

Как мы классифицируем языки
Продолжаю рассказ на тему, поднятую в двух предыдущих постах. От родства языков переходим к классификации.
Люди обожают классификации. Если мы можем расчленить некоторое множество объектов на группы, наклеить на них ярлычки и рассовать по полочкам-ящичкам, это создаёт у нас ощущение, что мы разобрались в теме. При этом нельзя забывать, что классификации – архиполезная вещь, действительно позволяющая вникнуть в суть вещей, но почти всегда несущая элементы упрощения и условности.
Лингвистические классификации бывают двух основных видов – типологические и генеалогические. Типологические делят языки в соответствии с неким признаком языковой структуры. Например, по базовому порядку слов в предложении (S – субъект, V – глагол, O – объект) можно выделить 7 возможных вариантов.
1. SVO: охотник убил утку.
2. SOV: охотник утку убил.
3. OVS: утку убил охотник.
4. OSV: утку охотник убил.
5. VSO: убил охотник утку.
6. VOS: убил утку охотник.
7. Нет доминирующего порядка слов.
Базовые порядки слов в языках Восточного полушария по данным Всемирного атласа языковых структур. Красным цветом – SVO, синим – SOV.
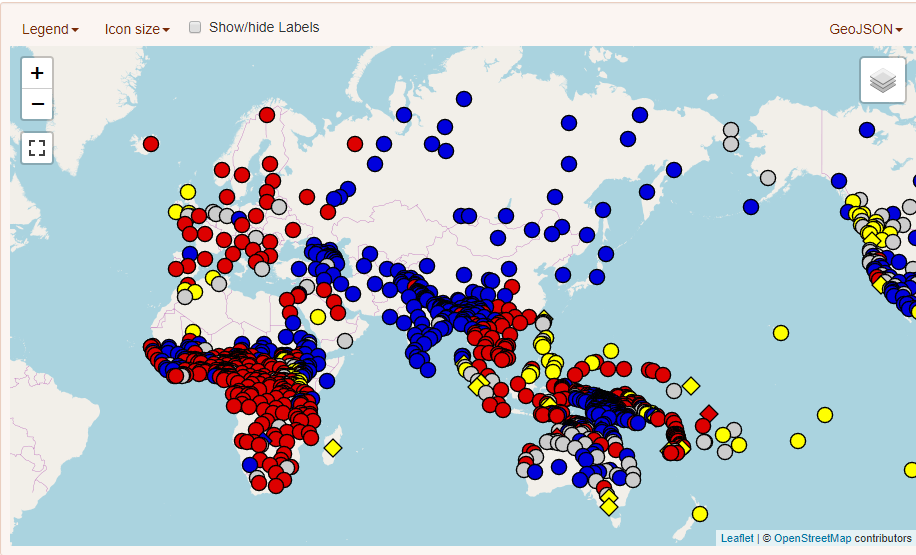
Генеалогические классификации, как несложно догадаться, делят языки в соответствии с их происхождением. В сравнительно-историческом языкознании традиционно используются два способа визуально представить классификацию: древесная модель и волновая модель.
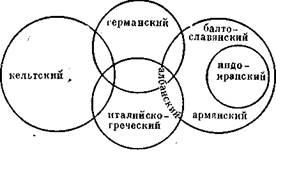
Древесную модель популяризировал немецкий учёный Август Шлейхер. Вот так выглядело его генеалогическое древо индоевропейских языков (разумеется, наши представления о структуре индоевропейской языковой семьи с тех пор давно ушли вперёд):
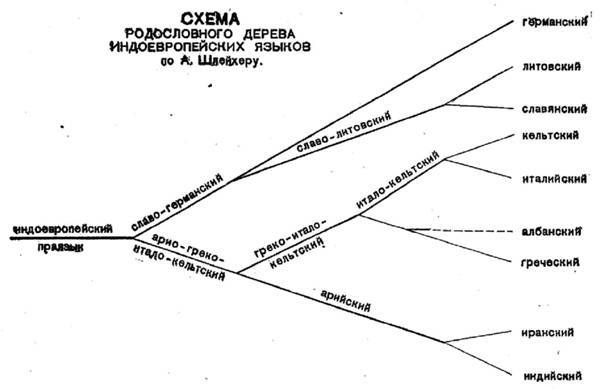
Достоинством древесной модели является то, что она интуитивно понятна, ведь по сути, здесь использована схема семьи: Авраам родил Исаака, Исаак родил Иакова, праиндоевропейский родил праславянский, праславянский родил древнерусский, древнерусский родил русский. Кроме того, модель древа позволяет отражать время существования каждого праязыка: чем веточка на древе длиннее, тем период общности был дольше.
