

EXCEL для чайников.3.текст
Доброго времени суток, пикабушнички! Предлагаю продолжить работу по осёдлыванию могучего скакуна, по кличке Excel. Это мой третий пост. В предыдущих мы говорили о функциях времени EXCEL для чайников.2.Время и ВПР EXCEL для чайников.1.ВПР , этот же пост будет про работу с текстом. Некоторые сейчас подумают: «Что? Зачем работать с текстом в экселе, если есть ворд?» или даже «Ворд - для текста, ексель - для таблиц!». Однако, глупо отрицать, что бывают такие ситуации, когда текст нужен в таблице. И, выбирая между работой с таблицей в ворде и работой с текстом в екселе, вы вряд ли выберете первое. А если выберете… храни вас Бог.
Итак, сегодня мы поговорим про обработку текста в таблицах. Сразу отмечу, что у некоторых функций работы с текстом имеется дублер для работы с иероглифами, например функция ДЛСТР имеет восточного дублера ДЛИНБ. Однако, за неимением у автора достаточных знаний о соответствующих иностранных языках, рассматривать работу с иероглифами не будем.
Вот краткий перечень основных функций по работе с текстом (если ты не любишь подобное занудство - мотай до таблицы):
ДЛСТР(текст) – выдает длину строки (количество символов)
ЛЕВСИМВ(текст, [число_знаков]) – «отрубаем» нужное количество знаков слева
ПРАВСИМВ(текст,[число_знаков]) – «отрубаем» нужное количество знаков справа
ПСТР(текст, нач_позиция, число_знаков) – «вырубаем» нужное слово или несколько из текстовой ячейки
ПРОПИСН(текст) - ДЕЛАЕТ ВЕСЬ ТЕКСТ ПРОПИСНЫМ (для любителей КАПСА!)
ПРОПНАЧ(текст) - Делает Первые Буквы Слов Прописными
СТРОЧН(текст) – все буковки маленькие
ЗНАЧЕН(текст)- преобразует текст в числовое значение (полезно если откуда-то достались числа, сохраненные как текст, с которыми нельзя совершать математические действия)
ТЕКСТ(значение, формат) преобразует значение ячейки в текст нужного нам формата
СЖПРОБЕЛЫ(текст)- удаляет «ненужные» пробелы
ПЕЧСИМВ(текст)- убирает непечатные символы
КОДСИМВ(текст)- показывает код символа ANSI если это вам о чем то говорит (если символов несколько то код первого символа)
СИМВОЛ(число) пишет символ по его коду (это как КОДСИМВ наоборот)
ПОВТОР(текст, число_повторений) – повторяет текст нужное количество раз
СЦЕПИТЬ(текст1, [текст2], ...) сцепляет несколько текстовых ячеек в одну (вместо этой функции я предпочитаю использовать символ &, который аналогичен ей)
НАЙТИ(искомый_текст, просматриваемый_текст, [нач_позиция])ищем определенный текст в ячейках, результатом будет порядковый номер первого символа исходного текста (ниже будут примеры)
ПОИСК(искомый_текст, просматриваемый_текст,[нач_позиция])то же что и НАЙТИ но без учета регистра
ЗАМЕНИТЬ(стар_текст, нач_позиция, число_знаков, нов_текст) заменяет кусочек текста ячейки на другой
ПОДСТАВИТЬ(текст, стар_текст, нов_текст, [номер_вхождения]) заменяет одну часть текста на другую в нужном «вхождении» (терпение, примеры ниже)
СОВПАД(текст1, текст2) – сравнивает две ячейки на предмет их тождественности
T(значение)- если эта функция ссылается на текст, то возвращает его, если нет, то возвращает пустое место
РУБЛЬ(число, [число_знаков]) переводит число в денежный формат (с нужным округлением)
ФИКСИРОВАННЫЙ(число, [число_знаков], [без_разделителей]) – округляем число и преобразовываем его в текст (разделители это такие пробелы между тысячами, миллионами и т.д., чтобы число лучше читалось.
