


Агрегатор контента своими руками. Попытка №2.
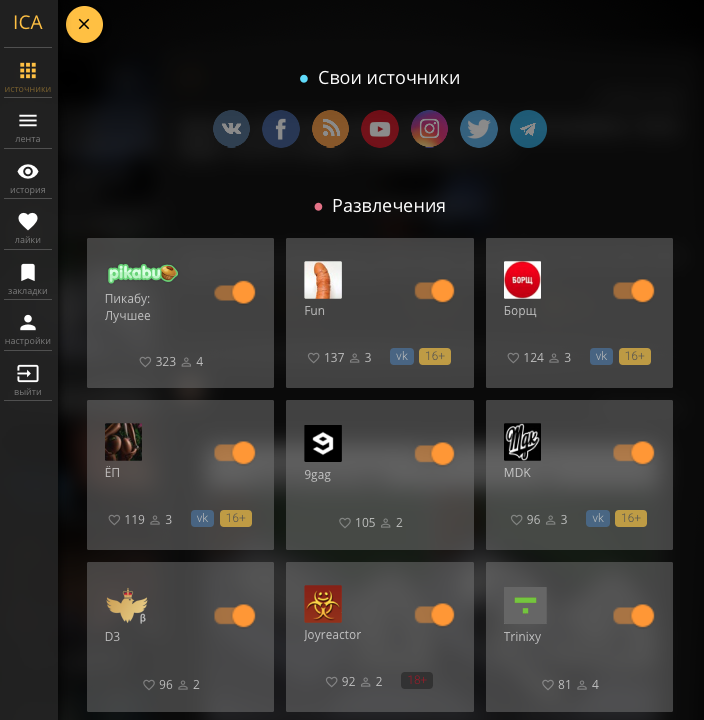
Привет моим верным подписчикам и лиге вэб разработчиков! В данном посте я поведаю о:
- паре забавных случаев, возникших при разработке новой версии моего агрегатора котиков и мемасиков (а так же новостей, видео, пабликов, групп, RSS и Telegram каналов );
- текущем состоянии дел и планах развития.
Около 800 дней назад я опубликовал первую версию агрегатора контента и сделал пост на пикабу. Сервис получился неплохим и мои цели удовлетворял. Я пользовался им каждый день, для просотра мемасиков и котеек. Но, к сожалению, большого интереса у пользователей не вызывал. А в комментариях знающие люди советовали весь функционал перенести на сервер, что бы на клиентских устройствах все работало максимально быстро.
Так как по своей натуре я перфекционист, то идея сделать все "красиво" не давала мне покоя и в 2017 году я наконец сдался и решился переписать все с 0, нанять хорошего дизайнера и выкатить ресурс который заткнет за пояс конкурентов :) Получилось ли у меня или это очередное фиаско, я надеюсь узнать сегодня, в комментариях к этому посту :)
Итак, начнем с пары интересных задач, которые пришлось решить при разработке.
1. Как я добавлял вывод телеграмм каналов.
В последний год появляется все больше популярных телеграм-каналов. Но лично мне не удобно читать их в приложении, хотя я не пробовал :). Я сразу запланировал, что в новой версии агрегатора обязательно должна быть возможность вывести в свою ленту посты из любых публичных телеграм-каналов вместе со всеми другими источниками.
Обилие инструкций по работе с телеграм-ботами воодушевляло и я рассчитывал, что задача не займет много времени. И еще я не понимал, почему никто не сделал аналогичного сервиса :)
Как это всегда бывает в разработке, препятствия возникли на ровном месте: оказалось, что для того, что бы бот мог читать какой-то канал, бота надо туда добавить. Поэтому вариант сразу отпал. И я перешел к чтению мануалов на основной API телеграма.
Через 30 минут изучения документации я был в отчаянии.