Недостатком этой модели является то, что она хороша при описании дискретных объектов. Например, при следующем историческом сценарии: носители языка А заселяют два далеко расположенных друг от друга острова, две тысячи лет живут, не контактируя друг с другом, и их языки (B и C) утрачивают взаимопонятность. После чего носители языков B и C полностью покидают родные острова и заселяют острова D, E, F и G, где вновь живут в полной изоляции.
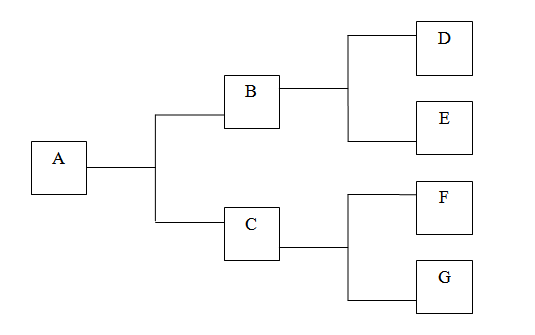
В реальности, естественно, так бывает редко. И тут нам необходимо понятие континуума. Континуум в лингвистике бывает «вертикальным» и «горизонтальным». О первом я уже писал в предыдущем посте. Речь о том, что когда язык передаётся из поколения в поколение, это происходит без резких переходов, и разница ощутима лишь на больших интервалах. Поэтому, когда мы выделяет периоды в истории языка (современный русский, старорусский, древнерусский и т.д.), это в значительной степени условность.
Под «горизонтальным» континуумом я имею в виду континуум диалектный. Представим, что носители некоего языка приходят в гористую местность и заселяют пять долин (A, B, C, D, E), тянущихся по цепочке. Спустя некоторое время жители долины A будут довольно хорошо понимать жителей долины B, несколько хуже C, плохо D и вообще не будет понимать выходцев из долины E.
Выглядеть это будет так (цветными овалами обозначены различные языковые изменения, каждое из которых охватывает лишь часть континуума):
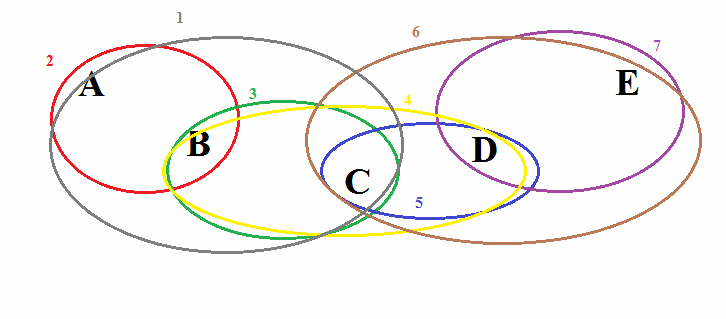
В этом случае нам будет довольно сложно нарисовать генеалогическое древо этих языков, да и вообще определить, сколько здесь языков, и где проходит граница между ними. Конкретный пример. Допустим, мы хотим классифицировать восточнославянские диалекты. Возьмём два фонетических явления – аканье (произношение гора как гара) и цеканье (произношение кость как косць). Если брать только литературные украинский и белорусский, то между ними проходит довольно чёткая граница, и создаётся впечатление, что восточнославянские языки делятся на две группы – одна акает и цекает, а другая нет.
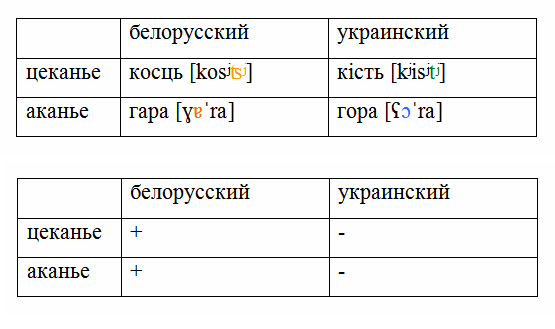
Но если мы привлечём данные литературного русского, а также говоров окрестностей Турова, то получится, что никакой чёткой классификации только на этих двух чертах мы не построим.
