёт к веществам предшественникам, способным образовываться без участия живых клеток.
А как обстоят дела со второй буквой? Здесь тоже есть связь - на этот раз со степенью растворимости (или нерастворимости) аминокислоты в воде, то есть гидрофильности (или гидрофобности). Все аминокислоты можно распределить по своего рода спектру, начиная от "очень гидрофобных" и заканчивая "очень гидрофильными". Именно этот спектр имеет связь со второй буквой триплетного кода.
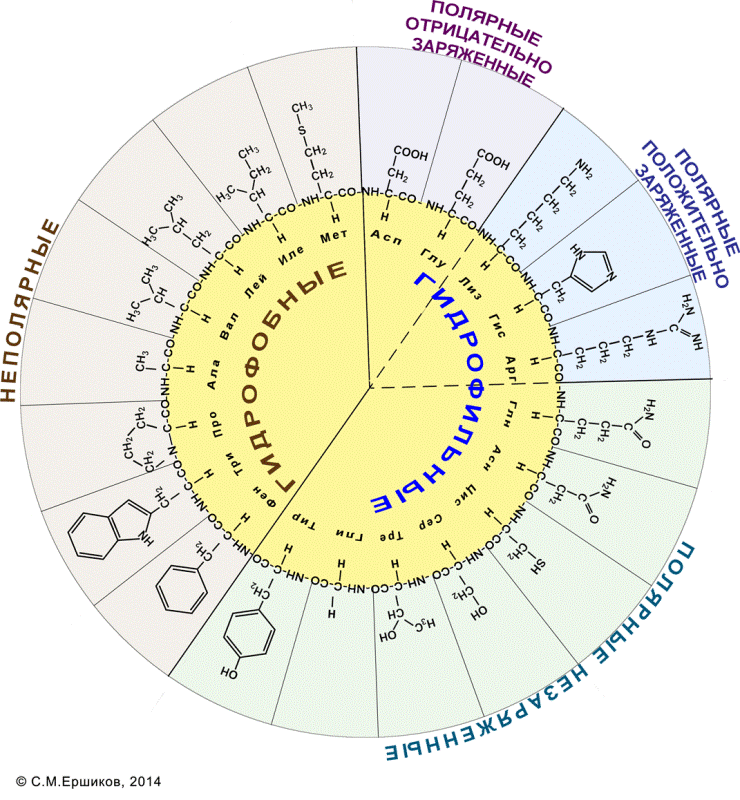
Пяти из шести самых гидрофобных аминокислот соответствуют кодоны с буквой Т в середине, а всем самым гидрофильным — кодоны с буквой А в середине. Промежуточным аминокислотам спектра соответствуют кодоны с буквой Г или Ц в середине. Таким образом, чем бы это ни объяснялось, в целом наблюдается сильная и вполне определенная связь между первыми двумя буквами каждого кодона и той аминокислотой, которую этот кодон кодирует.
Последняя буква во всех кодонах самая бесполезная. Именно она приводит к вырожденности кода: восьми аминокислотам свойственна (прекрасный термин!) четырехкратная вырожденность. В данном случае четырехкратная вырожденность означает не что-то плохое, а только тот факт, когда третья буква кода не несет никакой информации.
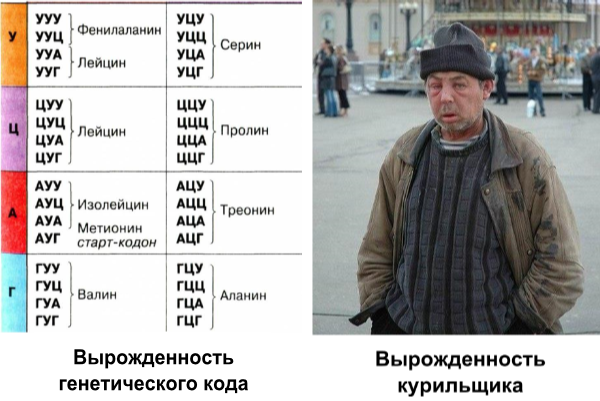
Независимо от того, какой нуклеотид стоит на третьем месте, во всех четырех случаях триплет кодирует одну и ту же аминокислоту. Например, в триплете ГГГ, кодирующем глицин, можно заменить последнюю Г на Т, А или Ц — и все три новых триплета будут по-прежнему кодировать глицин.
А сейчас будет очень сильная мысль. Если исключить из их списка пять самых сложных аминокислот(оставив, таким образом, пятнадцать, плюс стоп-кодон), то закономерности, касающиеся первых двух букв, окажутся выражены еще ярче. Поэтому уместно предположить, что код первоначально был дублетным (типа АА или АГ) и лишь потом расширился до триплетного в результате "присвоения" кодонов.
Древнейшие аминокислоты, вероятно, получили преимущество в борьбе за "присвоение" триплетных кодонов. Например, те 15 аминокислот, которые скорее всего кодировались первоначальным дублетным кодом, загребли себе 53 из 64 возможных триплетов (в среднем 3,5 кодона на аминокислоту), в то время как оставшиеся пять "позднейших" аминокислот разделили между собой лишь восемь кодонов (в среднем 1,6 на аминокислоту).

