


Парсинг данных с сайтов в гугл таблички (GS1)
Шалом, комрады.
Т.к. это первый пост про гугл таблички, то кроме разбора конкретной функции расскажу в целом чем же они так хороши.
Гугл таблички (далее ГТ) просчитываются на бекенде, т.е. на серверах гугла и продолжают работать даже если они закрыты физически у вас в браузере. Это значит, что сложные вычисления, справочники, доки со скриптами и т.д. продолжают работать в фоне. Это позволяет из ГТ делать настоящую информационную экосистему в компании. Если добавить сюда бесчисленные интеграции - то ГТ могут собрать всё инфо в вашем бизнесе и в автоматическом режиме с ней работать.
Что касается персонального использования - то тут плюсом будут в основном интеграции и скрипты, которые оч просто использовать и обращаться к ним с телефона или вообще из телеграмма.
С прелюдией всё, переходим к мясу.
У ГТ есть замечательнейшая функция =importxml(), которая позволяет забирать данные с сайтов, т.е. парсить эти самые сайты. Функционал её ограничен и полноценного парсера в ГТ не сделать по двум причинам:
1. Оно не может парсить данные с сайтов, где необходима авторизация.
2. Оно имеет техническое ограничение на кол-во попыток парсинга, т.к. вход на сайт парсер осуществляет с одного и того же IP. Если на сайте установлено ограничение на кол-во заходов в минуту (а его специально ставят против парсеров), то работать он будет, но будет это крайне медленно.
Итак, к самой функции.
Покажу на двух примерах - КиноПоиск и Авито.
Я очень люблю ужастики, поэтому работать будем с ними :3
Заходим на кинопоиск и исследуем конкретный элемент:

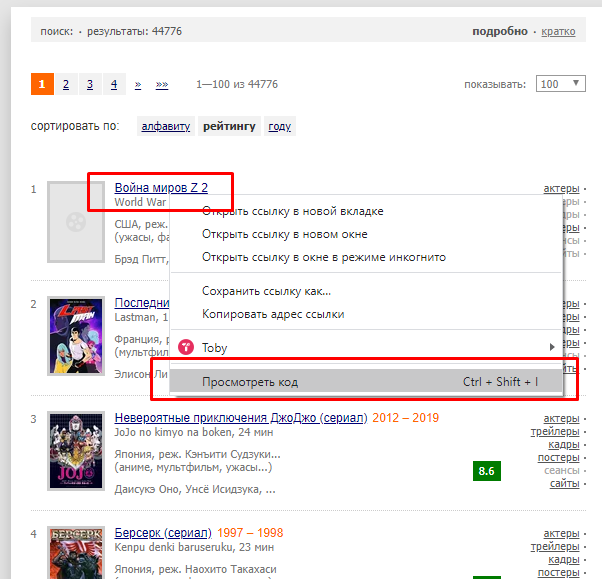

На сайтах похожие элементы чаще всего имеют одинаковый класс внутри тега div, span или a. Технически грузить не буду, достаточно навести мышкой на кусок когда и нужный элемент будет подсвечен. Нам нужен тег и его класс. Т.е. div и 'info'.