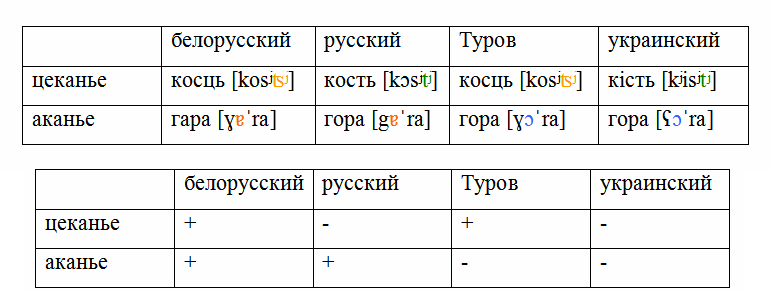
Подобные факты заставили ещё одного немецкого лингвиста, Иоганнеса Шмидта, разработать волновую модель, в которой, в отличие от древесной, нет жёсткой установки на разделение языков.
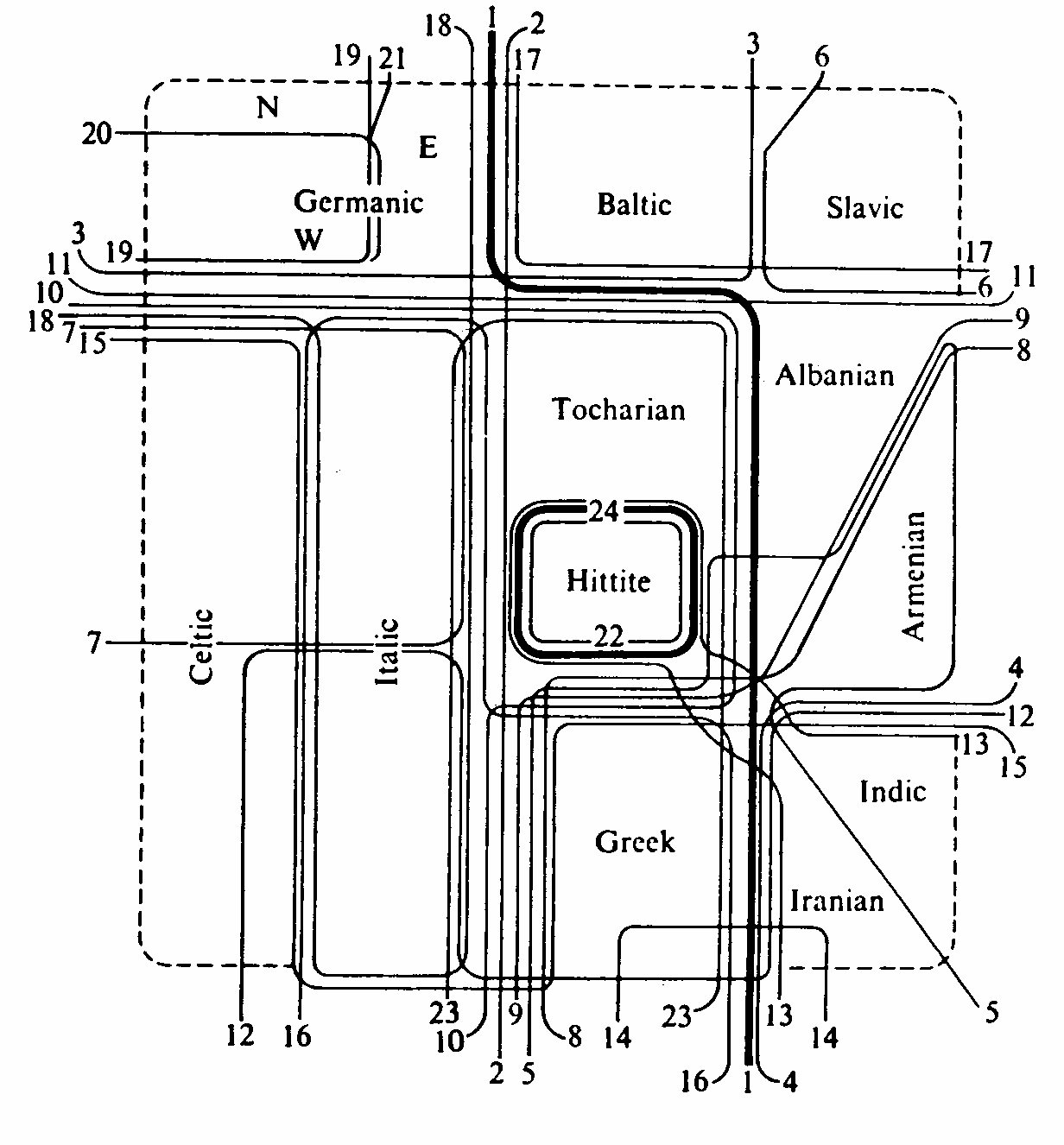
Вот так выглядит современная классификация индоевропейских языков в виде волновой модели (автор – Р. Анттила). Каждая линия – это языковое изменение, разделяющее языки.
