


Невидимый чемпион: как EXISTS побеждает IN в бою за ресурсы PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).
Паттерн оптимизации - который смог. Доказанная оптимизация: EXISTS быстрее IN в PostgreSQL.
Предисловие
В сценариях с параллельными запросами и острой конкуренцией за ресурсы паттерн EXISTS показал себя как однозначно более эффективное решение для PostgreSQL.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Эксперименты с Демобазой 2.0
Начало экспериментов "IN vs EXISTS"
Тестовый запрос-1 : IN
SELECT DISTINCT a.country
FROM airports_data a
JOIN routes r ON (r.arrival_airport = a.airport_code)
WHERE duration IN
(
'09:45:00' , '11:50:00' , '02:40:00' , '05:50:00' , '15:25:00' , '04:30:00' , '11:00:00' , '07:15:00' , '12:40:00' , '03:40:00' , '05:15:00' , '08:35:00' , '10:35:00' , '07:30:00' , '09:35:00' , '04:15:00' , '11:45:00' , '04:05:00' , '01:10:00' , '19:50:00' , '07:55:00' , '01:35:00' , '16:05:00' , '08:15:00' , '04:00:00' , '08:45:00' , '12:25:00' , '16:40:00' , '07:25:00' , '01:50:00' , '14:35:00' , '12:45:00' , '01:20:00' , '02:55:00' , '20:20:00' , '10:45:00' , '02:45:00' , '12:55:00' , '08:25:00' , '00:45:00' , '02:00:00' , '01:15:00' , '08:00:00' , '04:10:00' , '11:35:00' , '16:45:00' , '17:15:00' , '14:40:00' , '15:35:00' , '15:50:00' , '13:30:00' , '04:25:00' , '01:25:00' , '14:10:00' , '15:15:00' , '08:55:00' , '07:00:00' , '05:05:00' , '06:45:00' , '14:20:00' , '09:50:00' , '08:10:00' , '11:30:00' , '13:45:00' , '04:35:00' , '01:30:00' , '15:10:00' , '05:25:00' , '05:20:00' , '16:30:00' , '14:45:00' , '00:40:00' , '13:15:00' , '12:50:00' , '09:05:00' , '17:30:00' , '13:05:00' , '13:10:00' , '10:50:00' , '07:10:00' , '05:00:00' , '10:40:00' , '03:25:00' , '09:00:00' , '13:00:00' , '10:20:00' , '16:20:00' , '08:05:00' , '07:40:00' , '14:30:00' , '16:10:00' , '03:50:00' , '08:30:00' , '05:40:00' , '06:20:00' , '05:30:00' , '11:05:00' , '11:55:00' , '04:20:00' , '06:40:00' );
