

Разоблачение решающих деревьев
В прошлом посту (е?) я рассказал, как вкратце работает такая штука, как решающее дерево, но был закидан помидорами, причем поделом. Итак, поехали.
Чем хороши решающие деревья?
Одно из преимуществ DT (decision tree) является способность аппроксимировать (то есть приближать, угадывать) функцию любой сложности, будь то прямая или логарифм в полиномиальной степени

Почему? Да потому что для любого значения мы можем поставить такие узкие условия, что функция будет приближена идеально.
Что еще отнести к плюсам? Очень высокая скорость обучения, получаем готовую модель через несколько миллисекунд даже при выборке из десятков тысяч элементов. Для сравнения, серьезная сетка может учиться несколько минут, а большой ансамбль сетей может обучаться десятки часов.
Что же с ними не так?
Способность аппроксимировать любую функцию ведет к переобучению, то есть мы настолько хорошо "срисовали" функцию на исходной выборке, что на тестовой (то есть той, на которой проводится объективная оценка модели) будет неведомая ерунда.
Также стоит отметить полное отсутствие возможности экстраполяции функции, то есть если
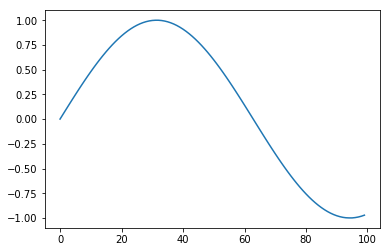
На диапазоне от 0 до 100, где мы и обучали, то если возьмем от -100 до 200, увидим...
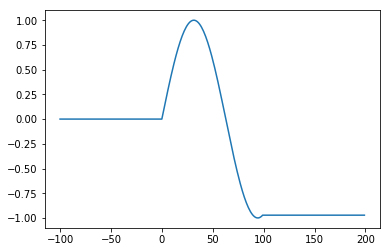
Кому они нужны?
Мне Для большинства простых задач на машинное обучение они подойдут, но есть некоторые условия применения деревьев, а именно: данные - не картинка, не последовательность информации (видео, музыка). Это именно набор чисел по разным параметрам (например, в классической задаче по ML - титанике - нам приведены такие данные как: пол, возраст, место в корабле и т. д.).
Такие дела :). Жду новых предложений, что рассказать дальше.
Искусственный интеллект
5.1K пост11.5K подписчиков
Правила сообщества
ВНИМАНИЕ! В сообществе запрещена публикация генеративного контента без детального описания промтов и процесса получения публикуемого результата.
Разрешено:
- Делиться вопросами, мыслями, гипотезами, юмором на эту тему.
- Делиться статьями, понятными большинству аудитории Пикабу.
- Делиться опытом создания моделей машинного обучения.
- Рассказывать, как работает та или иная фиговина в анализе данных.
- Век жить, век учиться.
Запрещено:
I) Невостребованный контент
I.1) Создавать контент, сложный для понимания. Такие посты уйдут в минуса лишь потому, что большинству неинтересно пробрасывать градиенты в каждом тензоре реккурентной сетки с AdaGrad оптимизатором.
I.2) Создавать контент на "олбанском языке" / нарочно игнорируя правила РЯ даже в шутку. Это ведет к нечитаемости контента.
I.3) Добавлять посты, которые содержат лишь генеративный контент или нейросетевой Арт без какой-то дополнительной полезной или интересной информации по теме, без промтов или описания методик создания и т.д.
II) Нетематический контент
II.1) Создавать контент, несвязанный с Data Science, математикой, программированием.
II.2) Создавать контент, входящий в противоречие существующей базе теорем математики. Например, "Земля плоская" или "Любое действительное число представимо в виде дроби двух целых".
II.3) Создавать контент, входящий в противоречие с правилами Пикабу.
III) Непотребный контент
III.1) Эротика, порнография (даже с NSFW).
III.2) Жесть.
За нарушение I - предупреждение
За нарушение II - предупреждение и перемещение поста в общую ленту
За нарушение III - бан