А теперь рассмотрим следующую возможность: код первоначально был дублетным, а не триплетным, и кодировал пятнадцать аминокислот (плюс один стоп-кодон). Этот первоначальный код, судя по всему, был почти полностью продиктован физическими и химическими факторами. Первая буква указывала на вещество-предшественник, а вторая - на способность растворяться в воде.
С третьей буквой дело обстояло иначе. Здесь было куда больше возможных вариантов, и многое могло произойти по воле случая, после чего отбор получал возможность "оптимизировать" полученный код за счёт всеми любимого нами классического эволюционного процесса.
4. Самый крутой генетический код
В конце концов, исследователи решили выяснить, какой код лучше всего противостоял бы точечным мутациям. Оказалось, что настоящий генетический код поразительно устойчив к таким изменениям: точечные мутации часто вообще не влияют на последовательность аминокислот, а если все-таки влияют, то аминокислота обычно заменяется на другую, близкую по свойствам к исходной.
Пример:
Заменяем ЦУУ на ЦУЦ - получается та же аминокислота лейцин.
Заменяем ЦАЦ на ЦАА - гистидин меняется на похожий по структуре глутамин.
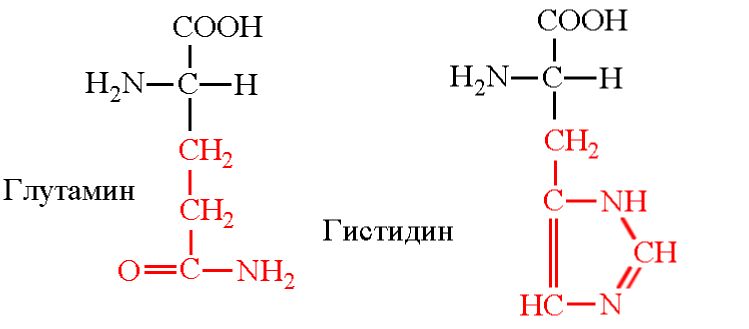
Похожесть в конечном итоге означает, что кодируемый белок с большой вероятностью не развалится и не утратит исполняемые им функции (пример - гемоглобин не "разучится" переносить кислород к тканям). Скорее всего он как-то изменит пространственную конфигурацию, станет более или менее устойчивым, в общем отклонится от первоначального варианта.
Просто представьте, как во всей этой круговерти (на картинке типичный белок) меняется один изгиб:
Если ближе к середине это будет довольно опасно, а на окраине может и нет. В любом случае, переставлять карты у уже сложенного карточного домика лучше где-нибудь на верхушке.
Но учёные, в поисках конкретного обоснования, пошли ещё дальше. Они сгенерили на компьютерах более миллиона случайных вариантов триплетного кода (с теми же исходными данными, что у генетического кода - 64 триплета кодируют 20 аминокислот) и сравнили их с существующим кодом - на устойчивость и способность противостоять разрушающему действию мутаций.
И вы наверное уже догадались, что наш генетический код во всех отношениях лучше миллионов случайно сгенерированных кодов.

Впрочем, не самый лучший.
И да, он действительно нейтрализует негативные последствия тех изменений, которые все-таки случаются в ДНК. И тем самым ускоряет эволюцию - ведь ясно, что у мутаций намного больше шансов оказаться полезными, если они не ведут к катастрофическим последствиям.
Тут кто-то скажет - ага, значит код есть творение разумного существа.

На самом деле всё может быть, ведь даже земные учёные научились создавать живые клетки, использующие дополненный и улучшенный код - (см. новость). Однако наш код оказался всё же хуже некоторых вариантов - именно в силу того, что две первые быквы нашего кода закреплены в соответствии с веществом-предшественником и растворимостью. Это ограничение, возникшее исторически, а созданная "с нуля" кодировка таких ограничений иметь не обязана.
Итак, в целом "код внутри кодонов" говорит нам о процессе, первоначально связанном с биосинтезом и водорастворимостью аминокислот, а затем проходившем фазы расширения и оптимизации.
Тут возникает закономерный вопрос: что это был за процесс, на который начал действовать естественный отбор? Что было в самом начале, до возникновения кода?
.
.
.
.
.
.
Ииииииии на этот вопрос можно ответить, только написав пару тройку длиннопостов о происхождении жизни. Однако не знаю стоит ли - материала там много и он реально сложный. Так что ничего не обещаю, но цель себе поставлю
PS Первоисточник поста - замечательная книга Ника Лейна "Лестница Жизни" (https://www.livelib.ru/book/1000723390-lestnitsa-zhizni-desy...) - советую всем у кого есть базовые знания в области эволюции и генетики.

Наука | Научпоп
8.6K пост81.6K подписчиков
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.