План выполнения тестового запроса-1 : IN
HashAggregate (cost=282.56..284.86 rows=230 width=54) (actual time=5.604..5.609 rows=17 loops=1)
Group Key: a.country
Batches: 1 Memory Usage: 40kB
-> Nested Loop (cost=0.54..276.22 rows=2534 width=54) (actual time=0.104..3.559 rows=2534 loops=1)
-> Seq Scan on routes r (cost=0.25..185.13 rows=2534 width=4) (actual time=0.049..1.650 rows=2534 loops=1)
Filter: (duration = ANY ('{09:45:00,11:50:00,02:40:00,05:50:00,15:25:00,04:30:00,11:00:00,07:15:00,12:40:00,03:40:00,05:15:00,08:35:00,10:35:00,07:30:00,09:35:00,04:15:00,11:45:00,04:05:00,01:10:00,19:50:00,07:55:00,01:35:
00,16:05:00,08:15:00,04:00:00,08:45:00,12:25:00,16:40:00,07:25:00,01:50:00,14:35:00,12:45:00,01:20:00,02:55:00,20:20:00,10:45:00,02:45:00,12:55:00,08:25:00,00:45:00,02:00:00,01:15:00,08:00:00,04:10:00,11:35:00,16:45:00,17:15:00,14:40:00,
15:35:00,15:50:00,13:30:00,04:25:00,01:25:00,14:10:00,15:15:00,08:55:00,07:00:00,05:05:00,06:45:00,14:20:00,09:50:00,08:10:00,11:30:00,13:45:00,04:35:00,01:30:00,15:10:00,05:25:00,05:20:00,16:30:00,14:45:00,00:40:00,13:15:00,12:50:00,09:
05:00,17:30:00,13:05:00,13:10:00,10:50:00,07:10:00,05:00:00,10:40:00,03:25:00,09:00:00,13:00:00,10:20:00,16:20:00,08:05:00,07:40:00,14:30:00,16:10:00,03:50:00,08:30:00,05:40:00,06:20:00,05:30:00,11:05:00,11:55:00,04:20:00,06:40:00}'::int
erval[]))
Rows Removed by Filter: 3258
-> Memoize (cost=0.29..0.39 rows=1 width=58) (actual time=0.000..0.000 rows=1 loops=2534)
Cache Key: r.arrival_airport
Cache Mode: logical
Hits: 2461 Misses: 73 Evictions: 0 Overflows: 0 Memory Usage: 11kB
-> Index Scan using airports_data_pkey on airports_data a (cost=0.28..0.38 rows=1 width=58) (actual time=0.007..0.007 rows=1 loops=73)