Есть высказывание А. Б. Долгопольского о том, что у всех языков есть генеалогические деревья, а у тюркских – генеалогический пень. Связано это с тем, что тюркские языки – большой диалектный континуум, который очень сложно представить виде древа. Впрочем, это проблема не только тюркских, но и славянских, романских и многих других языков.
Классификация романских языков в виде волновой модели (автор схемы - Ю.Б. Коряков):
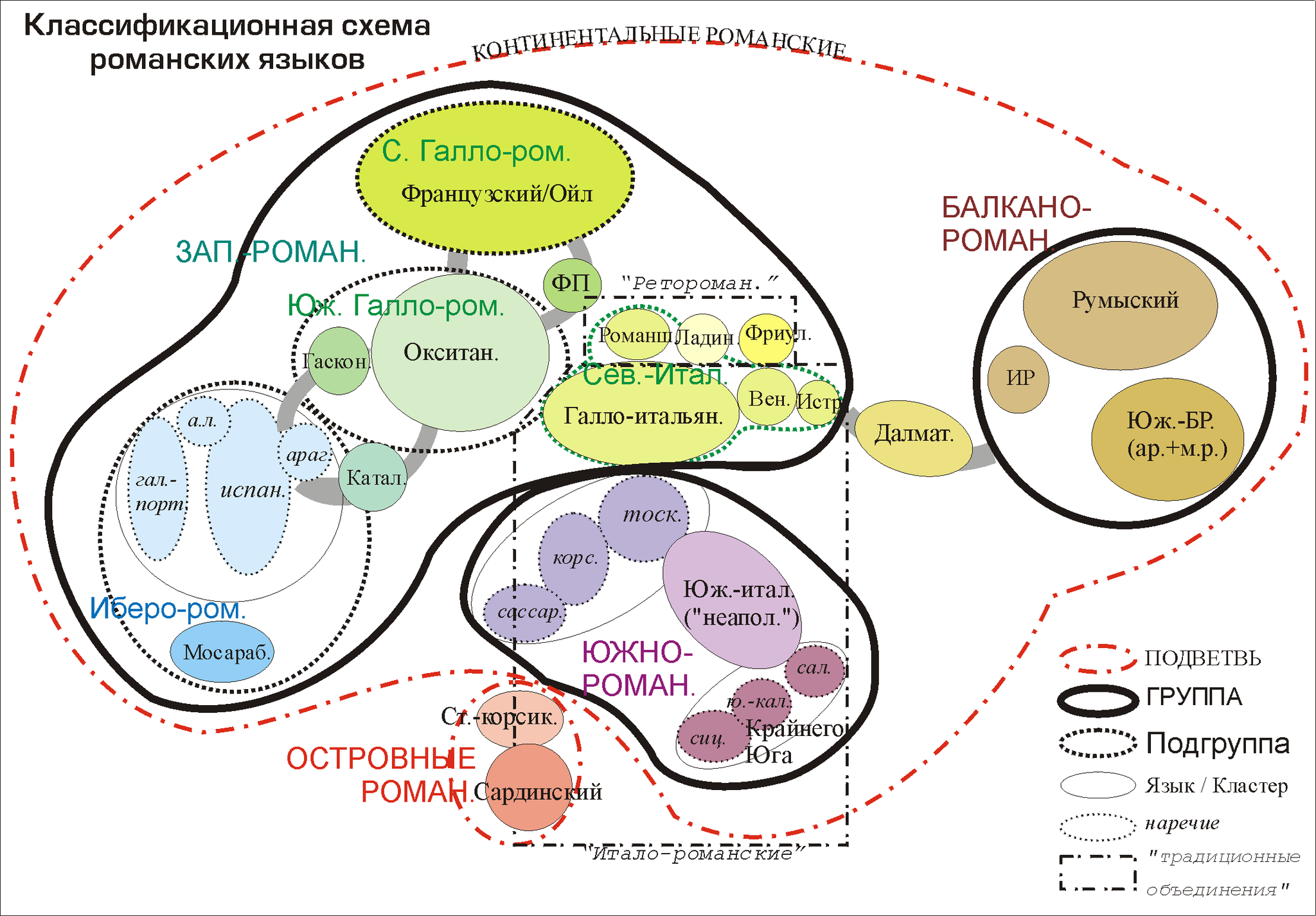
Недостатками волновой модели является отсутствие временной шкалы, а также меньшая по сравнению с древесной интуитивная понятность.