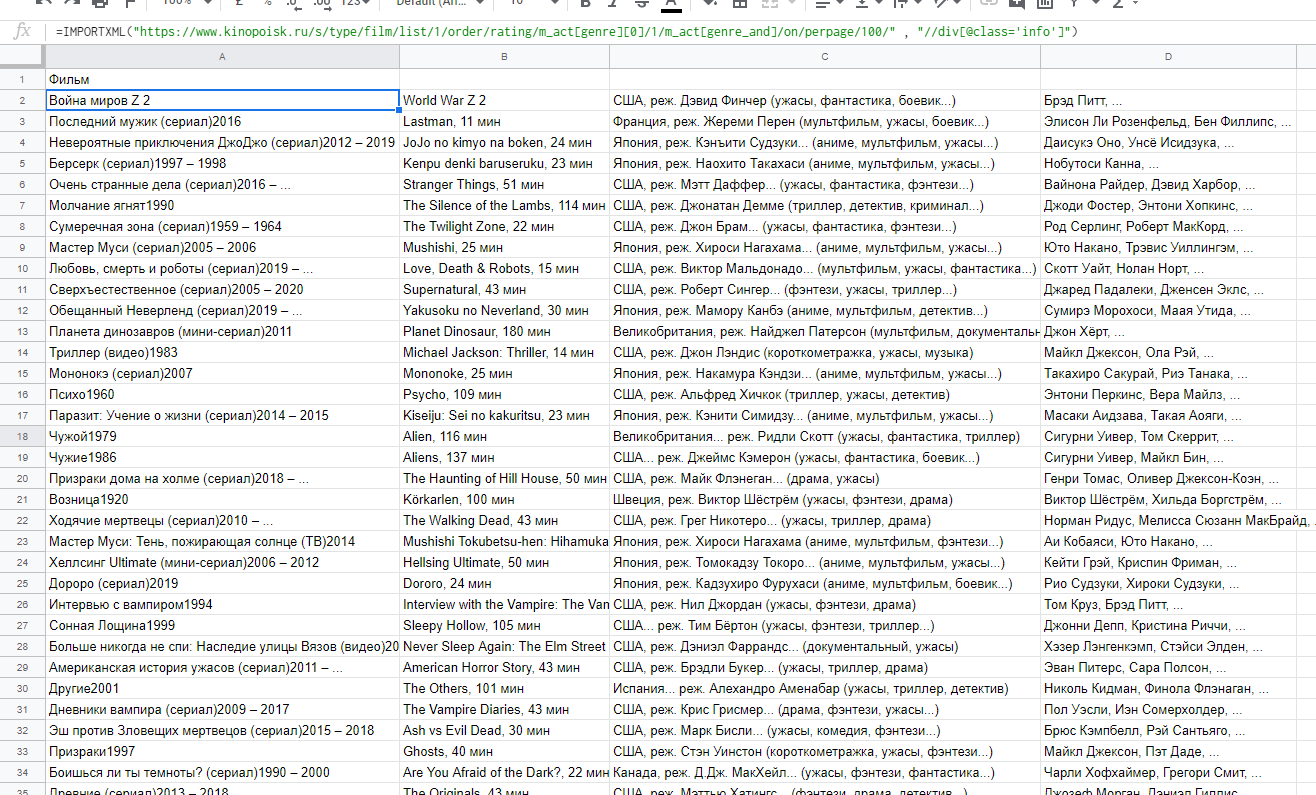
Дальше заходим в ГТ и пишем следующее:
=importxml("https://www.kinopoisk.ru/s/type/film/list/1/order/rating/m_a..." ; "//div[@class='info']")
Первый аргумент функции - ссылка на сайт. Второй - запрос на языке Xpath, который ведет к заветному div с классом 'info'. На выходе получаем:
Аналогично для авито:
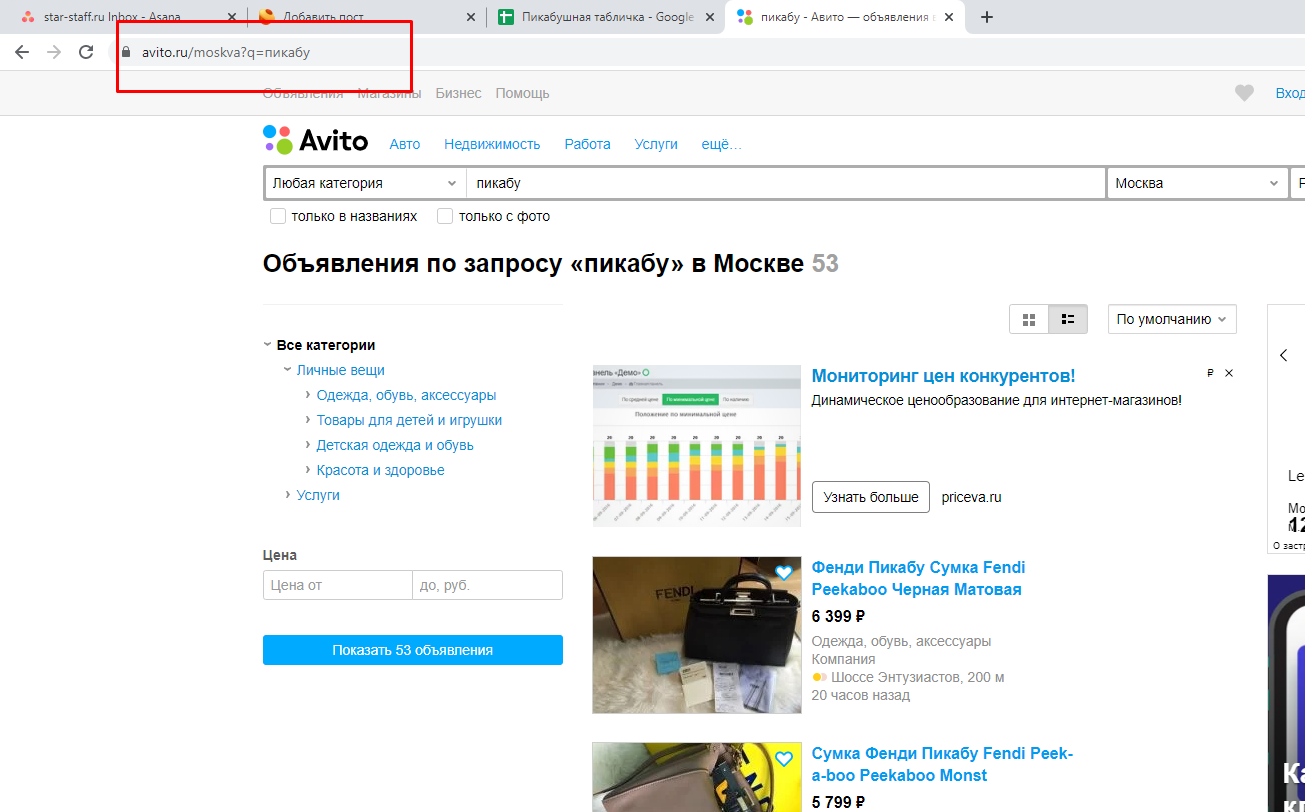
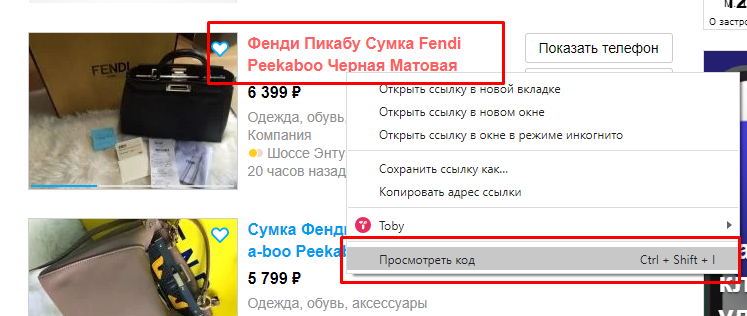
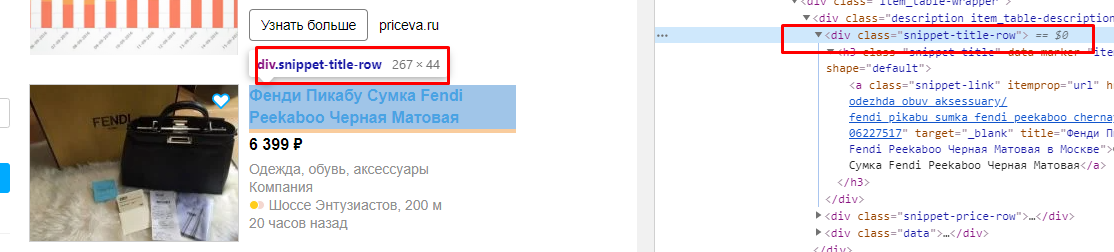
Формула: =importxml("https://www.avito.ru/moskva?q=пикабу","//div[@class='snippet-title-row']")
Итог:
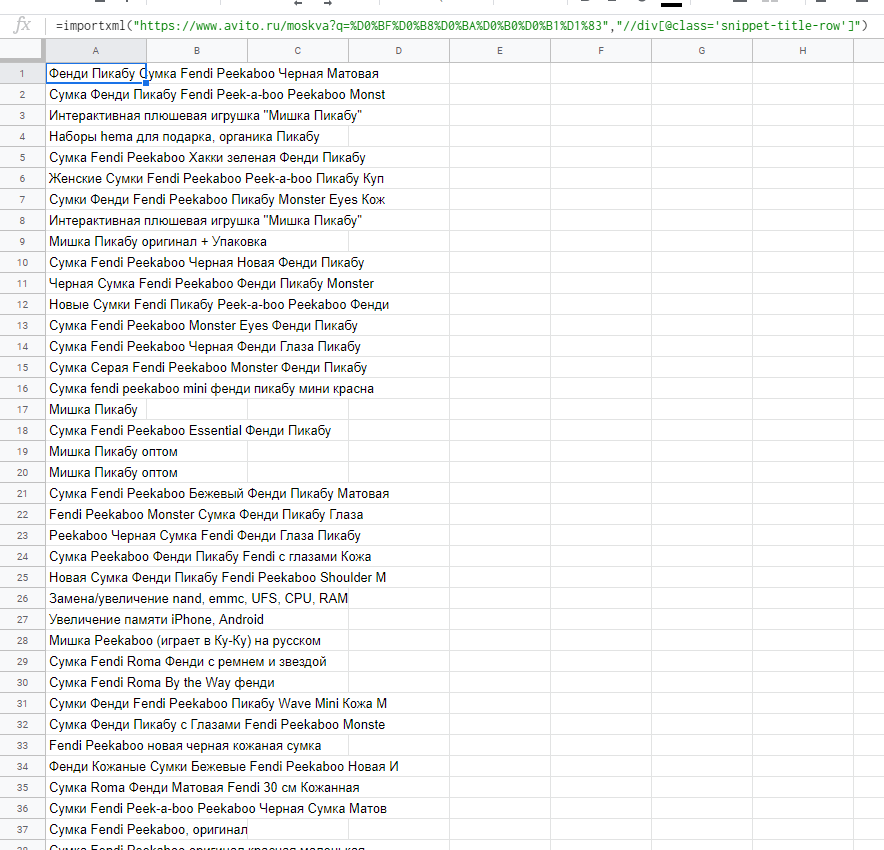
Ссылка на док: https://docs.google.com/spreadsheets/d/1WvGYnynJkX2srI1G1DD-...
Вот и все на сегодня) Пост первый, так что жду критики и советов, чтобы следующий контент материал был более читабельным и полезным)
MS, Libreoffice & Google docs
777 постов15K подписчиков
Правила сообщества
1. Не нарушать правила Пикабу
2. Публиковать посты соответствующие тематике сообщества
3. Проявлять уважение к пользователям
4. Не допускается публикация постов с вопросами, ответы на которые легко найти с помощью любого поискового сайта.
По интересующим вопросам можно обратиться к автору поста схожей тематики, либо к пользователям в комментариях
Важно - сообщество призвано помочь, а не постебаться над постами авторов! Помните, не все обладают 100 процентными знаниями и навыками работы с Office. Хотя вы и можете написать, что вы знали об описываемом приёме раньше, пост неинтересный и т.п. и т.д., просьба воздержаться от подобных комментариев, вместо этого предложите способ лучше, либо дополните его своей полезной информацией и вам будут благодарны пользователи.
Утверждения вроде "пост - отстой", это оскорбление автора и будет наказываться баном.