Index Cond: (airport_code = r.arrival_airport)
Тестовый запрос-2 : EXISTS
SELECT DISTINCT a.country
FROM airports_data a
WHERE EXISTS (
SELECT 1
FROM routes r
WHERE r.arrival_airport = a.airport_code
AND r.duration IN (
'09:45:00', '11:50:00', '02:40:00', '05:50:00', '15:25:00', '04:30:00', '11:00:00', '07:15:00',
'12:40:00', '03:40:00', '05:15:00', '08:35:00', '10:35:00', '07:30:00', '09:35:00', '04:15:00',
'11:45:00', '04:05:00', '01:10:00', '19:50:00', '07:55:00', '01:35:00', '16:05:00', '08:15:00',
'04:00:00', '08:45:00', '12:25:00', '16:40:00', '07:25:00', '01:50:00', '14:35:00', '12:45:00',
'01:20:00', '02:55:00', '20:20:00', '10:45:00', '02:45:00', '12:55:00', '08:25:00', '00:45:00',
'02:00:00', '01:15:00', '08:00:00', '04:10:00', '11:35:00', '16:45:00', '17:15:00', '14:40:00',
'15:35:00', '15:50:00', '13:30:00', '04:25:00', '01:25:00', '14:10:00', '15:15:00', '08:55:00',
'07:00:00', '05:05:00', '06:45:00', '14:20:00', '09:50:00', '08:10:00', '11:30:00', '13:45:00',
'04:35:00', '01:30:00', '15:10:00', '05:25:00', '05:20:00', '16:30:00', '14:45:00', '00:40:00',
'13:15:00', '12:50:00', '09:05:00', '17:30:00', '13:05:00', '13:10:00', '10:50:00', '07:10:00',
'05:00:00', '10:40:00', '03:25:00', '09:00:00', '13:00:00', '10:20:00', '16:20:00', '08:05:00',
'07:40:00', '14:30:00', '16:10:00', '03:50:00', '08:30:00', '05:40:00', '06:20:00', '05:30:00',
'11:05:00', '11:55:00', '04:20:00', '06:40:00'
));
План выполнения тестового запроса-2 : EXISTS
Unique (cost=299.91..300.27 rows=73 width=54) (actual time=3.071..3.114 rows=17 loops=1)
-> Sort (cost=299.91..300.09 rows=73 width=54) (actual time=3.069..3.076 rows=73 loops=1)
Sort Key: a.country
Sort Method: quicksort Memory: 25kB
-> Nested Loop (cost=191.75..297.65 rows=73 width=54) (actual time=2.457..2.942 rows=73 loops=1)