В последнее время лингвисты поглядывают в сторону других моделей классификации, которые в ходу у биологов. Биологи активно пользуются различным софтом, который помогает им строить деревья и сети. Однако в эти же программы можно загнать и лингвистические данные. Например, вот так выглядит модель филогенетической сети NeighborNet в применении к лингвистическому материалу (германские диалекты):
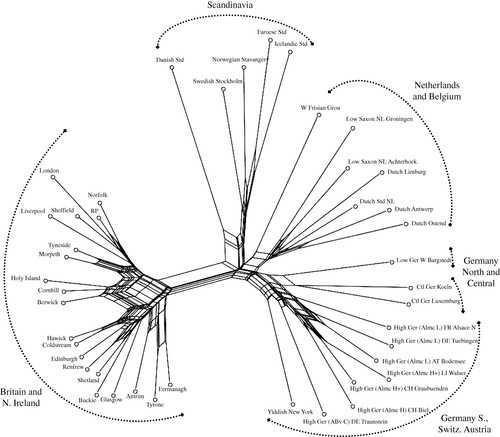
Существуют и попытки как-то улучшить модель древа, но на настоящее время самой распространённой схемой классификации в силу своей простоты и удобства остаётся классическая древесная.
Базовый таксон в генеалогической классификации – это семья. Семьи обычно дробят на группы, а группы могут разделить на подгруппы. С другой стороны, если согласно некой гипотезе несколько семей восходят к одному предку, их можно объединить в один крупный таксон, и это уже называется макросемьёй. Допустим, «прописка» русского языка в генеалогической классификации выглядит следующим образом:
[Макросемья: ностратическая (с этим согласны не все учёные)];
Семья: индоевропейская;
[Группа: балто-славянская (с этим согласны не все учёные)];
Группа: славянская;
Подгруппа: восточнославянская.
Всего мире насчитывается несколько сотен семей и изолятов (языков, не попавших ни в одну семью). Наиболее популярные проекты, собирающие и систематизирующие данные по языкам мира – это Этнолог и Глоттолог (по ссылкам можно посмотреть использующиеся в них классификации).