Пример работы всех описанных функций:
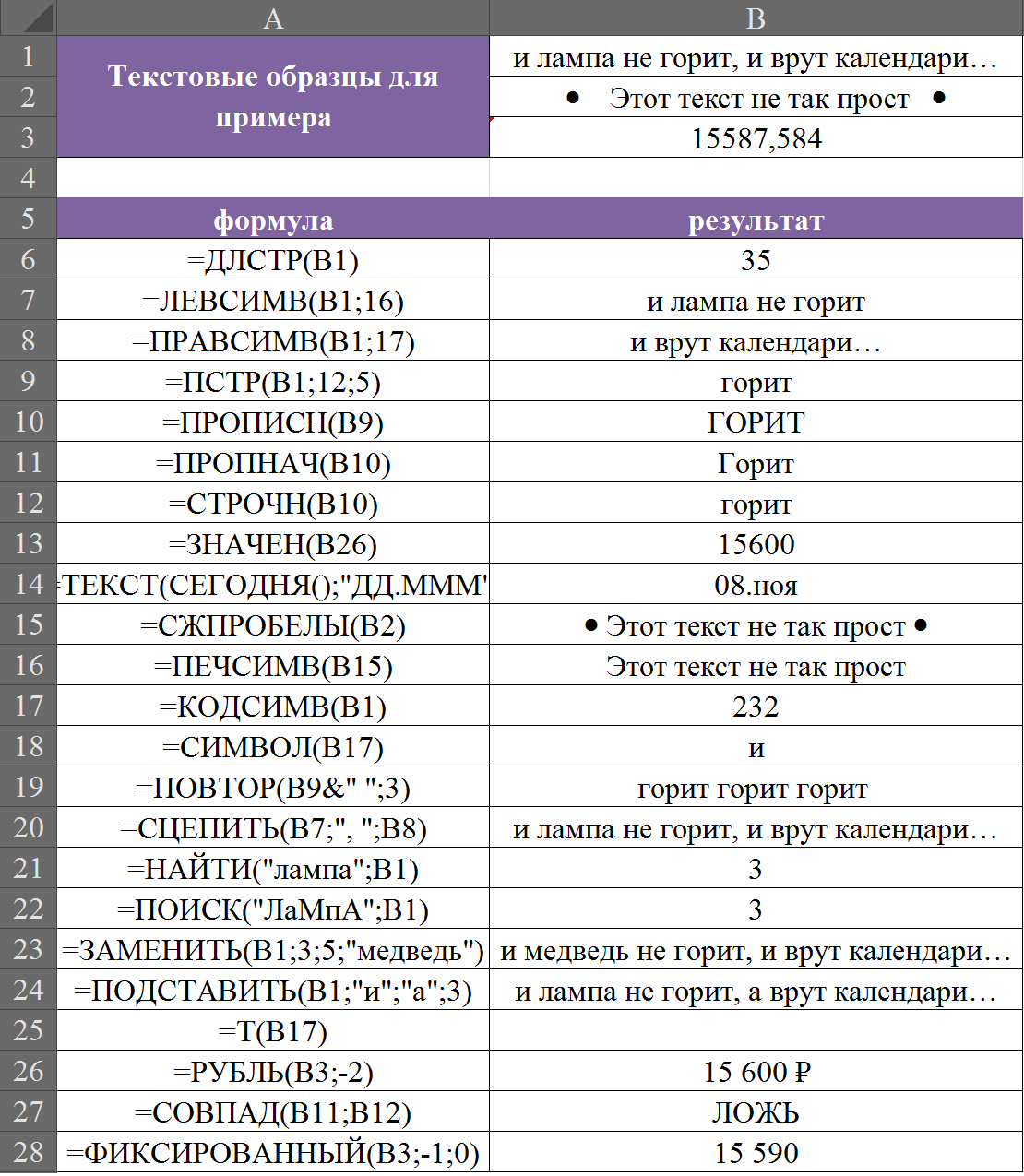
Комментарии к таблице в общем-то излишни, думаю все вполне наглядно. Поясню пару моментов:
1. Округление в функциях РУБЛЬ и ФИКСИРОВАННЫЙ я нарочно делал отрицательным, чтобы показать, что так можно, в этом случае округление идет до десятков (-1), сотен(-2), и т.д. Этот прием работает и с обычными округлениями ОКРУГЛ, ОКРУГЛВВЕРХ, ОКРУГЛВНИЗ при разложении числа на десятки, сотни и т.д.
2. Число в ячейке В3 сохранено как текст, поэтому с ним нельзя будет выполнять каких либо арифметических действий пока мы не переведем его в значение, по сути функции ЗНАЧЕН(), РУБЛЬ() и ФИКСИРОВАННЫЙ() делают одно и тоже, только две последних меняют еще и формат ячейки.
Подробнее о форматах расскажу в следующий раз.
А здесь хотелось бы рассмотреть небольшой пример для закрепления. Чтобы не нагромождать множество функций в примере рассмотрим несколько из них. Допустим у нас есть ячейки с ФИО, нам нужно разделить фамилии, имена и отчества в разных ячейках. Затем соединим фамилию и инициалы имени отчества сокращенно, а в последней ячейке проверим, действительно ли у нас написана фамилия.