-> HashAggregate (cost=191.47..192.19 rows=73 width=4) (actual time=2.408..2.421 rows=73 loops=1)
Group Key: r.arrival_airport
Batches: 1 Memory Usage: 24kB
-> Seq Scan on routes r (cost=0.25..185.13 rows=2534 width=4) (actual time=0.048..1.834 rows=2534 loops=1)
Filter: (duration = ANY ('{09:45:00,11:50:00,02:40:00,05:50:00,15:25:00,04:30:00,11:00:00,07:15:00,12:40:00,03:40:00,05:15:00,08:35:00,10:35:00,07:30:00,09:35:00,04:15:00,11:45:00,04:05:00,01:10:00,19:50:00,07:
55:00,01:35:00,16:05:00,08:15:00,04:00:00,08:45:00,12:25:00,16:40:00,07:25:00,01:50:00,14:35:00,12:45:00,01:20:00,02:55:00,20:20:00,10:45:00,02:45:00,12:55:00,08:25:00,00:45:00,02:00:00,01:15:00,08:00:00,04:10:00,11:35:00,16:45:00,17:15:
00,14:40:00,15:35:00,15:50:00,13:30:00,04:25:00,01:25:00,14:10:00,15:15:00,08:55:00,07:00:00,05:05:00,06:45:00,14:20:00,09:50:00,08:10:00,11:30:00,13:45:00,04:35:00,01:30:00,15:10:00,05:25:00,05:20:00,16:30:00,14:45:00,00:40:00,13:15:00,
12:50:00,09:05:00,17:30:00,13:05:00,13:10:00,10:50:00,07:10:00,05:00:00,10:40:00,03:25:00,09:00:00,13:00:00,10:20:00,16:20:00,08:05:00,07:40:00,14:30:00,16:10:00,03:50:00,08:30:00,05:40:00,06:20:00,05:30:00,11:05:00,11:55:00,04:20:00,06:
40:00}'::interval[]))
Rows Removed by Filter: 3258
-> Index Scan using airports_data_pkey on airports_data a (cost=0.28..1.46 rows=1 width=58) (actual time=0.006..0.006 rows=1 loops=73)
Index Cond: (airport_code = r.arrival_airport)
Результаты сравнительного нагрузочного тестирования
Операционная скорость
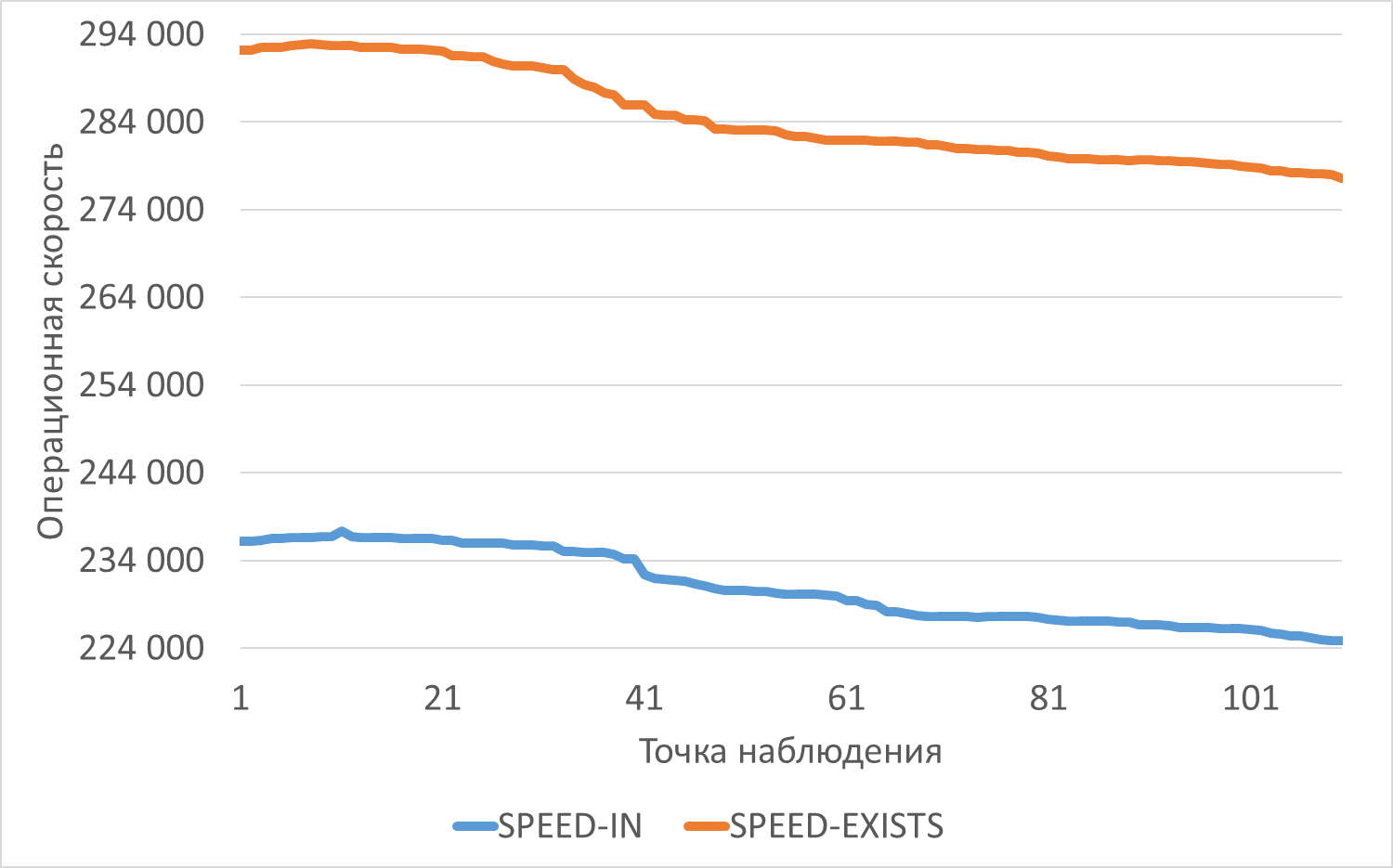
График изменения операционной скорости в ходе нагрузочного тестирования
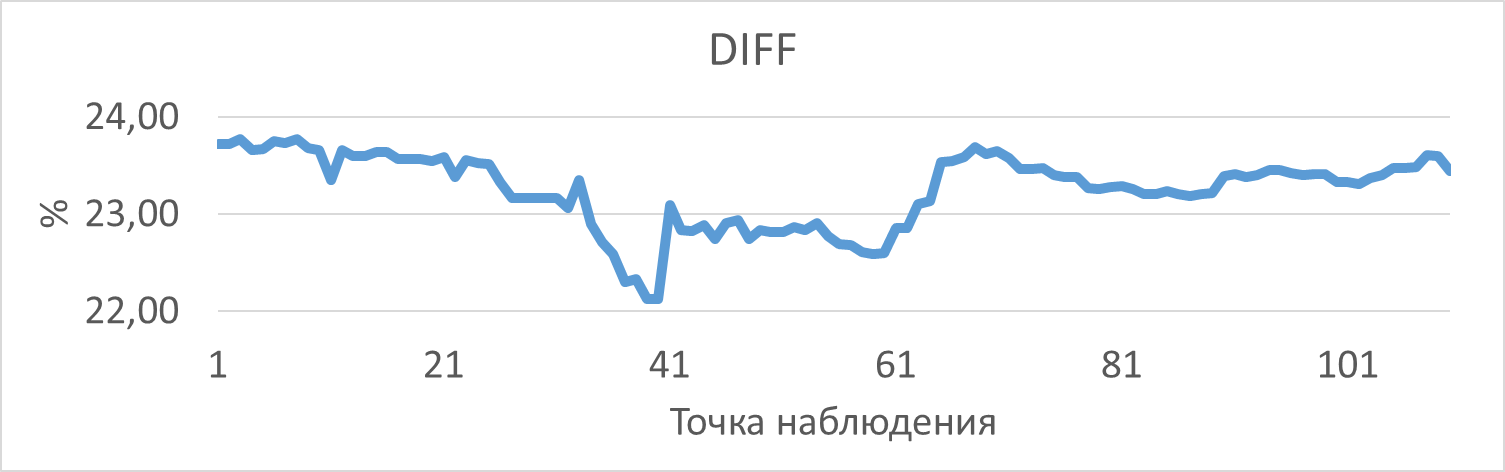
График изменения относительной разницы операционной скорости в ходе нагрузочного тестирования при использовании EXISTS по сравнению с IN
Среднее превышение операционной скорости при использовании EXISTS составило 23.25%.