А вот самые крупные языковые семьи мира на карте Ю.Б. Корякова:
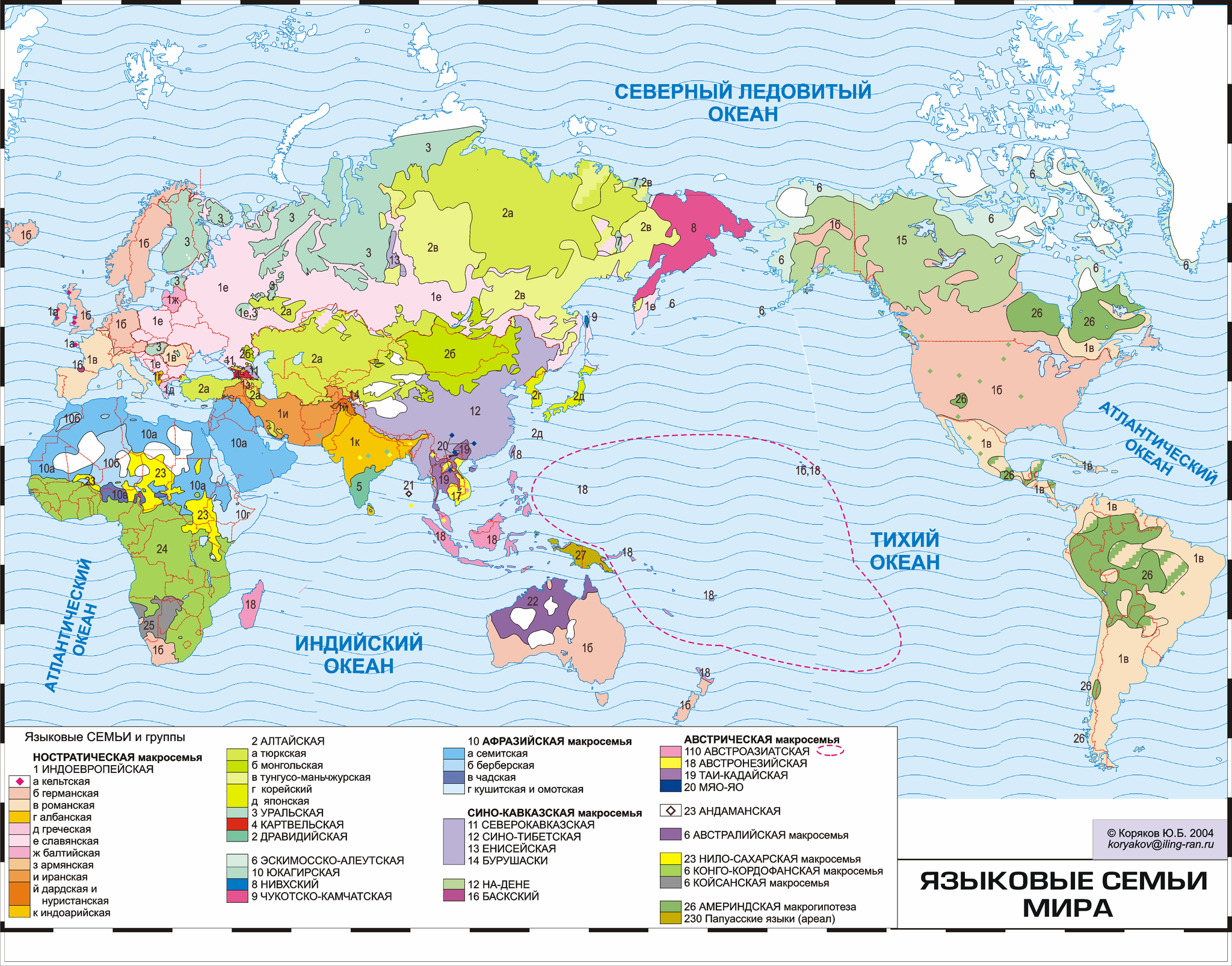
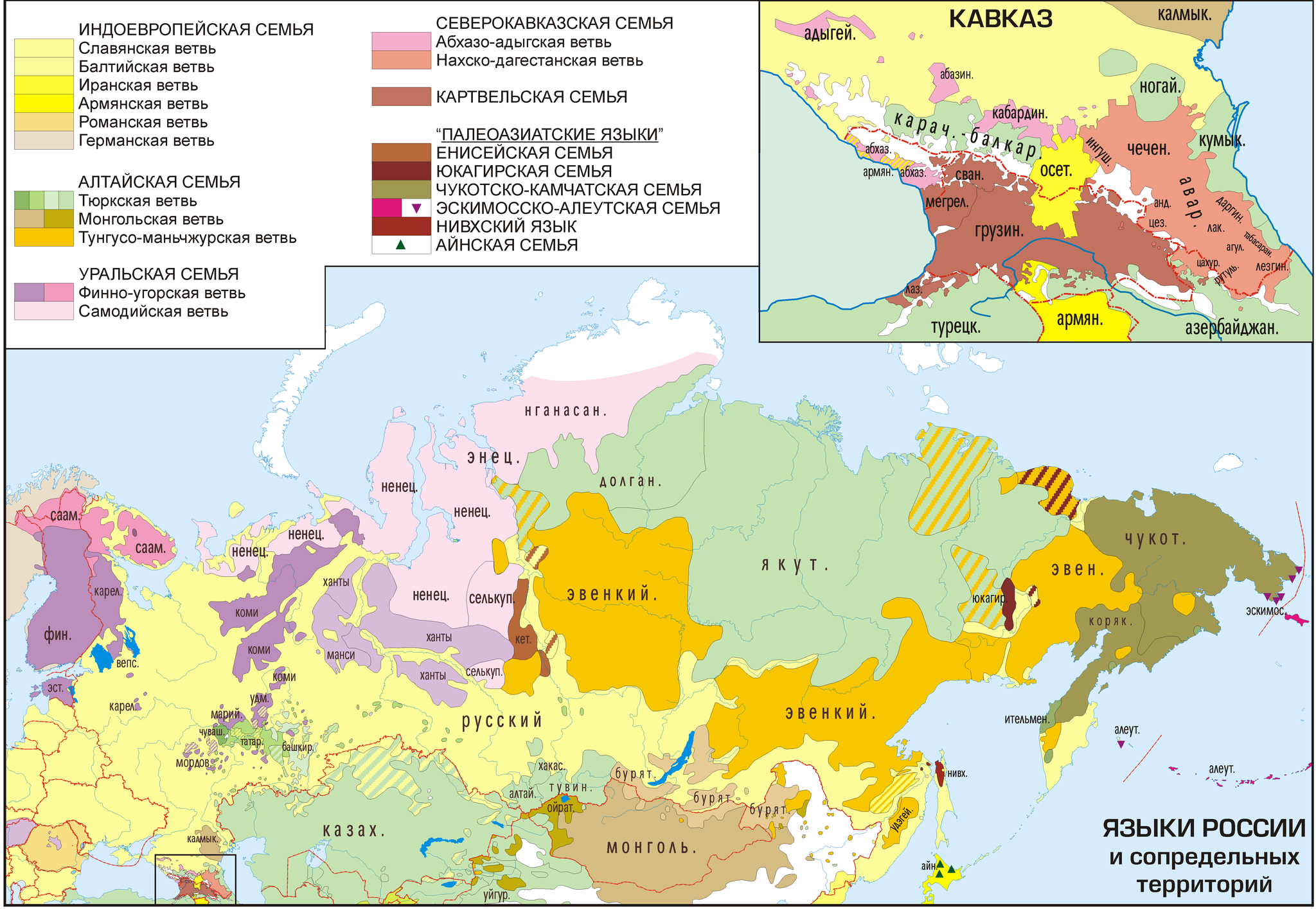
Конечно, генеалогическая классификация языков – тема необъятная, и я лишь пробежался по верхам. Надеюсь, руки дойдут написать о классификациях славянских языков, ностратической гипотезе, проблеме язык/диалект, взаимопонятности языков, лингвогеография и многих других темах.
А пока, если вам хочется узнать больше, рекомендую прочитать вот эти две книжки:
Бурлак С.А., Старостин С.А. Сравнительно-историческое языкознание [университетский учебник].
Старостин Г.С. К истокам языкового разнообразия [научпоп в виде бесед Е.Я. Сатановского с лингвистами].
Наука | Научпоп
9.2K постов82.6K подписчиков
Правила сообщества
Основные условия публикации
- Посты должны иметь отношение к науке, актуальным открытиям или жизни научного сообщества и содержать ссылки на авторитетный источник.
- Посты должны по возможности избегать кликбейта и броских фраз, вводящих в заблуждение.
- Научные статьи должны сопровождаться описанием исследования, доступным на популярном уровне. Слишком профессиональный материал может быть отклонён.
- Видеоматериалы должны иметь описание.
- Названия должны отражать суть исследования.
