

График частоты букв в русском языке
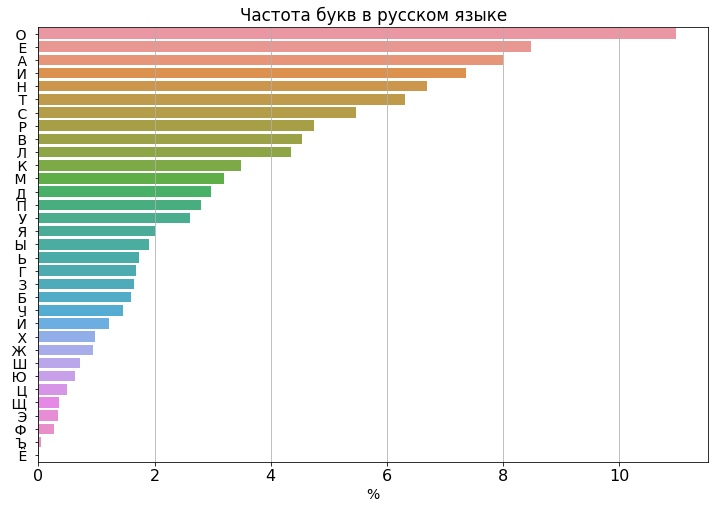
На первом месте – "О", она встречается в русскоязычных текстах чаще, чем 14 самых редких букв в сумме! Самая распространённая согласная – "Н", что для меня было неожиданно. А мягкий знак далеко не такой редкий, как я думал – он встречается чаще, чем целых 15 букв
На последнем месте грустит "Ё". Её нещадно вытесняет из письменности "Е", чтобы удержать своё второе место
Если вы читаете достаточно длинный текст, то его 50% составляют всего 7 букв!