Ожидания СУБД
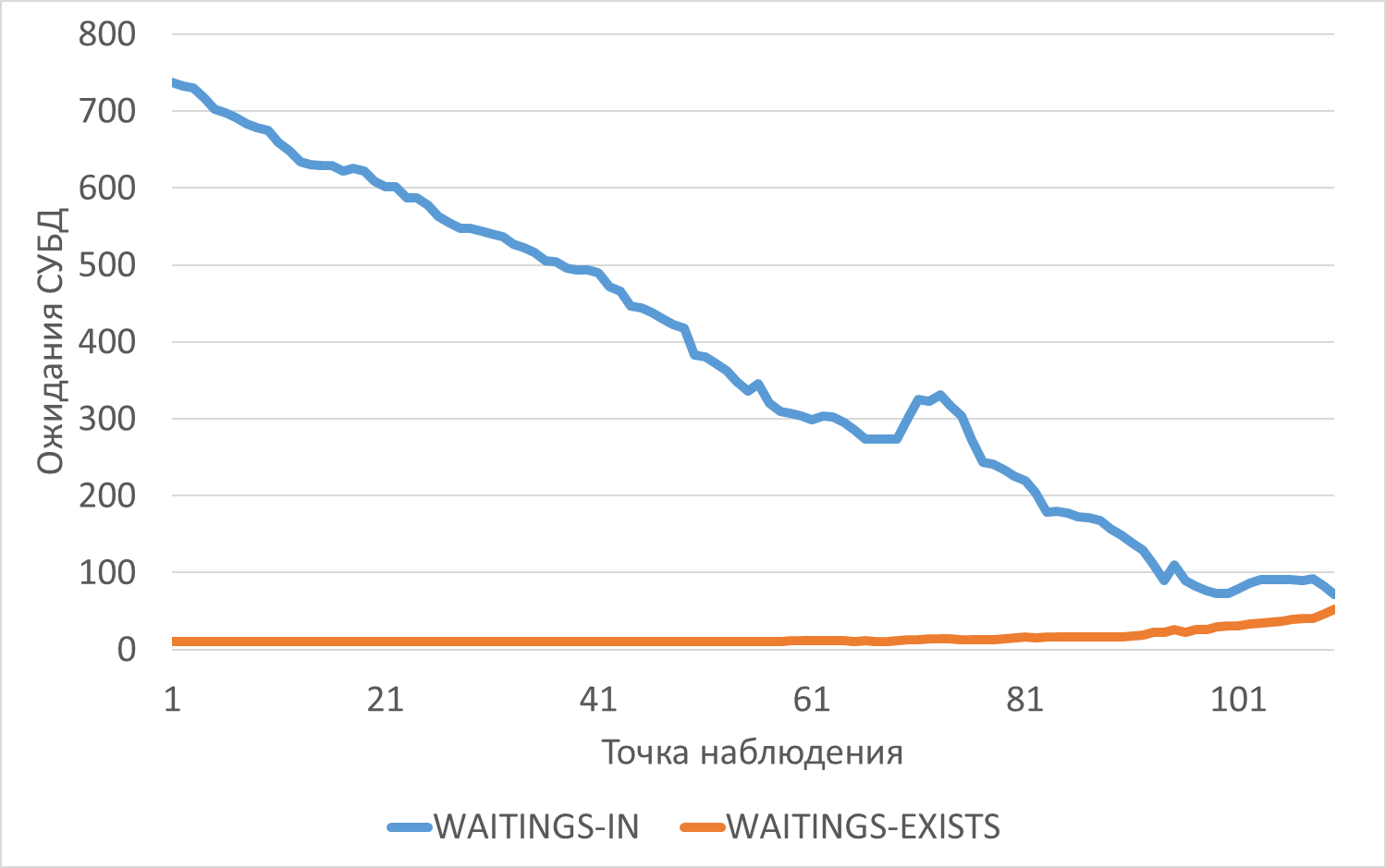
График изменения ожиданий СУБД в ходе нагрузочного тестирования
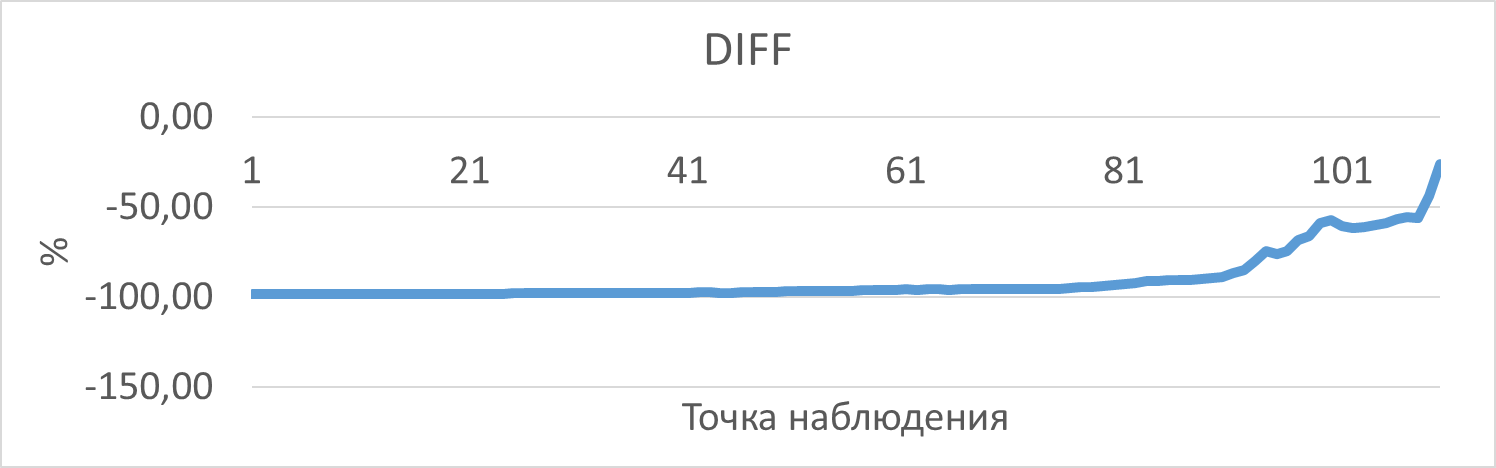
График изменения относительной разницы ожиданий СУБД в ходе нагрузочного тестирования при использовании EXISTS по сравнению с IN
Среднее снижение ожиданий СУБД при использовании EXISTS составило 90.60%.
Итог

Использование паттерна EXIST повышает производительность СУБД в среднем на 20%.
Postgres DBA
157 постов27 подписчиков
Правила сообщества
Пока действуют стандартные правила Пикабу.