- Если пост содержит материал, оригинал которого написан или снят на иностранном языке, русская версия должна содержать все основные положения.
- Посты-ответы также должны самостоятельно (без привязки к оригинальному посту) удовлетворять всем вышеперечисленным условиям.
Не принимаются к публикации
- Точные или урезанные копии журнальных и газетных статей. Посты о последних достижениях науки должны содержать ваш разъясняющий комментарий или представлять обзоры нескольких статей.
- Юмористические посты, представляющие также точные и урезанные копии из популярных источников, цитаты сборников. Научный юмор приветствуется, но должен публиковаться большими порциями, а не набивать рейтинг единичными цитатами огромного сборника.
- Посты с вопросами околонаучного, но базового уровня, просьбы о помощи в решении задач и проведении исследований отправляются в общую ленту. По возможности модерация сообщества даст свой ответ.
Наказывается баном
- Оскорбления, выраженные лично пользователю или категории пользователей.
- Попытки использовать сообщество для рекламы.
- Фальсификация фактов.
- Многократные попытки публикации материалов, не удовлетворяющих правилам.
- Троллинг, флейм.
- Нарушение правил сайта в целом.
Окончательное решение по соответствию поста или комментария правилам принимается модерацией сообщества. Просьбы о разбане и жалобы на модерацию принимает администратор сообщества. Жалобы на администратора принимает и общество Пикабу.