Все данные у телеграма шифруются, что бы получить что то от их серверов нужно обладать степенью магистра по криптографии... И, конечно, обычные http запросы - это не для них, только низкоуровневые socket, отдающие чистые байты, только хардкор. Вообщем без сторонней помощи задача была нерешаемая.
Несколько дней поиска привели меня к решению: использовать на сервере opensource php телеграм клиент. Дада! Можно использовать телеграм под php, и там даже есть поддержка звонков! Это чудо называется madelineProto и исходники доступны на гитхабе.
В итоге, через 3 дня настройки и две блокировки моего аккаунта из-за чрезмерного количества попыток авторизации я настроил клиент и решил задачу. Теперь у меня есть свой шлюз из telegram в web! А пользователи могут читать любые публичные телеграмм каналы у меня на сайте без регистрации и смс.
2. Парсинг youtube каналов.
С API youtube'a вообще вышло забавно. Их справка предлагает использовать php плагин от гугла для доступа к API. От их API мне нужно было не много: список видео на канале с метаданными, название канала и его логотип. У vk или fb такой запрос создается парой строчек кода и разобраться можно за пол часа.
Но у гугла свой путь разработки :)
Я смирился с тем, что плагин для доступа к API весит более 30 мегабайт. Но я еще и не смог настроить его за 3 часа!
В итоге, кликая на все подряд в справке гугла, оказалось, что плагин можно вообще не использовать, а для получения всей информации - воспользоваться стандартным get запросом, как везде. На формирование запроса мне понадобилось ровно 10 строк кода и 15 минут, вместо 30 мегабайтного плагина.
А потом люди удивляются: "а почему андройд притормаживает на 8-миядерных процессорах и требует 4 гигабайта оперативы?" ;)
3. Что сейчас с агрегатором?
Я запустил вторую версию пару недель назад, и уже выловил все критичные баги. Сейчас все работает стабильно и быстро. Сейчас надеюсь получить отклик от армии пикабу (хотя бы от небольшой ее части), узнать чего им не хватает и что нужно поправить.
4. Планы
- Добавить прямые ссылки на отдельные источники
- Расширять список источников: imgur, rutube, reddit, новостные сайты.
- Привлечь ядро активных пользователей, что бы были данные для формирования ленты популярных постов;
- Добавить в ленту вывод видео и гифок, что бы сократить число внешних переходов;
- Е-маил рассылки с лучшими постами за день/неделю (естественно при желании пользователя);
- Сотрудничество с создателями контента для совместного продвижения.
5. Техническая часть.
Для тех кому интересно то под капотом следующий стек технологий:
Backend: самописный, доставшийся мне в наследство на одном из проектов и переписаный мной под свои нужды. Используется шаблонизатор smarty.
БД: Mysql
Fron-end: HTML + Angular JS 1, так же используется Jquery 2 (в 3-й версии scroll события в firefox не работают периодически) для анимаций.
Парсинг осуществляю с помощью библиотеки php-query или через API раз в 5 минут по CRON'у в порядке живой очереди с приоритетом на публичные источники. Т.е. если за 4 минуты сайт не успел пройтись по всем источникам, то скрипт останавливается. А в следующий раз в начале очереди находятся те источники, которые дольше всего не обновлялись. Очереди для публичных и персональных источников разные - по 2 минуты и на те и на другие.
Если вас заинтересовал проект, то буду очень признателен за любые отзывы и комментарии. Ссылка (на пикабу, вроде, разрешено в конце поста давать ссылку): https://i-c-a.su/



Программирование на PHP
64 поста2K подписчика
Правила сообщества
- запрещено добавлять посты отличной от мира программирования тематики (так как пикабу - это в первую очередь развлекательный ресурс, то посты с юмором, историями, изображениями и всем, что связано с php - разрешены);
- запрещено добавлять посты с содержанием в виде вопроса, или просьбы о помощи, для этого есть тематические ресурсы;
- запрещено добавлять посты провакационной тематики, нацеленные на бессмысленные споры и оскарбления;
- в копипастах и переводах указывайте источники;