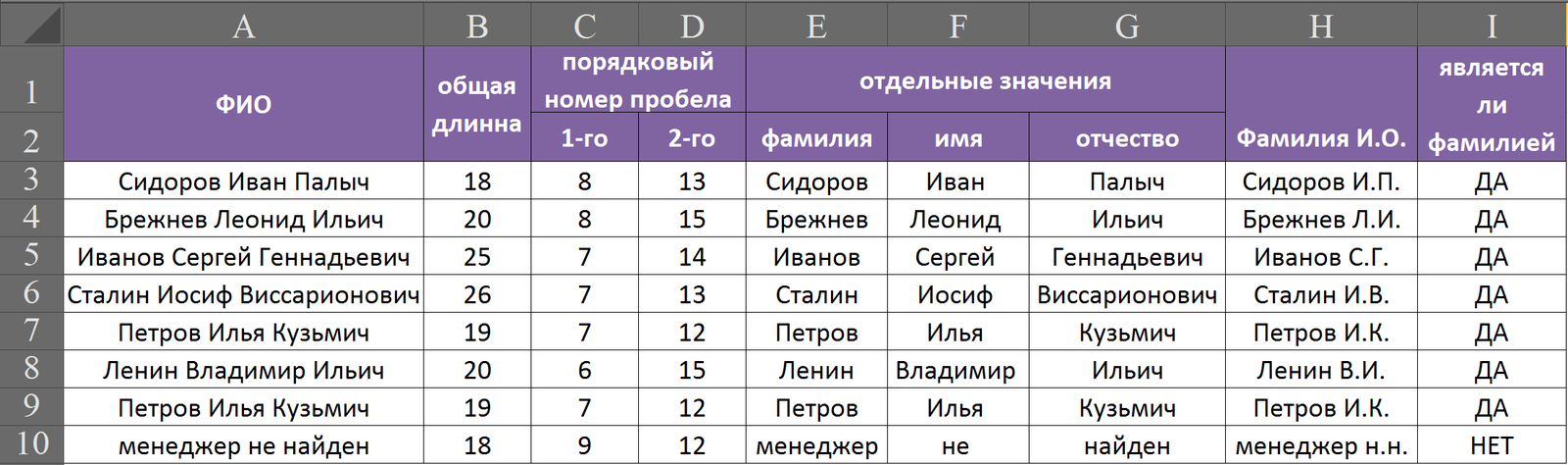
теперь посмотрим какие формулы прописаны у нас в столбцах В-Н:
столбец В: =ДЛСТР(A3) – находим длину текстовой ячейки в столбце А;
столбец С: =ПОИСК(" ";A3;1) – ищем первый пробел, начиная с первого символа;
столбец D: =ПОИСК(" ";A3;C3+1) – ищем второй пробел, начиная со следующего символа после первого пробела, найденного ранее;
столбец Е: =ЛЕВСИМВ(A3;C3-1) – отрезаем фамилию, отрезая заодно один символ пробела;
столбец F: =ПСТР(A3;C3+1;D3-C3) – вырезаем имя из середины, от первого пробела на длину имени, равную разности позиций первого и второго пробела;
столбец G: =ПРАВСИМВ(A3;B3-D3) – отрезаем отчество, длина которого равняется разности позиции второго пробела и общей длинны текстовой ячейки;
столбец Н: =СЦЕПИТЬ(E3;" ";ЛЕВСИМВ(F3;1);".";ЛЕВСИМВ(G3;1);".") – набираем фамилию и первые буквы имени и отчества, разделяя их пробелом и точками;
столбец I: =ЕСЛИ(СОВПАД(E3;ПРОПНАЧ(E3));"ДА";"НЕТ") – проверяем совпадают ли значения ячейки с фамилией и такой же ячейки проведенной через функцию ПРОПНАЧ, которая делает заглавной первую букву, иными словами проверяем является ли в ячейке с фамилией первая буква заглавная а остальные строчные. Если является, то пишем «ДА»; если нет то «НЕТ».
На этом пока все, буду фантазировать над темой следующего поста…
MS, Libreoffice & Google docs
782 поста15K подписчиков
Правила сообщества
1. Не нарушать правила Пикабу
2. Публиковать посты соответствующие тематике сообщества
3. Проявлять уважение к пользователям
4. Не допускается публикация постов с вопросами, ответы на которые легко найти с помощью любого поискового сайта.
По интересующим вопросам можно обратиться к автору поста схожей тематики, либо к пользователям в комментариях
Важно - сообщество призвано помочь, а не постебаться над постами авторов! Помните, не все обладают 100 процентными знаниями и навыками работы с Office. Хотя вы и можете написать, что вы знали об описываемом приёме раньше, пост неинтересный и т.п. и т.д., просьба воздержаться от подобных комментариев, вместо этого предложите способ лучше, либо дополните его своей полезной информацией и вам будут благодарны пользователи.
Утверждения вроде "пост - отстой", это оскорбление автора и будет наказываться баном.